半包、黏包
问题背景
在TCP协议发送数据时,发送端需要将分片,分成多次发送;接收端接收到的数据不完整,这就产生了半包;
也有可能一个数据包里的数据不是同一条消息里的,或者接收端收到数据存放在缓冲区没有及时取走,原本应该分开的数据粘在了一起,这就是粘包;
现象演示
服务端:
发生原因
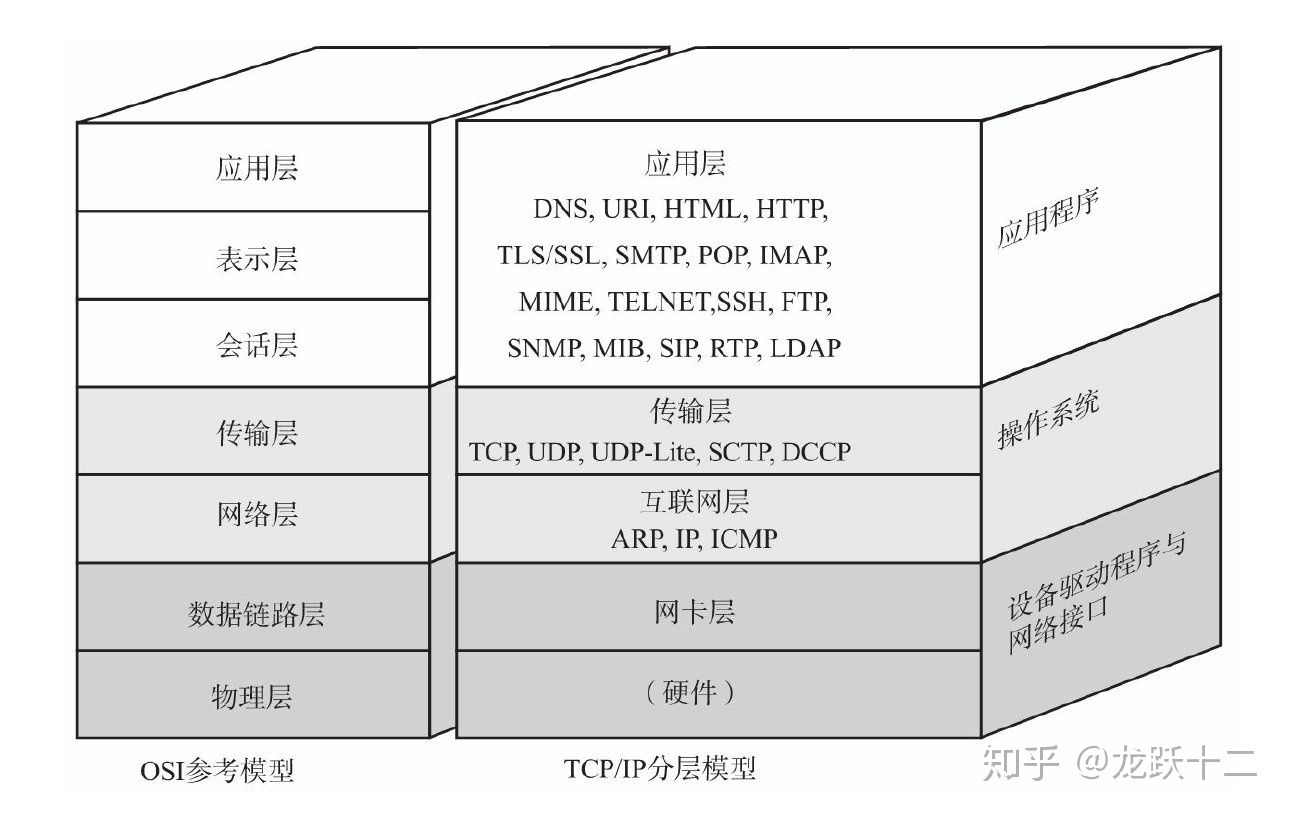
1. TCP协议是基于字节流的
TCP协议工作在传输层,负责流式地传输数据
TCP协议的三大特点,面向连接、可靠的、基于字节流;
其中粘包、半包问题。就是基于字节流这个特性导致的。
应用层交付给TCP的是结构化的数据,结构化的数据到了TCP层做流式传输,并不能理解上层对数据的结构化区分;流的问题就是没有边界,没有边界就会造成数据可能被错误的分隔、粘贴,从而发生半包、粘包。
TCP协议还引入了滑动窗口,对所有数据帧按顺序赋予编号,只有落在滑动窗口内的数据帧才能被发送。
滑动窗口可以控制发送端发送数据的大小,从而达到流量控制的目的。
2. MSS/MTU分片
数据比较大,一个数据包肯定传输不完,就需要对数据进行分片,如何确定分片大小?
