Hadoop
HDFS
Yarn
MapReduce
- 序列化
- 类型
- BooleanWritable
- ByteWritable
- IntWritable
- FloatWritable
- LongWritable
- DoubleWritable
- Text
- MapWritable
- ArrayWritable
- 类型
- 原理
- MapTask:多少个切片就有多少个task
- 数据块:Block是HDFS物理上把数据分成一块一块
- 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
- InputFormat
- FileInputFormat
- 切片机制:
- TextInputFormat
- KeyValueTextInputFormat
- NLineInputFormat
- CombineTextInputFormat
- 切片机制
- 自定义
- FileInputFormat
- MapTask:多少个切片就有多少个task
- 工作流程
数据采集通道
Flume
Sqoop
Kafka
数据计算
Spark
Hive
- 简介
- 优点
- 类SQL语法
- 避免了去写MapReduce,减少开发人员的学习成本
- Hive优势在于处理大数据,对于处理小数据没有优势
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
- 缺点
- HQL表达能力有限
- 自动生成的MapReduce作业,通常情况下不够智能化
- 调优比较困难,粒度较粗
- 优点
- 安装
- 数据类型
- 基本数据类型
- 集合数据类型
- struct
- map
- array
- DDL
- 库的CRUD
- 创建:create
- 查询:show databases;desc database x;
- 修改:alter database *
- 删除:drop database xxx;
- 强制删除:drop database cascade;
- 显示数据库:desc database xxx;
- desc database extended xxx;
- 表:
- 建表语句
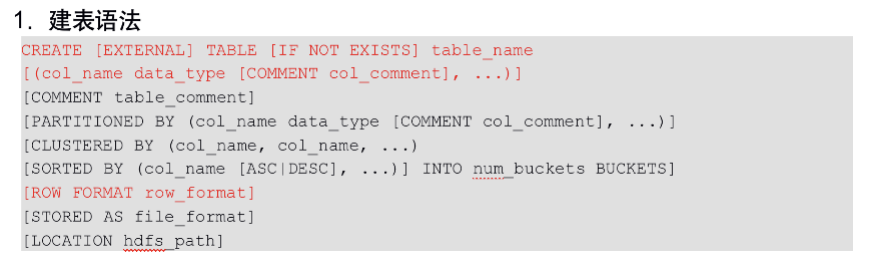
- CLUSTERED BY创建分桶表
- ROW FORMAT

- 存储类型
- SEQUENCEFILE(二进制序列文件)
- TEXTFILE(文本)
- RCFILE(列式存储格式文件)
- 表的类型
- 内部表
- 外部表
- 查询表的类型: desc formatted xxx;
- 分区表:分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录
- 增加分区
- alter table dept_partition add partition(month=’201706’) ;
- 删除分区
- alter table dept_partition drop partition (month=’201704’);
- 分区表加载数据
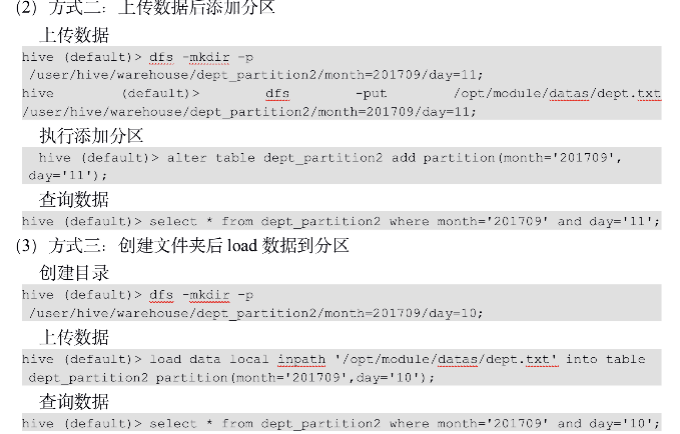
- 增加分区
- 修改表
- 重命名
- ALTER TABLE table_name RENAME TO new_table_name
- CRUD列
- 重命名
- 删除表
- drop table dept_partition;
- 建表语句
- 库的CRUD
- DML
- 导入
- 查询语句插入
- hive (default)> insert overwrite table student partition(month=’201708’)
select id, name from student where month=’201709’;
- hive (default)> insert overwrite table student partition(month=’201708’)
- 创建表时指定location,然后将数据上传到HDFS
- 查询语句插入
- 导出
- Insert导出
- hive (default)> insert overwrite local directory ‘/opt/module/datas/export/student’
select * from student;
- hive (default)> insert overwrite local directory ‘/opt/module/datas/export/student’
- Hadoop命令导出
- hive (default)> dfs -get /user/hive/warehouse/student/month=201709/000000_0
/opt/module/datas/export/student3.txt;
- hive (default)> dfs -get /user/hive/warehouse/student/month=201709/000000_0
- Hive shell 导出
- [atguigu@hadoop102 hive]$ bin/hive -e ‘select * from default.student;’ >
/opt/module/datas/export/student4.txt;
- [atguigu@hadoop102 hive]$ bin/hive -e ‘select * from default.student;’ >
