完整的分布式服务,除了能够利用RPC调用远程服务,还有更多问题需要解决
- 多个相同服务如何管理
- 服务的注册发现机制
- 如何实现负载均衡、路由等集群功能
- 熔断、限流、降级等治理能力
- 重试策略
- 高可用、性能监控
分布式服务化结构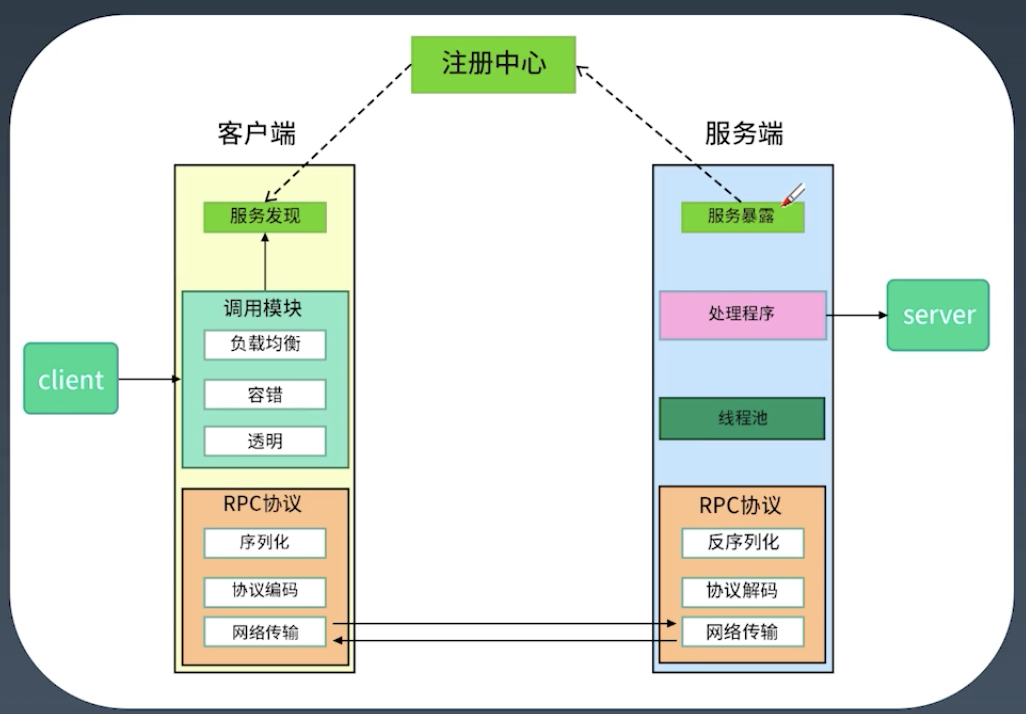
分布式服务需要考虑的问题
- 多个相同服务如何管理?
- 服务的发现注册机制
- 负载均衡、路由、集群
- 熔断、限流、降级
- 心跳、重试
- 高可用、监控、性能等
Dubbo开发时最佳实践
开发分包
将服务接口、服务模型、服务异常等放在API包。
因为服务模型和异常也是API的一部分,这样做也符合分包原则:重用发布等价原则(REP) 共同重用原则(CRP)
服务接口尽可能大力度
每个服务方法代表一个功能,而不是某个功能的一个步骤,否则将面临分布式事务问题
服务接口建议以业务场景为划分单位
对相近的业务做抽象,防止接口过多
不使用过于抽象的接口定义
如 Map query(Map),这种没有明确语意的,非常难维护
参数配置
通用参数以consumer端为准,如果consumer端没有设置,使用provider数值
容器化部署
容器内提供使用的IP,如果注册到zk,消费者无法访问
解决一:docker 使用宿主机网络
docker xxx -net xxxx
解决二:docker参数指定注册的IP和端口 ,-e
DUBBO IP TO REGISTRY-注册到注册中心的 IP 地址
DUBBO PORT TO REGISTRY-注册到注册中心的端口
DUBBO IP TO BIND-监听 IP 地址
DUBBO PORT TO BIND-监听端口
运维与监控
Dubbo Admin功能较简单
可观测性,从以下三点入手:
tracing 链路跟踪:skywalking zipkin等
metrics 指标监控
logging 日志分析
分布式事务
XA - Dubbo不支持
- Seata
- hmliy+Dubbo
重试与幂等
服务调用失败会默认重试2此,如果接口不是幂等的,会造成业务重复
如何设计幂等接口?
- 去重
bitmap
- 乐观锁机制
分布式服务组成
| 配置中心 | 注册中心 | 元数据中心 |
|---|---|---|
| 都需要保存/读取数据/状态,变更通知 | ||
| 全局非业务参数 | 运行期临时状态数据 | 业务模型 |
配置中心
注册中心
管理系统的服务注册、提供发现和协调能力
如何让消费者能动态知道生产者集群的状态变化?
扩展:如何实现xx中心
两个核心要素:
- 需要有存取数据的能力(特别是临时数据)
- 需要有数据变化实时通知机制,全量或增量
zookeeper并不是注册中心,而是注册中心的基座;需要框架(如dubbo)基于zookeeper实现,才能构成完整的配置中心、注册中心。 可作为基座的还有etcd、Nacos、Apollo
服务注册与发现
集群与路由
路由
负载均衡
Random 随机(可带权重)
随机选择,
RoundRobin 轮询
LeastActive 最少活跃
给处理块的机器分配更多的请求,是所有机器达到平衡
ConsistentHashLoadBalance 一致性哈希
过滤与流控
为什么需要流量控制?Flow Control
系统的容量有限,需要保持部分服务能力是最佳选择,然后在问题解决后再恢复正常状态。
需要流控的本质原因是,随着流量增加,输入请求大于处理能力。
流量控制与拥塞控制的区别?
拥塞控制是用于网络的,防止过多的数据注入网络,避免出现网络负载过大。
常用方式:慢开始、避免拥塞;快重传、快恢复
流量控制用于与接受者,控制发送者的发送速度从而是接受者来得及接受、处理,防止分组丢失
服务流控的手段有三个级别,严重程度依次加重
- 限流
- 降级
- 过载保护
1. 限流
限制资源使用的次数或者数量
常用限流算法:
- 计数器
- 滑动窗口
- 令牌桶算法
- 漏桶算法
2. 服务降级
去掉非必要的业务逻辑,只保留核心逻辑
3. 过载保护
系统短时间内不提供新的业务处理服务,挤压处理完后再 恢复输入请求

若有收获,就点个赞吧
0 人点赞