MTU Maximum Transmit Unit,最大传输单元。 即物理接口(数据链路层)提供给其上层(通常是IP层)最大一次传输数据的大小
以普遍使用的以太网接口为例,缺省MTU=1500 Byte,这是以太网接口对IP层的约束,如果IP层有<=1500 byte 需要发送,只需要一个IP包就可以完成发送任务;如果IP层有> 1500 byte 数据需要发送,需要分片才能完成发送,这些分片有一个共同点,即IP Header ID相同。
MSS,Maximum Segment Size TCP提交给IP层最大分段大小,不包含TCP Header和 TCP Option,只包含TCP Payload 。 MSS是TCP用来控制应用层最大的发送字节数,即实际要发送的DATA大小的最大字节数
如果底层MTU= 1500 byte,则 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果应用层有2000 byte发送,需要两个segment才可以完成发送,第一个TCP segment = 1460,第二个TCP segment = 540。
由上可知,当发送缓冲区的数据大于MSS大小时,数据将被拆分,可能引起半包、粘包
3. Nagle算法
为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据,即尽可能的以MSS大小发送数据。
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;(表示请求关闭连接,则先将SO_SNDBUF中的剩余数据发送,再关闭)
(3)设置了TCP_NODELAY选项,则允许发送;相当于禁止了Nagle算法。
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
Nagel算法的存在,会使
解决方案
大的思路是在应用层定义协议来指定传输数据的格式,这样在接收端就可以根据协议来将消息解析出来。
消息定长
特殊字符作边界
在包尾部增加空格或回车等特殊字符作为消息边界,接收端按行解析,解析到\n、\r\n等特殊字符时,就认为是一个完整的数据。
问题:
- 需要完整扫描包数据
- 如果数据本身中含有特殊字符,需要发送前进行转义;否则就解析错误
指定长度
将消息分为消息头和消息体,消息头中用一个int型数据(4字节),表示消息体长度的字段。在解析时,先读取内容长度Length,其值为实际消息体内容(Content)占用的字节数,之后必须读取到这么多字节的内容,才认为是一个完整的数据报文。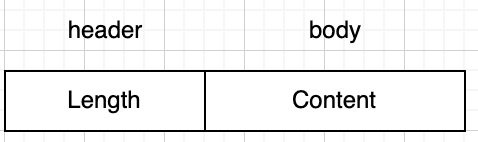
Netty编解码解决方案