- Insert导出
- 清空
- truncate table student;
- Truncate只能删除管理表,不能删除外部表中数据
- truncate table student;
- 导入
- 查询
- 基本查询语句
- 排序
- Order by: 全局排序,一个Reducer
- Sort by: 每个Reducer内部进行排序,对全局结果集来说不是排序
- 分区排序Distribute By:类似MR中partition,进行分区,结合sort by使用
- Cluster By:当distribute by和sorts by字段相同时,可以使用cluster by方式。
- 分桶:是对某个字段进行分区
- 常用查询函数
- concat
- concat_ws
- collect_set
- EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行
- 窗口函数over
- 函数
- 内置
- 自定义
- UDF:一进一出
- UDAF: 多进一出
- UDTF:一进多出
- 压缩存储
- 优化
- 端口
- 9083
- metastore: /etc/default/hive-metastore中export PORT=来更新默认端口
- 10000
- HiveServer: /etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT=来更新默认端口
- 9083
Hue
Tez
HBase
即席查询
Impala
Druid
Presto
- 应用场景
- 将多个数据源的数据进行合并,可以跨越整个组织进行分析
- 处理响应时间小于1秒到几分钟的场景
- 优缺点
- 优点
- Presto基于内存运算,减少了硬盘IO,计算更快
- 能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
- 缺点
- Presto能够处理PB级别的海量数据分析,但Presto并不是把PB级数据都放在内存中计算的。而是根据场景,如Count,AVG等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
- 优点
- 架构
- 服务端安装
- 解压:presto-server-0.196.tar.gz
- 创建文件夹
- data
- etc
- jvm.config
- -server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
- -server
- catalog文件夹:配置多数据源
- hive.properties
- connector.name=hive-hadoop2
hive.metastore.uri=thrift://hadoop102:9083
- connector.name=hive-hadoop2
- mysql.properties
- connector.name=mysql
connection-url=jdbc:mysql://172.26.1.68:3306
connection-user=admin
connection-password=Password_123
- connector.name=mysql
- hive.properties
- node.properties
- node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto/data
- node.environment=production
- config.properties
- coordinator节点
- coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://hadoop102:8881
- coordinator=true
- work节点
- coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://hadoop102:8881
- coordinator=false
- coordinator节点
- jvm.config
- 启动
- 前台
- 在每个节点上运行: bin/launcher run
- 后台
- 在每个节点上运行: bin/launcher start
- 查看日志:/opt/module/presto/data/var/log
- 前台
- 停止
- 后台:bin/launcher stop
- 可视化客户端安装
- 解压yanagishima-18.0.zip
- 配置conf/yanagishima.properties
- jetty.port=7080
presto.datasources=atiguigu-presto
presto.coordinator.server.atiguigu-presto=http://hadoop102:8881
catalog.atiguigu-presto=hive
schema.atiguigu-presto=default
sql.query.engines=presto
- jetty.port=7080
- 启动:nohup bin/yanagishima-start.sh >y.log 2>&1 &
- 访问:http://hadoop102:7080
Kylin
Linux基础
Zookeeper
Azkaban

若有收获,就点个赞吧
0 人点赞
