并发是多个任务共享时间段(由CPU切换执行,就像是在同时执行)
并行是多个任务发生在同一时刻(真真正正的同时执行)(必须在多核CPU下)
并行就像用更多的马车(CPU)来拉货(执行任务),货物总量(任务量)一定,那么花费的时间自然减少了。
所以并行可以缩短任务执行时间,提高多核CPU的利用率
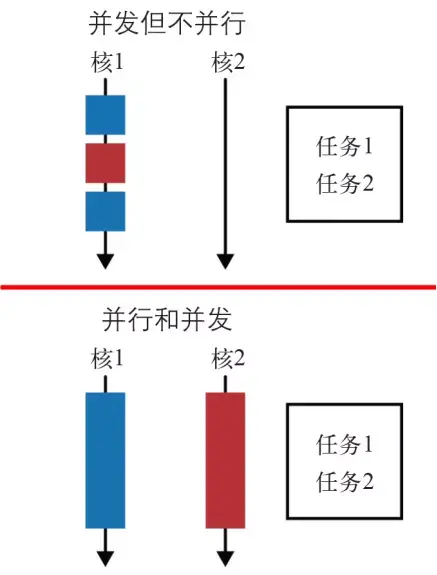
- 多个任务可以并行处理,那么数据也是可以并行处理的
数据并行是指把数据拆分成多个小单元,每个小单元再分配对应的处理单元。
数据并行化:
- Java5中我们可以采用concurrent库来实现数据并行
- Java7我们可以采用forke/join 来实现
- Java8 提供了对应的Api操作 所以实现了简单化流程
代码实测效率对比
public class ParalleStream {@Test//35592mspublic void testFor() throws Exception {long start = System.currentTimeMillis();long sum = 0;for (long i = 0; i < 100000000000L; i++) {sum += i;}System.out.println(sum);long end = System.currentTimeMillis();System.out.println(end-start);}@Test//52974mspublic void testStream() throws Exception {long start = System.currentTimeMillis();long sum = LongStream.rangeClosed(0, 100000000000L).sum();System.out.println(sum);long end = System.currentTimeMillis();System.out.println(end-start);}@Test//12808mspublic void testParallelStream() throws Exception {long start = System.currentTimeMillis();Arrays.asList( 1,2,3 ).stream().parallel().forEach( e->{System.out.println(e);} );long sum = LongStream.rangeClosed(0, 100000000000L).parallel().sum();System.out.println(sum);long end = System.currentTimeMillis();System.out.println(end-start);}}
- 应用场合
1.处理的数据量足够大
2.不止一个核 核数指的是 运行机器可以使用的cpu数量
3.装箱 处理基本类型比装箱的速度要快
4.数据结构 对于ArrayList 、InStream.range这些数据结构 处理速度要更快一点。对于处理HashSet、Treeset可能性能不是特别高、原因在于数据的接口后者在处理的时候不容易被分解

若有收获,就点个赞吧
0 人点赞