为了解决粘包、半包的问题,需要自定义通信协议,双方根据协议约定好数据格式,发送方和接收方分别来编码、解码数据。
- 编码:发送方要将发送的二进制数据转换成协议规定的格式的二进制数据流,称之为编码(
encode),编码功能由编码器(encoder)完成。 - 解码:接收方需要根据协议的格式,对二进制数据进行解析,称之为解码(
decode),解码功能由解码器(decoder)完成。 - 编解码:如果有一种组件,既能编码,又能解码,则称之为编码解码器(
codec)。这种组件在发送方和接收方都可以使用。Netty编解码框架
编码器
解码器
常用的Netty解码器
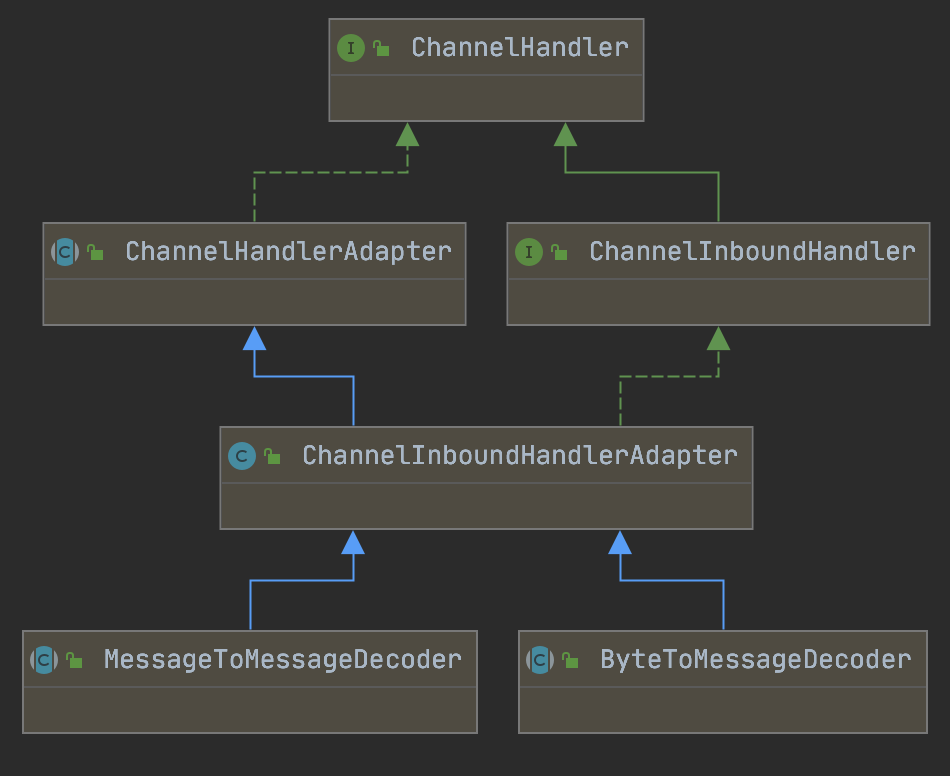
ByteToMessageDecoder
ByteToMessageDecoder用于将接收到的二进制数据解析得到完整的报文(message)
ByteToMessageDecoder解码后内容会得到一个ByteBuf实例列表,每个ByteBuf实例都包含了一个完整的报文信息;后续的ChannelInboundHandler再处理ByteBuf实例,就不需要关注粘包等问题。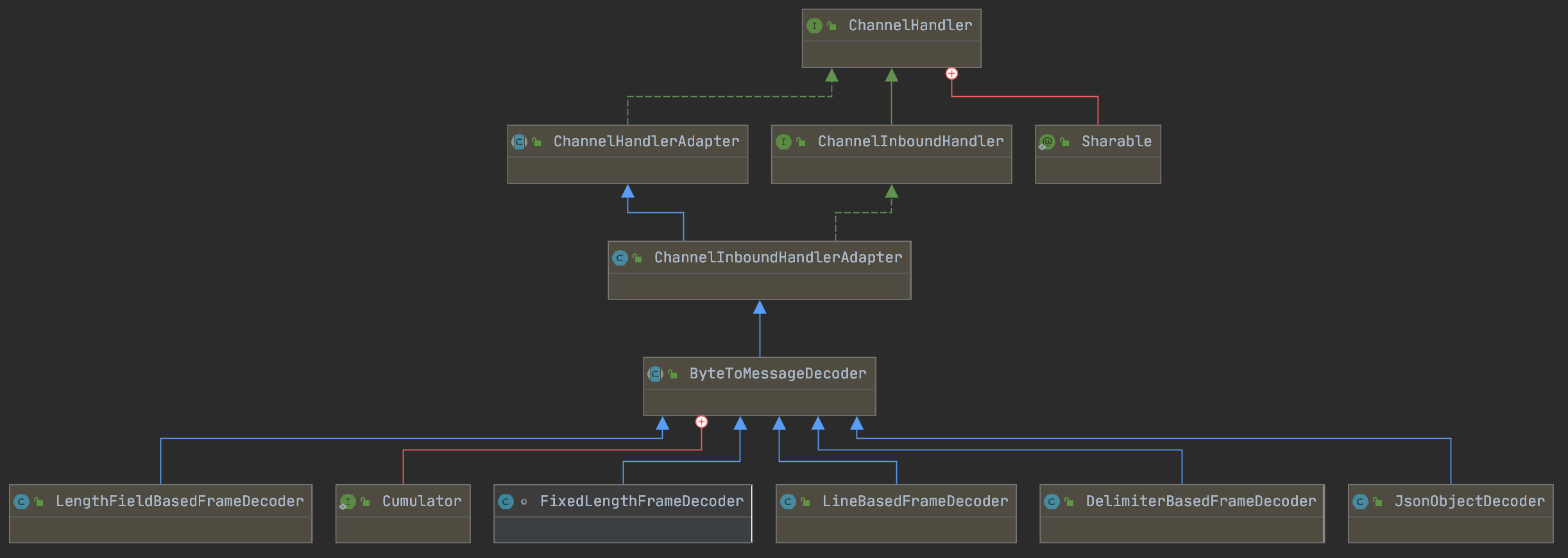
@Slf4jpublic class HelloServer {public static void main(String[] args) {{NioEventLoopGroup bossGroup = new NioEventLoopGroup();NioEventLoopGroup workerGroup = new NioEventLoopGroup();ServerBootstrap bootstrap = new ServerBootstrap();ChannelFuture channelFuture = bootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {// ch.pipeline().addLast(new FixedLengthFrameDecoder(5));// ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));ch.pipeline().addLast(new LineBasedFrameDecoder(10));ch.pipeline().addLast(new StringDecoder());ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(msg);}});}}).bind(new InetSocketAddress(8080));try {channelFuture.sync();channelFuture.channel().closeFuture().sync();} catch (InterruptedException e) {e.printStackTrace();}}}}
