原文链接
http://www.nosqlnotes.com/technotes/hbase/hbase-overview-concepts/
开篇
用惯了Oracle/MySQL的同学们,心目中的数据表,应该是长成这样的:
这种表结构规整,每一行都有固定的列构成,因此,非常适合结构化数据的存储。但在NoSQL领域,数据表的模样却往往换成了另外一种”画风”:

行由看似”杂乱无章”的列组成,行与行之间也无须遵循一致的定义,而这种定义恰好符合半结构化数据或非结构化数据的特点。本文所要讲述的HBase,就属于该派系的一个典型代表。这些”杂乱无章”的列所构成的多行数据,被称之为一个”稀疏矩阵”,而上图中的每一个”黑块块”,在HBase中称之为一个KeyValue。
HBase常被用来存放一些结构简单,但数据量非常大的数据(通常在TB/PB级别),如历史订单记录,日志数据,监控Metris数据等等,HBase提供了简单的基于Key值的快速查询能力。
约定
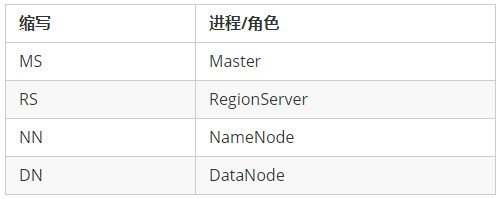
术语缩写:对于一些进程/角色名称,在本文范围内可能通过缩写形式来表述:
数据模型
Rowkey
用来表示唯一一行记录的主键,HBase的数据是按照RowKey的字典顺序进行全局排序的,所有的查询都只能依赖于这一个排序维度。
(全局排序的意思就是针对每一条记录,都会基于rowkey插入到指定的位置)
通过下面一个例子来说明一下”字典排序“的原理: RowKey {“abc”, “a”, “bdf”, “cdf”, “defg”}按字典排序后的结果为{“a”, “abc”, “bdf”, “cdf”, “defg”}_ 也就是说,当两个RowKey进行排序时,先对比两个RowKey的第一个字节,如果相同,则对比第二个字节,依此类推…如果在对比到第M个字节时,已经超出了其中一个RowKey的字节长度,那么,短的RowKey要被排在另外一个RowKey的前面_
稀疏矩阵
百度百科定义:在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵
参考了Bigtable,HBase中一个表的数据是按照稀疏矩阵的方式组织的,”开篇”部分给出了一张关于HBase数据表的抽象图,我们再结合下表来加深大家关于”稀疏矩阵”的印象: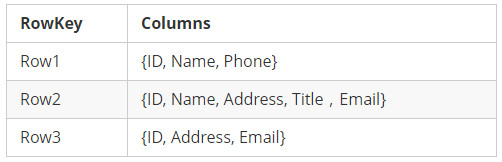
看的出来:每一行中,列的组成都是灵活的,行与行之间并不需要遵循相同的列定义, 也就是HBase数据表”schema-less“的特点。
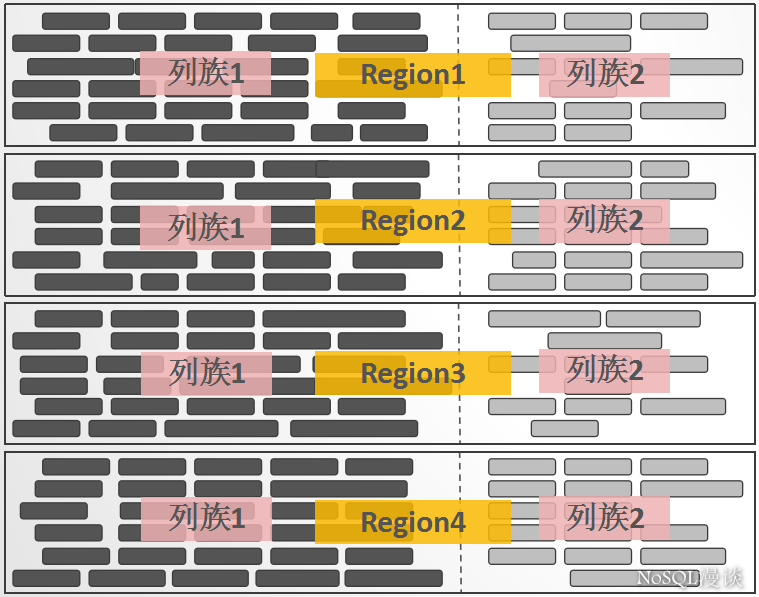
Region
区别于Cassandra/DynamoDB的”Hash分区”设计,HBase中采用了”Range分区”,将Key的完整区间切割成一个个的”Key Range” ,每一个”Key Range”称之为一个Region。
也可以这么理解:将HBase中拥有数亿行的一个大表,横向切割成一个个”子表“,这一个个”子表“就是Region:
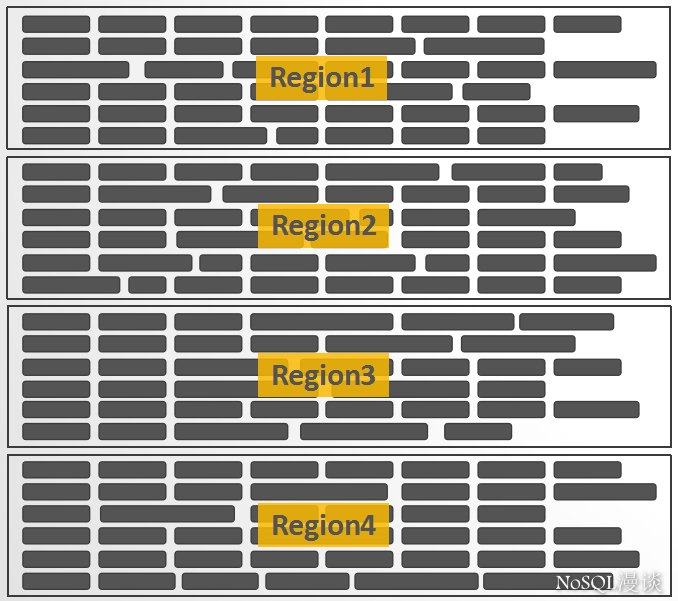
Region是HBase中负载均衡的基本单元,当一个Region增长到一定大小以后,会自动分裂成两个。
Column Family-列镞
如果将Region看成是一个表的横向切割,那么,一个Region中的数据列的纵向切割,称之为一个Column Family。每一个列,都必须归属于一个Column Family,这个归属关系是在写数据时指定的,而不是建表时预先定义:
Key Value
KeyValue的设计不是源自Bigtable,而是要追溯至论文”The log-structured merge-tree(LSM-Tree)”。每一行中的每一列数据,都被包装成独立的拥有特定结构的KeyValue,KeyValue中包含了丰富的自我描述信息:

