单体架构下,一个服务往往只有一个表,唯一ID设置为自增就好;但是分布式场景下,一个业务可能由多个库中的多个表存储,这些表存储的数据在业务上是一样的,这时就不能让这些表各自维护ID了,需要保证全局唯一。
[
](https://pdai.tech/md/arch/arch-z-id.html)
分布式ID思路大致可以分为两类:
- 类DB型的
根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性;
- 类snowflake型
是将64位划分为不同的段,每段代表不同的涵义,时间戳、机器ID和序列数等
UUID
数据库分片法
Redis
Snowflake
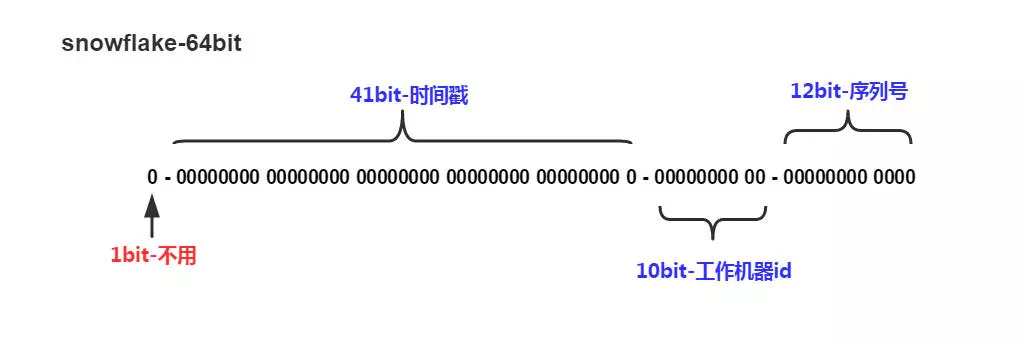
- 41bit时间戳:这里采用的就是当前系统的具体时间,单位为毫秒
- 10bit工作机器ID(workerId):每台机器分配一个id,这样可以标示不同的机器,但是上限为1024,标示一个集群某个业务最多部署的机器个数上限
- 12bit序列号(自增域):表示在某一毫秒下,这个自增域最大可以分配的bit个数,在当前这种配置下,每一毫秒可以分配2^12个数据,也就是说QPS可以到 409.6 w/s。
https://cloud.tencent.com/developer/news/678423
美团Leaf

若有收获,就点个赞吧
0 人点赞
