Presto入门
总览
应用场景
将多个数据源的数据进行合并,可以跨越整个组织进行分析
处理响应时间小于1秒到几分钟的场景
优缺点
优点
- Presto基于内存运算,减少了硬盘IO,计算更快
- 能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
缺点
- Presto能够处理PB级别的海量数据分析,但Presto并不是把PB级数据都放在内存中计算的。而是根据场景,如Count,AVG等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
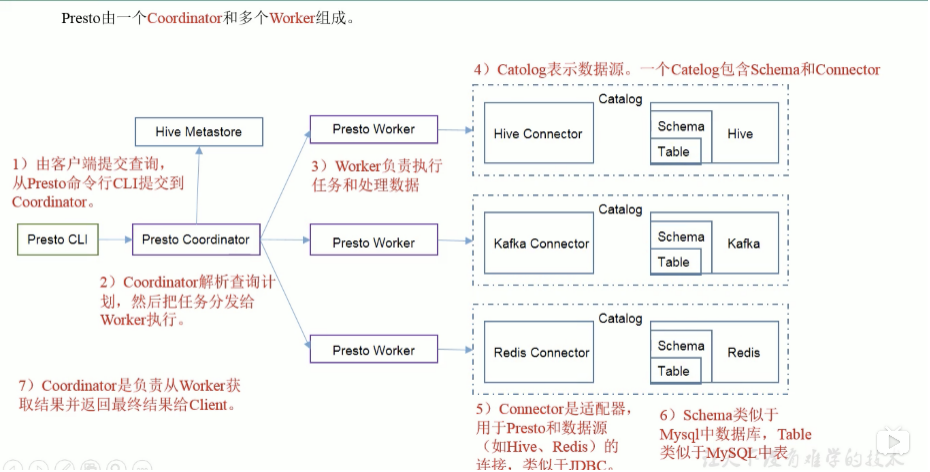
架构
服务端安装
1、解压:presto-server-0.196.tar.gz
2、创建文件夹
- data
- etc
- jvm.config
- catalog文件夹:配置多数据源
- hive.properties
- connector.name=hive-hadoop2
hive.metastore.uri=thrift://hadoop102:9083
- connector.name=hive-hadoop2
- mysql.properties
- connector.name=mysql
connection-url=jdbc:mysql://172.26.1.68:3306
connection-user=admin
connection-password=Password_123
- connector.name=mysql
- hive.properties
- node.properties
- node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto/data
- node.environment=production
- config.properties
- coordinator节点
- coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://hadoop102:8881
- coordinator=true
- work节点
- coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://hadoop102:8881
- coordinator=false
- coordinator节点
启动
- 前台
- 在每个节点上运行: bin/launcher run
- 后台
- 在每个节点上运行: bin/launcher start
- 查看日志:/opt/module/presto/data/var/log
停止
- 后台:bin/launcher stop
可视化客户端安装
1、解压yanagishima-18.0.zip
2、配置conf/yanagishima.properties
- jetty.port=7080
presto.datasources=atiguigu-presto
presto.coordinator.server.atiguigu-presto=http://hadoop102:8881
catalog.atiguigu-presto=hive
schema.atiguigu-presto=default
sql.query.engines=presto
3、启动:nohup bin/yanagishima-start.sh >y.log 2>&1 &
4、访问:http://hadoop102:7080
_

若有收获,就点个赞吧
0 人点赞
