1. 链表基本概念
1.1 链表
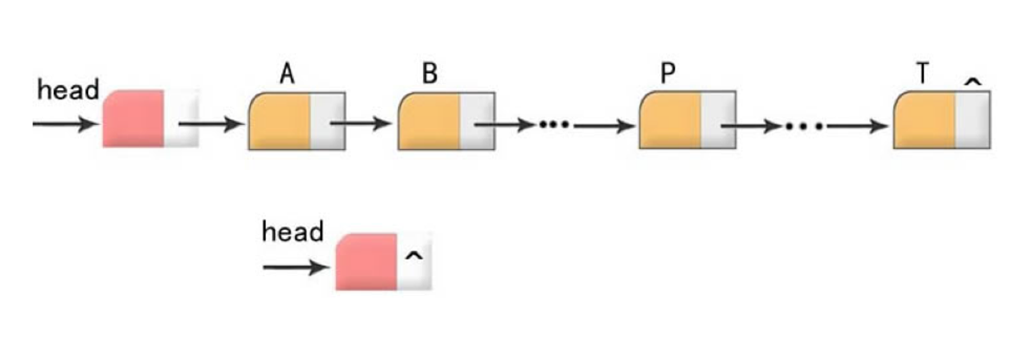
- 链表是一种常用的数据结构,它通过指针将一些列数据结点,连接成一个数据链。相对于数组,链表具有更好的动态性(非顺序存储)。
- 数据域用来存储数据,指针域用于建立与下一个结点的联系。
- 建立链表时无需预先知道数据总量的,可以随机的分配空间,可以高效的在链表中的任意位置实时插入或删除数据。
- 链表的开销,主要是访问顺序性和组织链的空间损失。
数组和链表的区别:
数组:一次性分配一块连续的存储区域。
优点:随机访问元素效率高
缺点:a. 需要分配一块连续的存储区域(很大区域,有可能分配失败)
b. 删除和插入某个元素效率低
链表:无需一次性分配一块连续的存储区域,只需分配n块节点存储区域,通过指针建立关系。
优点:a. 不需要一块连续的存储区域
b. 删除和插入某个元素效率高
缺点:随机访问元素效率低
1.2 链表节点
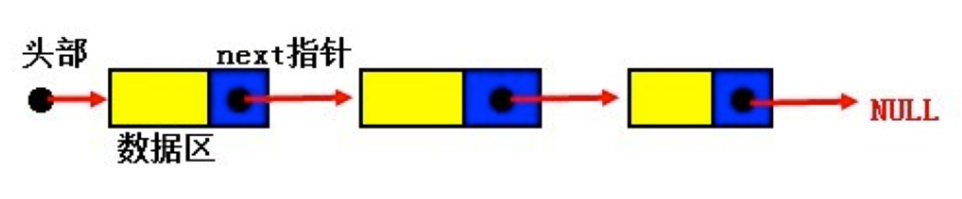
链表的节点类型实际上是结构体变量,此结构体包含数据域和指针域:
- 数据域用来存储数据;
- 指针域用于建立与下一个结点的联系,当此节点为尾节点时,指针域的值为NULL;
typedef struct Node{//数据域int id;char name[50];//指针域struct Node *next;}Node;
1.3 链表的分类
链表分为:静态链表和动态链表
静态链表和动态链表是线性表链式存储结构的两种不同的表示方式:
- 所有结点都是在程序中定义的,不是临时开辟的,也不能用完后释放,这种链表称为“静态链表”。
- 所谓动态链表,是指在程序执行过程中从无到有地建立起一个链表,即一个一个地开辟结点和输入各结点数据,并建立起前后相链的关系。
1.3.1 静态链表
typedef struct Stu{int id; //数据域char name[100];struct Stu *next; //指针域}Stu;void test(){//初始化三个结构体变量Stu s1 = { 1, "yuri", NULL };Stu s2 = { 2, "lily", NULL };Stu s3 = { 3, "lilei", NULL };s1.next = &s2; //s1的next指针指向s2s2.next = &s3;s3.next = NULL; //尾结点Stu *p = &s1;while (p != NULL){printf("id = %d, name = %s\n", p->id, p->name);//结点往后移动一位p = p->next;}}
1.3.2 动态链表
typedef struct Stu{int id; //数据域char name[100];struct Stu *next; //指针域}Stu;void test(){//动态分配3个节点Stu *s1 = (Stu *)malloc(sizeof(Stu));s1->id = 1;strcpy(s1->name, "yuri");Stu *s2 = (Stu *)malloc(sizeof(Stu));s2->id = 2;strcpy(s2->name, "lily");Stu *s3 = (Stu *)malloc(sizeof(Stu));s3->id = 3;strcpy(s3->name, "lilei");//建立节点的关系s1->next = s2; //s1的next指针指向s2s2->next = s3;s3->next = NULL; //尾结点//遍历节点Stu *p = s1;while (p != NULL){printf("id = %d, name = %s\n", p->id, p->name);//结点往后移动一位p = p->next;}//释放节点空间p = s1;Stu *tmp = NULL;while (p != NULL){tmp = p;p = p->next;free(tmp);tmp = NULL;}}

若有收获,就点个赞吧
0 人点赞
