安装Redis
redis.conf详解
#修改为守护模式daemonize yes#设置进程锁文件pidfile /usr/local/redis-3.2.8/redis.pid#端口port 6379#客户端超时时间timeout 300#日志级别loglevel debug#日志文件位置logfile /usr/local/redis-3.2.8/log-redis.log#设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库iddatabases 16##指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合#save <seconds> <changes>#Redis默认配置文件中提供了三个条件:save 900 1save 300 10save 60 10000#指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,#可以关闭该#选项,但会导致数据库文件变的巨大rdbcompression yes#指定本地数据库文件名dbfilename dump.rdb#指定本地数据库路径dir /usr/local/redis-3.2.8/db/#指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能#会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有#的数据会在一段时间内只存在于内存中appendonly no#指定更新日志条件,共有3个可选值:#no:表示等操作系统进行数据缓存同步到磁盘(快)#always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)#everysec:表示每秒同步一次(折衷,默认值)appendfsync everysec
使用 Homebrew 安装 Redis
1、没有安装 Homebrew,首先安装 npm 国内的吧,快一些。
打开终端输入以下命令:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
2、使用 Homebrew 安装命令
brew install redis
执行上述命令后出现以下,则成功安装:
==> Downloading https://mirrors.ustc.edu.cn/homebrew-bottles/bottles/redis-6.0.1
######################################################################## 100.0%
==> Pouring redis-6.0.1.mojave.bottle.tar.gz
==> Caveats
To have launchd start redis now and restart at login:
brew services start redis
Or, if you don't want/need a background service you can just run:
redis-server /usr/local/etc/redis.conf
==> Summary
🍺 /usr/local/Cellar/redis/6.0.1: 13 files, 3.7MB
3、 查看安装及配置文件位置
- Homebrew 安装的软件会默认在
/usr/local/Cellar/路径下 - redis 的配置文件
redis.conf存放在/usr/local/etc路径下
4、启动 redis 服务
//方式一:使用brew帮助我们启动软件
brew services start redis
//方式二,指定配置文件
redis-server /usr/local/etc/redis.conf
//执行以下命令
redis-server
5、查看 redis 服务进程
我们可以通过下面命令查看 redis 是否正在运行
ps axu | grep redis
6、redis-cli 连接 redis 服务
redis 默认端口号 6379,默认 auth 为空,输入以下命令即可连接
redis-cli -h 127.0.0.1 -p 6379
7、启动 redis 客户端,打开终端并输入命令 redis-cli。该命令会连接本地的 redis 服务。
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> PING
PONG
在以上实例中我们连接到本地的 redis 服务并执行 PING 命令,该命令用于检测 redis 服务是否启动。
