介绍
主要功能
Apache ZooKeeper是由群集(组节点)之间进行相互协调,并保持强大的同步技术共享数据的服务。ZooKeeper本身是一个分布式应用写入分布式应用提供服务。
ZooKeeper 提供的通用服务如下:
- 命名服务 − 确定在一个集群中的节点的名字。它类似于DNS,只不是过节点。
- 配置管理 − 系统最近加入节点和向上最新配置信息。
- 集群管理 − 加入/节点的群集和节点状态实时离开。
- 节点领导者选举 − 选举一个节点作为领导者协调的目的。
- 锁定和同步服务 − 锁定数据,同时修改它。这种机制可以帮助自动故障恢复,同时连接其它的分布式应用程序。如Apache HBase。
- 高可靠的数据注册表 − 一个或几个节点的可用性的数据向下
典型应用场景
- 配置管理
- DNS服务
- 组成员管理
- 分布式锁
zookeeper适用于存储和协同相关的关键数据,不适合用于大数据存储
安装
本地安装
zkServer.sh startgrep -E -i "((exception)|(error))" *netstat -an | ag 2181
docker安装
基础
Zookeeper数据模型
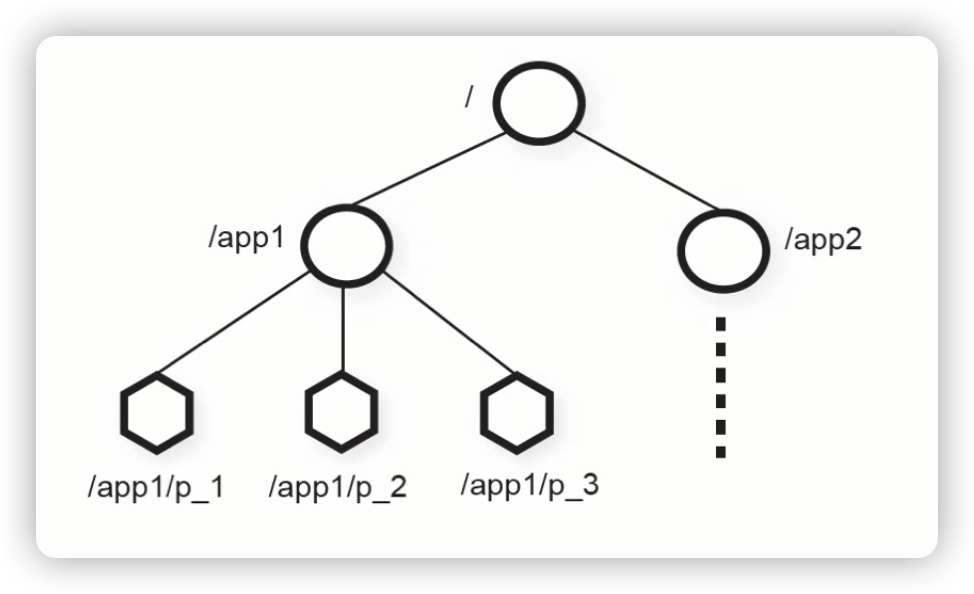
znode
节点分类
按持久性分类
- 持久性znode (persistent):ZooKeeper集群宕机或者client宕机重启后不会丢失
- 临时性znode (ephemeral):client宕机或者client在指定的timeout时间内没有给ZooKeeper集群发消息,这样的znode会消失
znode的顺序性,每一个顺序性znode关联一个唯一的单调递增整数,这个整数时顺序性znode名字的后缀
持久性结合顺序性,又有以下两种znode
- 持久顺序性znode
- 临时顺序性znode
节点特性
1、同一级节点 key 名称是唯一的
2、创建节点时,必须要带上全路径
3、session 关闭,临时节点清除
4、可创建顺序节点(create -s)
5、watch 机制,监听节点变化
6、delete 命令只能一层一层删除
(新版本可以通过 deleteall 命令递归删除。)
基于节点以上特性,可以实现很多功能
- 数据发布/订阅
- 负载均衡
- 分布式协调/通知
- 集群管理
- 分布式锁
- 分布式队列
节点存储的信息
每个 ZNode 节点在存储数据的同时,都会维护一个叫做 Stat 的数据结构,里面存储了关于该节点的全部状态信息。如下:
| 状态属性 | 说明 |
|---|---|
| czxid | 数据节点创建时的事务 ID |
| ctime | 数据节点创建时的时间 |
| mzxid | 数据节点最后一次更新时的事务 ID |
| mtime | 数据节点最后一次更新时的时间 |
| pzxid | 数据节点的子节点最后一次被修改时的事务 ID |
| cversion | 子节点的更改次数 |
| version | 节点数据的更改次数 |
| aversion | 节点的 ACL 的更改次数 |
| ephemeralOwner | 如果节点是临时节点,则表示创建该节点的会话的 SessionID;如果节点是持久节点,则该属性值为 0 |
| dataLength | 数据内容的长度 |
| numChildren | 数据节点当前的子节点个数 |
cli操作zookeeper
// 查看节点
查看
ls /