看的出来,KeyValue是支撑”稀疏矩阵”设计的一个关键点:一些Key相同的任意数量的独立KeyValue就可以构成一行数据。但这种设计带来的一个显而易见的缺点:每一个KeyValue所携带的自我描述信息,会带来显著的数据膨胀。
HBase与HDFS
我们都知道HBase的数据是存储于HDFS里面的,相信大家也都有这么的认知:
3.HBase中的数据为何不直接存放于HDFS之上? HBase中存储的海量数据记录,通常在几百Bytes到KB级别,如果将这些数据直接存储于HDFS之上,会导致大量的小文件产生,为HDFS的元数据管理节点(NameNode)带来沉重的压力。 _ 4、文件能否直接存储于HBase里面?** 如果是几MB的文件,其实也可以直接存储于HBase里面,我们暂且将这类文件称之为小文件,HBase提供了一个名为MOB的特性来应对这类小文件的存储。但如果是更大的文件,强烈不建议用HBase来存储,关于这里更多的原因,希望你在详细读完本文所有内容之后能够自己解答。
集群角色
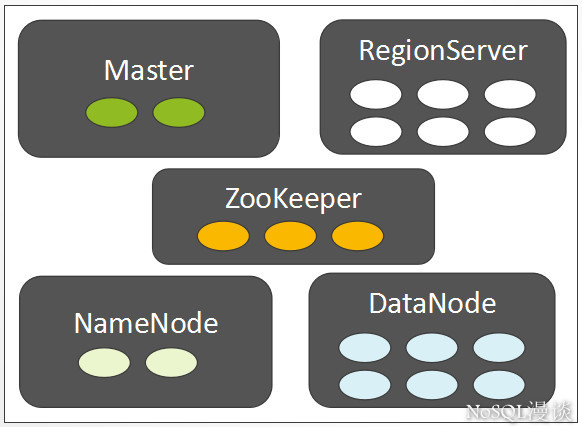
相信大部分人对这些角色都已经有了一定程度的了解,我们快速的介绍一下各个角色在集群中的主要职责(注意:这里不是列出所有的职责):
ZooKeeper
在一个拥有多个节点的分布式系统中,假设,只能有一个节点是主节点,如何快速的选举出一个主节点而且让所有的节点都认可这个主节点?这就是HBase集群中存在的一个最基础命题。
利用ZooKeeper就可以非常简单的实现这类”仲裁”需求,ZooKeeper还提供了基础的事件通知机制,所有的数据都以 ZNode的形式存在,它也称得上是一个”微型数据库”
- NameNode
HDFS作为一个分布式文件系统,自然需要文件目录树的元数据信息,另外,在HDFS中每一个文件都是按照Block存储的,文件与Block的关联也通过元数据信息来描述。NameNode提供了这些元数据信息的存储。
- DataNode
HDFS的数据存放节点。
RegionServer
HBase的**数据服务节点**。
Master
HBase的管理节点,通常在一个集群中设置一个主Master,一个备Master,主备角色的”仲裁”由ZooKeeper实现。 Master主要职责:
- 负责管理所有的RegionServer
- 建表/修改表/删除表等DDL操作请求的服务端执行主体
- 管理所有的数据分片(Region)到RegionServer的分配
- 如果一个RegionServer宕机或进程故障,由Master负责将它原来所负责的Regions转移到其它的RegionServer上继续提供服务
- Master自身也可以作为一个RegionServer提供服务,该能力是可配置的

若有收获,就点个赞吧
0 人点赞