8、关闭 redis 服务
- 正确停止 Redis 的方式应该是向 Redis 发送 SHUTDOWN 命令
redis-cli shutdown
- 强行终止 redis
sudo pkill redis-server
9、redis.conf 配置文件详解
redis 默认是前台启动,如果我们想以守护进程的方式运行(后台运行),可以在 redis.conf 中将daemonize no, 修改成yes即可。
使用docker 安装redis
默认会在 6379 端口启动数据库。
$ docker run --name some-redis -d -p 6379:6379 redis
另外还可以启用 持久存储。
$ docker run --name some-redis -d -p 6379:6379 redis redis-server --appendonly yes
默认数据存储位置在 VOLUME/data。
可以使用 —volumes-from some-volume-container 或 -v /docker/host/dir:/data 将数据存放到本地。
使用其他应用连接到容器,可以用
$ docker run --name some-app --link some-redis:redis -d application-that-uses-redis
或者通过 redis-cli
$ docker run -it --rm \
--link some-redis:redis \
redis \
sh -c 'exec redis-cli -h "$REDIS_PORT_6379_TCP_ADDR" -p "$REDIS_PORT_6379_TCP_PORT"'
简介
字符串String
字符串类型是 Redis 最基础的数据结构,键都是字符串类型,而且其他几种数据结构都是在字符串类型 的基础上构建的。字符串类型的值可以实际可以是字符串(简单的字符串、复杂的字符串如 JSON、 XML)、数字(整形、浮点数)、甚至二进制(图片、音频、视频),但是值最大不能超过 512 MB。
string 的内部编码
int:8 个字节的长整形
embstr:小于等于 39 个字节的字符串
raw:大于 39 个字节的字符串
哈希Hash
哈希类型指键值本身又是一个键值对结构,哈希类型中的映射关系叫 field-value,这里的 value 是指 field 对于的值而不是键对于的值。
- hash 的内部编码
ziplist 压缩列表:当哈希类型元素个数和值小于配置值(默认 512 个和 64 字节)时会使用 ziplist 作为 内部实现,使用更紧凑的结构实现多个元素的连续存储,在节省内存方面比 hashtable 更优秀。
hashtable 哈希表:当哈希类型无法满足 ziplist 的条件时会使用 hashtable 作为哈希的内部实现,因为 此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度都为 O(1)。
- hash 的应用场景
缓存用户信息,每个用户属性使用一对 field-value,但只用一个键保存。
优点:简单直观,如果合理使用可以减少内存空间使用。
缺点:要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,hashtable 会消耗更多内存。
列表List
- 列表从左至右排列,左边为头部
- 可以用List实现队列、栈
实现方式
基于跳表实现
应用场景
String:缓存、限流、计数器、分布式锁、分布式Session
Hash:存储用户信息、用户主页访问量、组合查询
List:微博关注人时间轴列表、简单队列
Set:赞、踩、标签、好友关系
Zset:排行榜
7种Redis底层数据结构
SDS 简单动态字符串
是一个C语言结构体,有四个参数:
- len:SDS字符串长度
- alloc:buf数组中没有使用的自己数量,如果alloc值为0,则表示没有为此SDS分配使用空间
- flags:标志位
- bug[ ]:char类型数组,保存字符串
链表 linkedlist
- 实现
每个节点用一个listNode结构表示,包含前节点prev、后节点next、当前值value - 特点
- 双向
- 链表节点可以保存多种类型
- 应用
- Ziplist 是为了节约内存空间而开发出的。
- 压缩列表 ziplist 是列表键和哈希键的底层实现之一。
- 当列表键的元素 或 哈希键的键和值是小整数值、短字符串时,Redis会使用压缩列表来实现 list 或 hash
实现:
由 header + entries + end 三部分组成
