Mysql篇
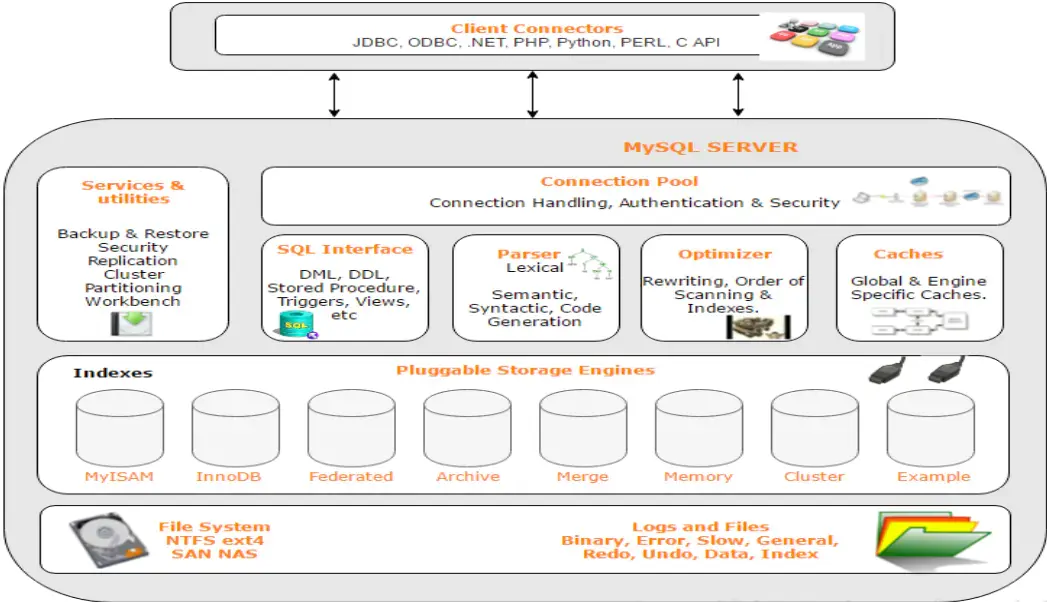
- Mysql架构组成有哪些?
- Mysql的查询具体流程?
客户端请求—>
连接器(验证用户身份,授权)—>查询缓存(存在则直接返回,不存在继续执行)—>分析器(对sql进行词法分析和语法分析操作)—>优化器(对sql优化选择最佳方案)—>执行器(查看用户是否有执行权限,有则去使用引擎提供的接口)—>去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)
- Mysql存储引擎
3.1什么是存储引擎?2.1 B+Tree和B-Tree的区别
B+Tree是B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构
- 非叶子节点只存储键值信息
- 所有叶子节点之间都有一个链指针
- 数据记录都存放在叶子节点中
存储引擎是Mysql的组件,用于处理不同类型的操作。一个数据库中多个表可以使用不同引擎满足各种性能和实际要求。
3.2 mysql有哪些存储引擎?
常见的存储引擎有InnoDb、MylSAM、Memory、NDB
Innodb现在是Mysql默认存储引擎,支持行级事物、行级锁定和外键
3.3 InnoDB和MylSAM的区别
3.3.1. InnoDB支持事物,MyISAM不支持事物。
3.3.2. InnoDB支持外键,MyISAM不支持。
3.3.3 InnoDB是聚簇索引,MySAM是非聚簇索引。聚簇索引的文件存放在主键索引的叶子节点上,所以Innodb必须要主键。
3.3.4 InnoDB不保存具体行数,所以select count(1)的时候在Innodb当中是全表扫描。Myisam用一个变量保存了整个表的行数,所以读取的时候直接读取变量即可.
3.3.5 Innodb最小的力度是行锁,Myisam最小的粒度是表锁。一个更新一句会锁住整张表,导致其他查询可能会被阻塞,并发受限。
######3. select count(*) from table 哪个引擎查询更快?
MyIsam查询更快,因为myisam直接读取变量则可,不需要全表扫描.Innodb是全表扫描一行一行累加,获取总数量
###Mysql 索引篇1. Mysql索引有什么作用?
优势:
提高数据检索效率,降低数据库IO的成本
降低数据排序的成本,降低CPU的消耗
劣势:
索引也会占用内存。
索引提高查询效率,同时会降低更新表的速度。2. Mysql索引分类
数据结构角度
- B+树索引
- Hash索引
- Full-Text全文索引
- R-Tree索引
物理存储角度
聚集索引
非聚集索引
聚集索引和非聚集索引都是B+Tree结构B-tree有以下特性:
1、关键字集合分布在整棵树中;
2、任何一个关键字出现且只出现在一个结点中;
3、搜索有可能在非叶子结点结束;
4、其搜索性能等价于在关键字全集内做一次二分查找;
5、自动层次控制;MyISAM引擎的叶子节点的数据域,存放的不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离的叫做非聚簇索引。
InnoDB引擎的叶子节点的数据与,存放的就是实际的数据记录,Innodb的数据文件本身就是主键索引文件,这被称为聚簇索引
2.2 哪些情况需要建立索引?count(*) count(1) count(column)的区别?