FixedLengthFrameDecoder
定长协议解码器,我们可以指定固定的字节数算一个完整的报文
LineBasedFrameDecoder
行分隔符解码器,遇到\n或者\r\n,则认为是一个完整的报文
DelimiterBasedFrameDecoder
分隔符解码器,与LineBasedFrameDecoder类似,只不过分隔符可以自己指定
LengthFieldBasedFrameDecoder
长度编码解码器,(变长解码器),将报文划分为报文头/报文体,根据报文头中的Length字段确定报文体的长度,因此报文提的长度是可变的
JsonObjectDecoder
json格式解码器,当检测到匹配数量的”{“ 、”}”或”[””]”时,则认为是一个完整的json对象或者json数组。
MessageToMessageDecoder
将一个本身就包含完整报文信息的对象转换成另一个Java对象。
举例来说,前面介绍了ByteToMessageDecoder的部分子类解码后,会直接将包含了报文完整信息的ByteBuf实例交由之后的ChannelInboundHandler处理,此时,你可以在ChannelPipeline中,再添加一个MessageToMessageDecoder,将ByteBuf中的信息解析后封装到Java对象中,简化之后的ChannelInboundHandler的操作。
StringDecoder
将含有完整报文信息的ByteBuf转换成字符串,可以与ByteToMessageDecoder中的解码器联合使用。
以LineBasedFrameDecoder为例,其将二进制数据流按行分割后封装到ByteBuf中。我们可以在其之后再添加一个StringDecoder,将ByteBuf中的数据转换成字符串
Base64Decoder
用于base64解码
常用的Netty编码器
Netty提供了MessageToByteEncoder和MessageToMessageEncoder两个编码器的基类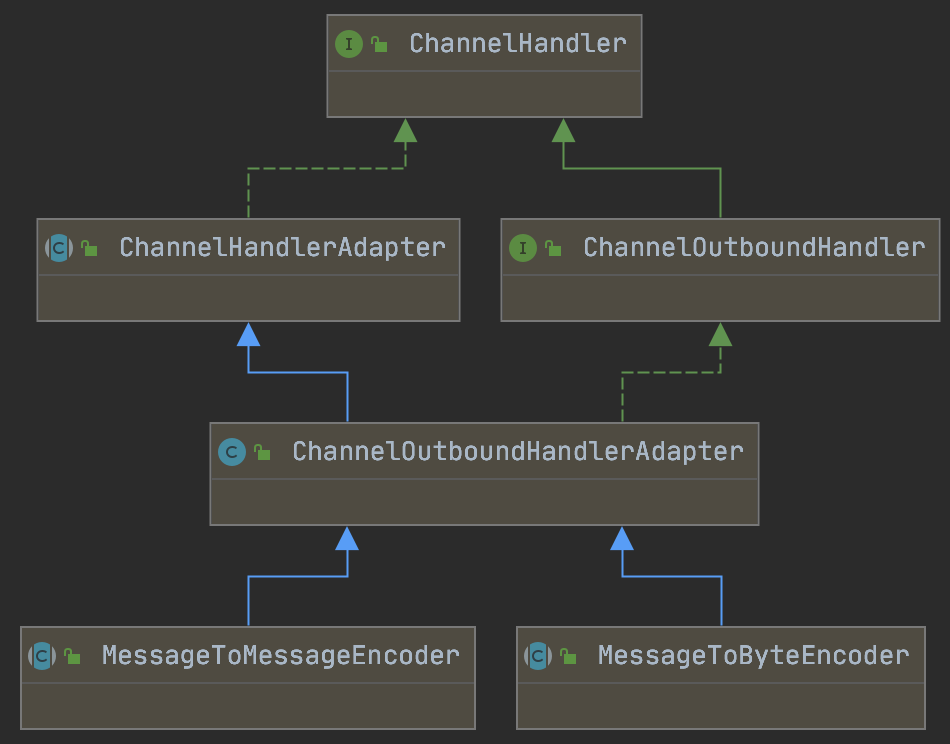
MessageToByteEncoder
泛型参数I表示将需要编码的对象的类型,编码的结果是将信息转换成二进制流放入ByteBuf中
public abstract class MessageToByteEncoder<I> extends ChannelOutboundHandlerAdapter {
......
