引入 import spark.implicits._
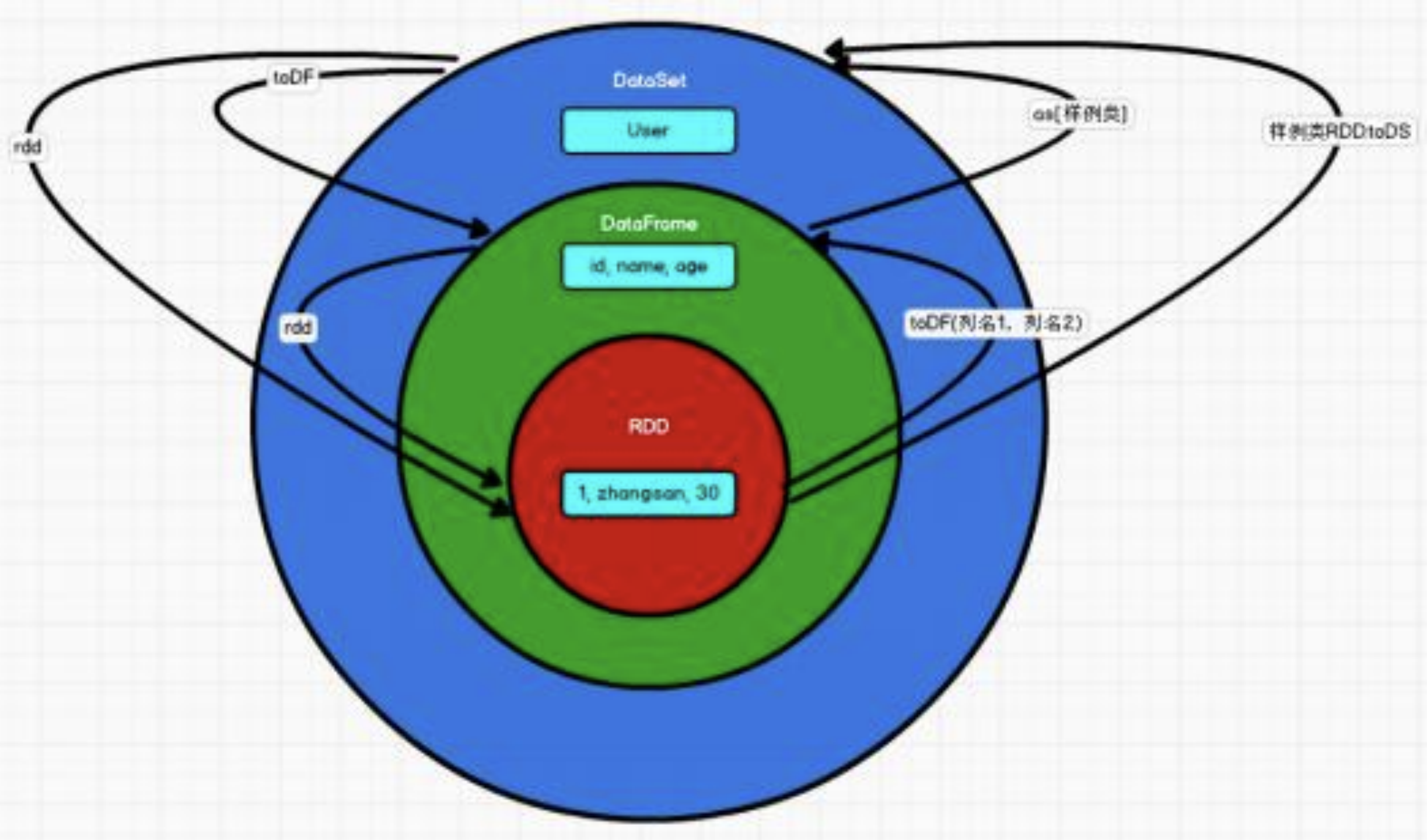
一 RDD和DataFrame
1.1 RDD 转换为 DataFrame
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
scala> case class User(name:String, age:Int)defined class Userscala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,t._2)).toDF.show+--------+---+| name|age|+--------+---+|zhangsan| 30|| lisi| 40|+--------+---+
1.2 DataFrame 转换为 RDD
scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDFdf: org.apache.spark.sql.DataFrame = [name: string, age: int]scala> val rdd = df.rddrdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[46]at rdd at <console>:25
注意:此时得到的 RDD 存储类型为 Row
二 RDD和DataSet
2.1 RDD 转换为 DataSet
scala> case class User(name:String, age:Int)defined class Userscala> sc.makeRDD(List( ("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDSres11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
2.2 DataSet 转换为 RDD
scala> case class User(name:String, age:Int)defined class Userscala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDSres11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]scala> val rdd = res11.rddrdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[51] at rdd at <console>:25scala> rdd.collectres12: Array[User] = Array(User(zhangsan,30), User(lisi,49))
注意:DataSet 其实也是对RDD 的封装,所以可以直接获取内部的RDD
三 DataFrame 和 DataSet
3.1 DataFrame 转换为 DataSet
scala> case class User(name:String, age:Int)defined class Userscala> val df = sc.makeRDD(List(("zhangsan",30),("lisi",49))).toDF("name","age")df: org.apache.spark.sql.DataFrame = [name: string, age: int]scala> val ds = df.as[User]ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
3.2 DataSet 转换为 DataFrame
scala> val ds = df.as[User]ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]scala> val df = ds.toDFdf: org.apache.spark.sql.DataFrame = [name: string, age: int]

若有收获,就点个赞吧
0 人点赞