1.主键自动建立唯一索引
2. 频繁作为查询条件的字段。
3.查询中与其他表关联的字段 外键索引
4.单键/组合索引的选择问题,高并发情况下倾向组合索引
5. 查询中排序的字段,排序字段通过索引访问大幅提高排序速度
6. 查询中统计或分组字段
2.3 哪些情况不要增加索引?
- 表记录太少
- 经常增删改的表
- 数据重复且分布均匀的表字段,只应该为最经常查询和最经常排序的数据列建立索引。
- 频繁更新的字段不适合创建索引
- where条件里用不到的字段建立索引
####2.4 MySql查询count()和count(1)在统计结果的时候不会忽略值为NULL
count(column)只包括那一列,在统计结果的时候会忽略值为NULL的字段不会统计进去
count(column)如果为主键,速度会比count(1)快
count(columns)部位主键count(1)会比count(columns)快
如果表多个列 并且没有主键count(1)效率优于count()
如果有主键 select count(主键)最优
如果表只有一个字段 select count(*)最优mysql的 in和exists的区别
1.exists对外表采用loop逐条查询,每次查询都会查看exists的条件语句,当exists里面能够返回记录行,条件为true,返回当前的这条记录。
2. in 查询相当于多个or的语句
2.4.1 ACID有哪些特性。2.4.2幻读和不可重复读的区别
- READ-UNCOMMITED(读未提交):最低的隔离级别,允许读取尚未提交的数据变更,可能会导致藏独幻读或者不可重复读
- READ-COMMITED(读已提交):允许读取并发事物已提交的数据。可以阻止脏读, 但是幻读和不可重复读仍有可能
- REPEATABLE-READ:(可重复读 默认级别)。可以阻止脏读和不可重复读,但幻读仍有可能发生
- SERIALIZABLE(可串行化):可以防止脏读,不可重复读以及幻读
####2.5 事物是如何通过日志来实现的?
事物日志包括:重做日志redo 和回滚日志undo2.9 分库?
一个库里表太多了,导致数据太多性能下降。把库中的表进行拆分,按照功能模块拆分
- 原子性: 整个事物中的所有操作,要么全部完成,要么全部不完成,不可能暂停在中概念某个环境,发生错误的时候,事物回滚到事物开始前的状态
- 一致性: 在事物开始之前和事物结束以后,数据库的完整约束没有被破坏
- 隔离性:一个事物执行不能被其它事物干扰。一个事物内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事物之间不能互相干扰
- 持久性: 在事物完成以后,该事物对数据产生的更改会被持久保存在数据库之中。
- 不可重复读的重点是修改:在同一事务中,同样的条件,第一次读的数据和第二次读的数据不一样
- 幻读的重点在于新增或者删除: 在同一事务中,同样的条件,第一次和第二次读出的数据记录不一样,因为中间有其他事物提交了插入或者删除
2.4.3 事物隔离级别
数据库事物的隔离级别有4种重做日志:实现持久化和原子性
undo log:实现一致性
2.6 Mysql有多少种日志?
错误日志、查询日志、慢查询日志、二进制日志、中继日志、事物日志
2.7 Mysql对分布式事物的支持
Mysql从5.0.3 InnoDB存储引擎开始支持XA协议的分布式事物,一个分布式事物会涉及多个行动,这些行动本身是事物性的。
Mysql的分布式事物模型,分为三块:
- 应用程序 定义了事物的边界,指定需要做哪些事物
- 资源管理器 提供了访问事务的方法,通常一个数据库就是一个资源管理器.
- 事物管理器 协调参与了全局事物中的各个事物
2.8 分布式事务采用两段式提交的方式:
第一阶段所有的事物节点开始准备,告诉事物管理器redy
第二阶段事物管理器告诉每个节点是commit还是rollback。
Mysql分库分表减少增量数据写入时的锁对查询的影响
单表查询下降,减少磁盘IO、延时变短
分库之后分布式事物的问题,怎么保证数据的完整性和一致性?
配主从
主从复制slave会从master读取binlog来进行数据同步每个slave只有一个master 每个slave只能有一个唯一服务器的ID 每个master可以有多个slave
主从最大的问题?
延时Mysql的主键索引和非主键索引的区别?
- 主键索引的查询方式,则只需要查询主键索引的这颗B+Tree树
- 非主键索引的查询方式,则先搜索主键索引的这颗树,得到ID=100然后再去ID索引树搜索一次
Mysql的唯一索引和普通索引效率
- 查询时、唯一索引找到数据即返回,但是普通索引会继续扫描下一条数据
- 更新时、普通索引和唯一索引的效率,唯一索引会先丢入到内存当中去比较唯一性,普通索引采用change buffer直接更新。所以唯一索引增加磁盘访问次数。

若有收获,就点个赞吧
0 人点赞