-w 添加一个 watch(监视器)
// 创建节点
默认创建永久性、无序节点
create /app1
// 创建临时性节点
create -e /lock
-s 创建有序节点
-e 创建临时节点
// 获取节点
get [-s] [-w] path
-s 获取详情
-w 监视
// 检查状态 stat
stat [-w] path
-w 添加一个 watch(监视器)
如果节点内容发生改变,会产生 NodeDataChanged 事件;
如果删除节点,会产生 NodeDeleted 事件。
与 get 的区别是,不回列出 znode 的值。
修改节点 set
set [-s] [-v version] path data
不加version的话,就在最新版本上修改,
history 列出最近的10条历史记录
重复之前的命令 redo
redo cmdno
cmdno 是命令编号
zookeeper模拟一个简单的分布式锁
Session
ZooKeeper客户端和集群中的某个节点创建一个session。
- 客户端可以主动关闭session
- 节点如果在一定时间内没有收到客户端的消息,也可以主动关闭session
- ZooKeeper客户端如果发现连接的节点出错,会自动和其他节点建立连接
Watch 机制
watch机制,可以监控节点变化,这个变化包括 节点自身内容的变化、节点的删除、子节点的删除、增加等。
包括两个角色、四个步骤
- 客户端注册watcher
- 服务端处理watcher
- 服务端出发watcher
- 客户端回调响应
示例:
public class TestWatch implements Watcher {
static ZooKeeper zooKeeper;
static {
try {
System.out.println("初始化zk");
zooKeeper = new ZooKeeper("127.0.0.1:2181", 10000, new TestWatch());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void process(WatchedEvent event) {
System.out.println(Thread.currentThread().getName()+"=============="+"eventType:" + event.getType());
try {
if (event.getType() == Event.EventType.NodeDataChanged) {
// 监听节点内容改变
System.out.println(Thread.currentThread().getName()+"=============="+"event.getType()==Event.EventType.NodeDataChanged");
zooKeeper.exists(event.getPath(), true);
}else if (event.getType() == Event.EventType.NodeDeleted){
// 监听节点删除
System.out.println(Thread.currentThread().getName()+"=============="+"event.getType()==Event.EventType.NodeDeleted");
