豆瓣读书:https://book.douban.com/subject/4291903/

已经很久不看这种很“硬核”的技术书了,总觉得有种不踏实的感觉。
因此,就翻出来了很久之前就想看的这本书《Parsing Techniques》。
这本书,包括末尾的文献和索引,居然厚达 662 页,就算略去它们也需要看 573 页。
是一本值得深思熟虑后再决定开始看的书。
为什么呢?
我统计了自己读英文纯技术书籍的“效率”,大约每小时只能读 10 页,每天的脑容量最多坚持 4 个小时(40 页)。
所以,这本书累计需要 573/40 = 14.325 天才可以读完。
除去周末(会去锻炼身体)之后,则至少需要 3 个星期(3*5天 = 15天)才可以读完。
这是一件很恐怖的事情。
它意味着我每天必须拿出 4 个小时来啃书,还要坚持 3 个星期,这其实不算什么。
更重要的是,这 3 个星期我不能去看别的书了,不能有其他优先级更高的知识要学。
综上所述,每当我决定阅读一本 500 页以上的纯技术书籍时,总是会十分谨慎。
需要排除一切干扰,直到读完。
说起书的内容,这本书和跟其他的编译相关的书不太一样,
其他编译相关的书籍,经常力求全面,从(编译器)前端介绍到了(编译器)后端,给人一种大局观。
这本书则不同,所有的内容都在说解析技术,也就是(编译器)前端相关的内容。
如果实际项目用得到编译的话,似乎(编译器)前端所有问题都被解决了,
从网上找一些解析器生成器,编制符合约定的文法,就得到解析器了,(后端也有类似的问题)
这也是为什么 LLVM 这么火热的原因,人们只需将精力放在优化环节即可。
但是,读完这本书之后,发现(编译器)前端并不是那么简单的领域,
尤其是有兴趣写一个自己的解析器生成器的朋友,
我们需要一点点理论知识,更需要对所有相关的解析技术有所了解。
