1、配置
1.1 pom
<!-- 内部依赖了hadoop-common和hadoop-hdfs--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0</version></dependency>
2、序列化
需要实现 org.apache.hadoop.io.Writable 接口的write和readFields方法。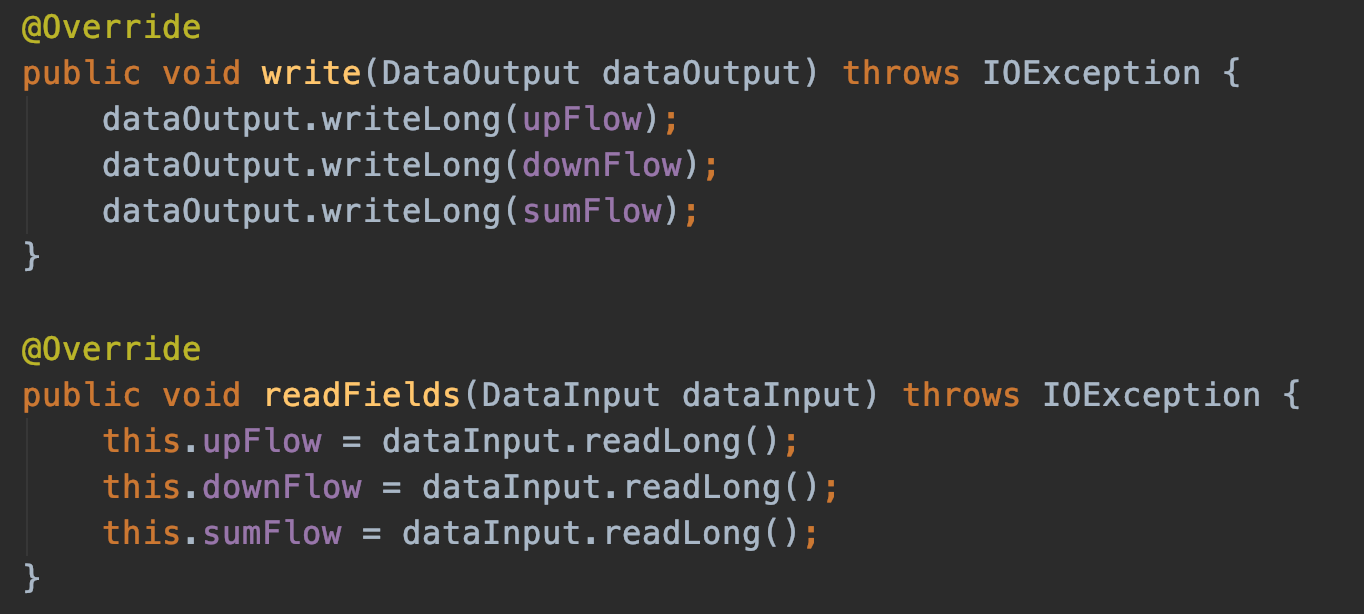
2.1 输入数据
phone.txt:
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 2002 13846544121 192.196.100.2 264 0 2003 13956435636 192.196.100.3 132 1512 2004 13966251146 192.168.100.1 240 0 4045 18271575951 192.168.100.2 www.atguigu.com 1527 2106 2006 84188413 192.168.100.3 www.atguigu.com 4116 1432 2007 13590439668 192.168.100.4 1116 954 2008 15910133277 192.168.100.5 www.hao123.com 3156 2936 2009 13729199489 192.168.100.6 240 0 20010 13630577991 192.168.100.7 www.shouhu.com 6960 690 20011 15043685818 192.168.100.8 www.baidu.com 3659 3538 20012 15959002129 192.168.100.9 www.atguigu.com 1938 180 50013 13560439638 192.168.100.10 918 4938 20014 13470253144 192.168.100.11 180 180 20015 13682846555 192.168.100.12 www.qq.com 1938 2910 20016 13992314666 192.168.100.13 www.gaga.com 3008 3720 20017 13509468723 192.168.100.14 www.qinghua.com 7335 110349 40418 18390173782 192.168.100.15 www.sogou.com 9531 2412 20019 13975057813 192.168.100.16 www.baidu.com 11058 48243 20020 13768778790 192.168.100.17 120 120 20021 13568436656 192.168.100.18 www.alibaba.com 2481 24681 20022 13568436656 192.168.100.19 1116 954 200
2.2 map reduce
package com.twx.bigdata;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author tangwx@soyuan.com.cn
* @date 2020/3/9 14:58
*/
public class FlowCountMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
// 取出手机号码
String phoneNum = fields[1];
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
v.set(upFlow,downFlow);
k.set(phoneNum);
context.write(k,v);
}
}
package com.twx.bigdata;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author tangwx@soyuan.com.cn
* @date 2020/3/9 15:04
*/
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
// 1 遍历所用bean,将其中的上行流量,下行流量分别累加
for (FlowBean flowBean : values) {
sum_upFlow += flowBean.getUpFlow();
sum_downFlow += flowBean.getDownFlow();
}
// 2 封装对象
FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow);
// 3 写出
context.write(key, resultBean);
}
}
2.3 driver
package com.twx.bigdata;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author tangwx@soyuan.com.cn
* @date 2020/3/9 15:07
*/
public class FlowsumDriver {
public static void main(String[] args) throws Exception{
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
// configuration.set("dfs.client.use.datanode.hostname","true");
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(FlowsumDriver.class);
// 3 设置map和reduce类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text .class);
job.setMapOutputValueClass(FlowBean.class);
// 5 设置reducer输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3、自定义partition
1、需要继承 org.apache.hadoop.mapreduce.Partitioner 类重写 getPartition 方法
2、在Job驱动中,设置自定义Partitioner
3、自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
3.1 ProvincePartitioner
package com.twx.bigdata;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author tangwx@soyuan.com.cn
* @date 2020/3/9 15:16
*/
public class ProvincePartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
// 1 获取电话号码的前三位
String preNum = text.toString().substring(0, 3);
int partition = 4;
// 2 判断是哪个省
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
3.2 driver
在2.3基础上添加如下两行配置
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5);
3.3 总结
(1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1
(4)分区号必须从零开始,逐一累加。

若有收获,就点个赞吧
0 人点赞