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
String path = "/watcher";
Stat exists = zooKeeper.exists(path, false);
if (exists == null) {
zooKeeper.create(path, "0".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
Thread.sleep(1000);
System.out.println("-----------");
//true表示使用zookeeper实例中配置的watcher,也可以调用其他方法单独注册watch
Stat stat = zooKeeper.exists(path, true);
// 另外启一个线程,计时3秒后删除/watcher, 主线程会受到删除通知。也可以直接在命令行操作节点
new Thread(() -> {
try {
for (int i = 0; i < 3; i++) {
System.out.println(Thread.currentThread().getName()+"=============="+(i+1));
Thread.sleep(1000);
}
zooKeeper.delete(path,-1);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}).start();
// 在控制台输出监听回调process方法里的内容
System.in.read();
}
}
原理
客户端发送请求给服务端是通过 TCP 长连接建立网络通道,底层默认是通过 java 的 NIO 方式,也可以配置 netty 实现方式。
参考:ZooKeeper watch机制【菜鸟教程】
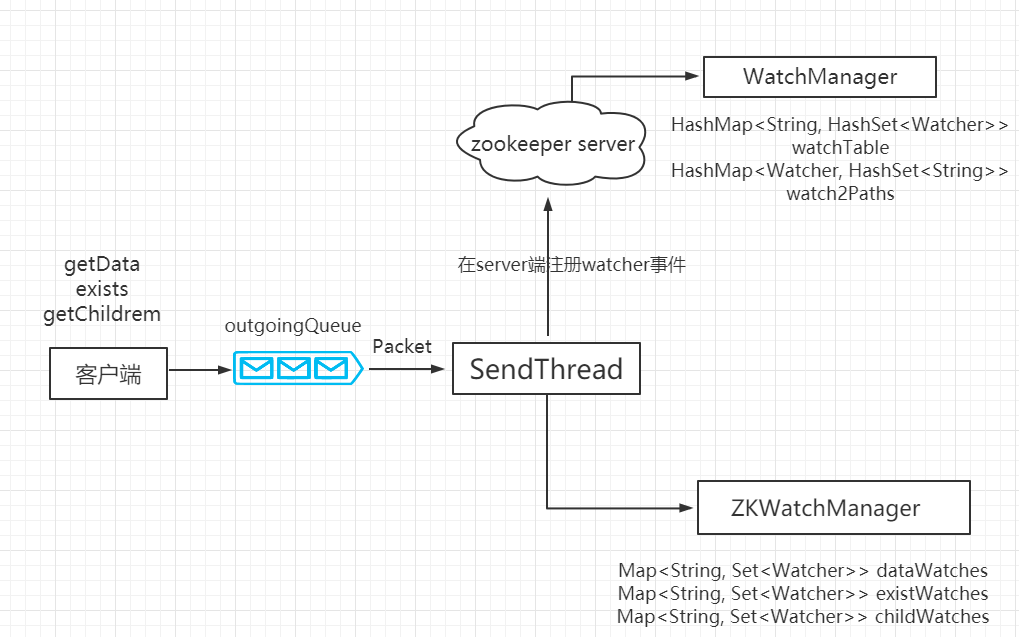
watch机制的应用
配置中心
把诸如数据库配置项这样的信息存储在 ZooKeeper 数据节点中。服务器集群客户端对该节点添加 Watch 事件监控,当集群中的服务启动时,会读取该节点数据获取数据配置信息。而当该节点数据发生变化时,「ZooKeeper 服务器会发送 Watch 事件给各个客户端(推」),集群中的客户端在接收到该通知后,「重新读取节点的数据库配置信息(拉)」
注册中心
Dubbo 支持多种注册注册中心,其中ZooKeeper作为注册中心是Dubbo默认推荐实现。
ZooKeeper作为注册中心,实现的是CP理论,与之对比的是Eureka的AP设计。
数据一致性
全局可线性 写入:先到达leader的写请求先被处理,leader决定写请求的执行顺序
客户端FIFO顺序:来自给定客户端的请求按照发送顺序执行
ZooKeeper集群
有两种模式:
standalone模型:只有一个独立的ZooKeeper节点
quorum模式:包含多个ZooKeeper节点
1个leader + 多个follower节点
消息顺序性
Zookeeper集群中是读写分离的,只有Leader节点能处理写请求,如果Follower节点接收到了写请求,会将该请求转发给Leader节点处理,Follower节点自身是不会处理写请求的。
Leader节点接收到消息之后,会严格按照请求的顺序的进行处理,并且在全局都是这个顺序,其他的节点也都是按顺序收到消息。这是ZooKeeper的一大特点之一
如何保证顺序性?