其中entry是真正存储节点数据的部分。
entry由三部分组成:
- Prevrawlen:前一个节点占用字节数,通过该值可以计算得到前一个节点的地址
- prevrawlen是变长编码
- 前一节点的值小于254字节时,prevrawlen长度为1字节
- 前一节点的值大于254字节时,prevrawlen长度为5字节
- encoding:当前节点content属性所保存的数据的类型及长度
- content:保存压缩列表节点的值,可以是一个整数也可以是一个字节数组
由于prevrawlen是变长编码,所以当数据更新时可能会引发连锁更新
ziplist将数据按照一定规则编码在一块连续的内存区域,目的是节省内存,这种结构并不擅长做修改操作。
area |<—— ziplist header ——>|<—————- entries ——————->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+————-+————+———-+————+————+————+————+———-+
component | zlbytes | zltail | zllen | entry1 | entry2 | … | entryN | zlend |
+————-+————+———-+————+————+————+————+———-+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL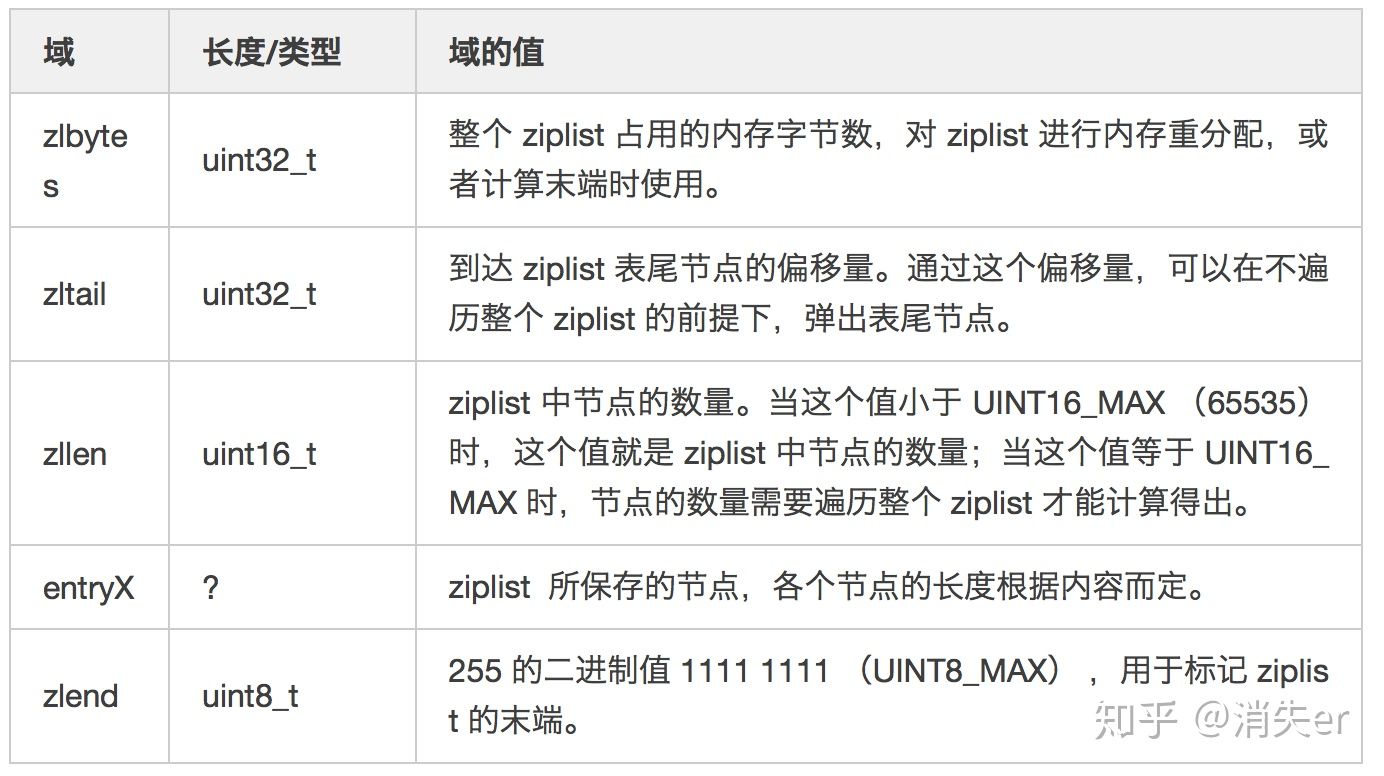
快速列表 quicklist
Redis3.2新引入快速列表用于列表的底层实现。
快速列表是由压缩列表组成的双向链表,链表的每个节点都以压缩列表的结构来保存数据。
quickList就是一个标准的双向链表的配置,有head 有tail;
每一个节点是一个quicklistNode,包含prev和next指针。
每一个quicklistNode 包含 一个ziplist,*zp 压缩链表里存储键值。
所以quicklist是对ziplist进行一次封装,使用小块的ziplist来既保证了少使用内存,也保证了性能。
字典
Redis数据库底层是用字典实现的,当Redis哈希包含的键值对较多、或键值对元素较长时,Redis会采用字典作为哈希键的底层实现
整数集合inset
当一个集合set只包含整数值元素、且这个集合中的元素数量不是太多时,Redis会采用整数集合来实现这个集合
跳表
3种特殊数据类型
HyperLogLog
- 2.8.9版本中新增结构
- 用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
- 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
- 只统计基数,不存储元素
- 什么是基数?
基数就是一个集合中,不重复元素的个数
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。
- 应用:
- 统计网站UV(网站访问人数,一个人多次访问,算一个人)GEO
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
GEO基于有序集合 Zset 实现
Redis GEO 操作方法有: - geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。Bitmaps 位图
统计用户信息:是否活跃、打卡信息bitmap
Redis事务
- Redis事务的本质:一组命令的集合。
- Redis事务没有隔离性
事务执行过程
- 开启事务(multi)
- 命令入队
- 执行事务(exec)
其他命令:
discard :放弃事务
watch:监视命令
事务异常:
- 编译异常:如果命令语法有问题,如拼写错误、参数个数不对、参数顺序错误, 命令入队时会失败,会导致所有命令都无法执行
- 运行异常:如果是命令逻辑有问题,运行时出现错误,则只有错误命令无法执行,其他没问题的命令可以执行
ps:关于运行异常,例如对int类型的参数执行incr(自增1操作),这条命令会报错,但不影响其他命令的执行。
因为Redis事务不支持回滚,即使某一条命令执行失败,事务也会继续执行下去
事务的watch命令
- 用watch监视一个或多个建,开启事务后,在exec执行事务前,服务器会检查被监视的键是否被修改,如果被修改过,则事务将无法执行。
- Exec命令执行后,不管事务是否执行成功,watch命令都会取消监视所有的数据库键
Redis消息订阅

若有收获,就点个赞吧
0 人点赞