因此,这本书看起来在介绍各种相关的解析技术,
其实一开始就给我一种印象,作者是在介绍如何写一个解析器生成器。
找出各种文法的处理套路,以致于很多解析器可以按套路生成。(虽然作者没有明说)
如果读者精力有限的话,强烈建议直接读 6 7 8 9 章,
分别介绍了,通用(含搜索)的解析器(6 7章),和线性时间(确定性的)解析器(8 9章),
这几章内容最接地气,尤其是8 9章,提到了很多耳熟能详的名词,例如 LL(1),LR(1),LALR(1) 等等。
加上其他章节,只是让解析技术更加系统化了而已。
后面的非经典解析,子字符串解析,并行解析,错误处理与恢复,
如果实际用不到的话,真是锦上添花的阅读资料了。
总而言之,这是一本足够“硬核”的书,但又不会过于晦涩难懂,
不需要太多的前置知识就可以读完。(对比于一些理论性较强的书籍而言)
书中大部分算法,都给出了图文示例(不是代码示例),对于理解一段文字描述的处理过程非常有帮助。
这本书也有一些人在进行翻译工作,不过感觉还是读原作味道更好一些,
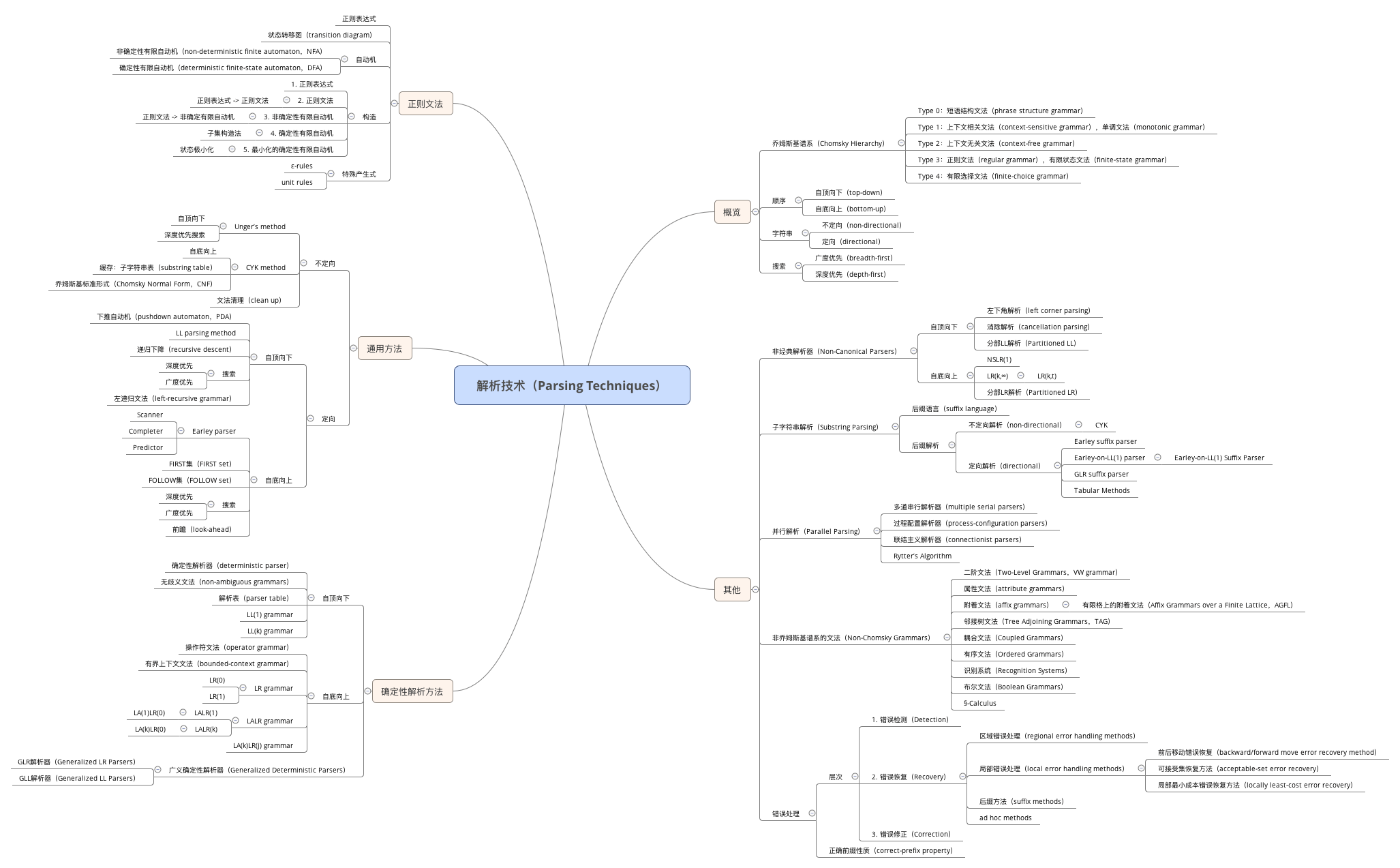
尤其是一些专业术语,上面我画的脑图中的翻译其实是不准确的,最准确的描述就是用原文。
记住了一些专业术语后,对今后持续学习相关的领域的深入内容很有帮助,很少会出现概念对不上的情况。
最后,这本书非常赞,值得阅读。
解析技术 2019.09.03 11.39.xmind
解析技术 2019.09.03 11.39.md
后记:2019.08.19 - 2019.09.03
早晨 7:00 - 9:00 读 20 页
中午 13:00 - 14: 00 读 10 页
晚上 21:00 - 22:00 读 10 页
晨起洒扫,午餐而夕寐,弹琴读书,晤对良朋,如是而已。

若有收获,就点个赞吧
0 人点赞