每个节点都有zxid(事务id),把zxid理解成Zookeeper中消息的唯一ID,节点之间会通过发送Proposal(事务提议)来进行通信、数据同步,proposal中就会带上zxid和具体的数据(Message)
消息有三种zxid:
cZxid 创建节点时的事务ID
mZxid 最后修改节点时的事务ID
pZxid 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是 修改子节点的数据内容则不影响该ID(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更 不会影响pzxid)
zxid由64位组成,
高32位epoch:Epoch周期数,值为最新的领导的对应的i
低32位counter:计数器,一个递增的计数器,当处理了一个事务,值+1
ZAB协议
消息广播 Broadcast
ZooKeeper集群中,Leader节点负责写数据,Follower节点负责读数据,如果Follower节点收到写请求会转发给Leader处理,Leader处理写请求后会将数据同步给各个Follower节点。这里用到的就是ZAB协议的广播模式。
事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的Follower 服务器进行正确的 ACK 反馈,那么Leader就会再次向所有的 Follower 服务器发送commit 消息,将此次提案进行提交。这个过程可以简称为 2pc 事务提交,整个流程可以参考下图。 注意 Observer 节点只负责同步 Leader 数据,不参与 2PC 数据同步过程。
两阶段提交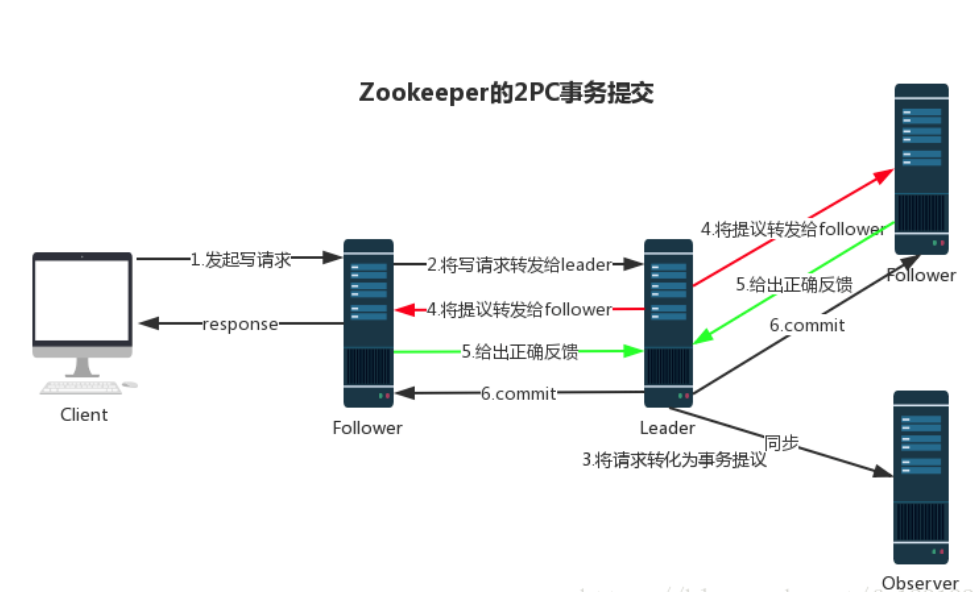
Zab协议既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性。它依靠事务ID和版本号,保证了数据的更新和读取是有序的。
崩溃恢复
在正常情况消息广播情况下能运行良好,但是一旦 Leader 服务器出现崩溃,或者由于网络原理导致 Leader 服务器失去了与过半 Follower 的通信,那么就会进入崩溃恢复模式,需要选举出一个新的 Leader 服务器。在这个过程中可能会出现两种数据不一致性的隐患,需要 ZAB 协议的特性进行避免。
- 1、Leader 服务器将消息 commit 发出后,立即崩溃
- 2、Leader 服务器刚提出 proposal 后,立即崩溃
选举机制
每个节点都有的参数:
- 服务器 ID(myid):编号越大在选举算法中权重越大
- 事务 ID(zxid):值越大说明数据越新,权重越大
- LOOKING: 竞选状态
- FOLLOWING: 随从状态,同步 leader 状态,参与投票
- LEADING: 领导者状态(表示已被选为Leader)
- OBSERVING: 观察状态,同步 leader 状态,不参与投票
参考:https://www.runoob.com/w3cnote/zookeeper-leader.html
ZooKeeper实现分布式锁
分布式锁
基本原理
节点
curator实现
curator-recipes的几种锁方案
- InterProcessMutex:分布式可重入排它锁
- InterProcessSemaphoreMutex:分布式排它锁
- InterProcessReadWriteLock:分布式读写锁
�

若有收获,就点个赞吧
0 人点赞