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
}
MessageToMessageEncoder
与前者不同,编码的结果是将信息放入到一个List中
public abstract class MessageToMessageEncoder<I> extends ChannelOutboundHandlerAdapter {
...
protected abstract void encode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception;
...
}
MessageToMessageEncoder提供的常见子类包括:
LineEncoder
按行编码,给定一个CharSequence(如String),在其之后添加换行符\n或者\r\n,并封装到ByteBuf进行输出,与LineBasedFrameDecoder相对应。
Base64Encoder
给定一个ByteBuf,得到对其包含的二进制数据进行Base64编码后的新的ByteBuf进行输出,与Base64Decoder相对应。
LengthFieldPrepender
给定一个ByteBuf,为其添加报文头Length字段,得到一个新的ByteBuf进行输出。Length字段表示报文长度,与LengthFieldBasedFrameDecoder相对应。
StringEncoder
给定一个CharSequence(如:StringBuilder、StringBuffer、String等),将其转换成ByteBuf进行输出,与StringDecoder对应。
常用编解码器在协议中的应用
这部分内容参考大佬的博客内容,讲得很有条理
定长协议
变长协议
Netty协议设计与解析
Netty对Http协议的支持
如何自定义协议
自定义协议的要素
- 魔数:用来第一时间判定是否是无效数据包
- 版本号:
- 序列化算法
- 指令类型
- 请求序号
- 正文长度
- 消息正文
[
](http://www.tianshouzhi.com/api/tutorials/netty/343)
序列化
RPC的一个基础就是序列化,对象在不同的服务之间是以序列化后的形式传播。
JDK序列化
使用JDK序列化,只需要实现被序列化的对象实现Serializable接口
缺点:
ProtoBuf-Java开发
1. 安装proto工具
sky-mbp16@localhost ~ protoc --version
libprotoc 3.17.3
2. 编写并proto文件
syntax = "proto2";
option java_package= "com.sky.netty.protobuf";
option java_outer_classname="SubscribeReqProto";
message SubscribeReq {
required int32 subReqId = 1;
required string userName = 2;
required string productName = 3;
required string address = 4;
}
编译成POJO Java对象
protoc --java_out=./ proto/SubscribeReq.proto
protoc 支持多种语言,--java_out指定java语言
生成的POJO比较复杂,内置多种方法,不许要我们改动
3.测试使用
/**
* 测试proto java的功能
*/
public class TestSubscribeReqProto {
private static byte[] encode(SubscribeReqProto.SubscribeReq req){
// 将java对象编码为byte数组
return req.toByteArray();
}
private static SubscribeReqProto.SubscribeReq decode(byte[] body) throws InvalidProtocolBufferException {
// 将二进制byte数组解码为原始对象
return SubscribeReqProto.SubscribeReq.parseFrom(body);
}
private static SubscribeReqProto.SubscribeReq createSubscribeReq(){
SubscribeReqProto.SubscribeReq.Builder builder = SubscribeReqProto.SubscribeReq.newBuilder();
builder.setSubReqId(1);
builder.setUserName("sky");
builder.setProductName("Netty权威指南");
builder.setAddress("南京市江宁区");
return builder.build();
}
public static void main(String[] args) throws InvalidProtocolBufferException {
SubscribeReqProto.SubscribeReq req = createSubscribeReq();
System.out.println("编码前:"+req.toString());
// 编码
byte[] bytes = encode(req);
// 解码
SubscribeReqProto.SubscribeReq reqDecoded = decode(bytes);
System.out.println("解码后:"+reqDecoded.toString());
System.out.println(".equal:"+ req.equals(reqDecoded));
System.out.println("测试:"+reqDecoded.getAddress());
}
}
ProtoBuf 与 Netty
这部分代码在java-demo-project-netty/protobuf
Netty 内置了多种 PtotoBuf 的解码器。
- ProtobufDecoder:负责ProtoBuf解码,但是它不支持读半包,因此在ProtobufDecoder前一定要有能够处理半包的解码器
有三种方式处理半包:
- Netty提供的ProtobufVarint32FrameDecoder,专门用来处理Protobuf半包
- Netty提供的通用半包处理器,如LengthFieldBasedFrameDecoder等
- 继承ByteToMessageDecoder类,自己处理半包消息
[
](https://juejin.cn/post/6942640423286341668#heading-10)
参考

若有收获,就点个赞吧
0 人点赞
