I/O
从文件的传输说起
传统模式下的文件传输
服务端MyServer
public class MyServer {public static void main(String[] args) throws IOException {// 服务器地址:127.0.0.1:8888ServerSocket server = new ServerSocket(8888);// 允许接收多个客户端连接while (true){// 一直阻塞,直到有客户端发来连接Socket socket = server.accept();// 起一个线程处理客户端连接传输文件new Thread(new SendFile(socket)).start();}}}
处理逻辑
public class SendFile implements Runnable{
private Socket socket;
public SendFile(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
System.out.println("连接成功");
OutputStream out = null;
FileInputStream fileIn = null;
try {
// fileIn 用于将硬盘文件读入内存
File file = new File("/Users/sky-mbp16/Pictures/2020-08-02 00.33.14.jpg");
fileIn = new FileInputStream(file);
// out用于将内存里的文件,远程发送到客户端
out = socket.getOutputStream();
byte[] bs = new byte[128];
int len = -1;
while ((len=fileIn.read(bs))!=-1){
out.write(bs,0,len);
}
fileIn.close();
out.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
}
}
}
客户端
public class MyClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
// in,用于接受服务端远程发来的文件,并将文件保存在内存中
InputStream in = socket.getInputStream();
byte[] bs = new byte[128];
int len = -1;
File newFile = new File("/Users/sky-mbp16/CODING/FILE_UP_LOAD/xyz1.jpg");
if (!newFile.exists()){
if (!newFile.getParentFile().exists() ){
newFile.getParentFile().mkdirs();
}
}
// 将内存中的文件保存在客户端本地硬盘
FileOutputStream fileOut = new FileOutputStream(newFile);
while ((len = in.read(bs)) != -1){
fileOut.write(bs,0,len);
}
System.out.println("文件接受成功");
fileOut.close();
in.close();
socket.close();
}
}
以上程序执行步骤
- 将硬盘文件读入内存,使用输入流(InputStream或Reader)
- 将内存中的文件输出到硬盘,使用输出流(OutputStream或Writer)
- 内存中的文件,远程发送给另一个计算机,使用socket.getOutputStream()
- 接收远程发来的文件,保存在本地,使用socket.getInputSteam()
传统IO缺点:
- 数据以阻塞的方式传输。服务端在接收客户端请求时,勇士的server.accept()方法会一直阻塞,直到有客户端发来请求。
- 服务端每次收到新的连接,都会创建一个新的线程(线程是比较重的资源,创建线程本省也比较耗费资源)
NIO
NIO, non-blocking io, 非阻塞IO
传统I/O是阻塞式IO、面向流的操作;NIO是非阻塞IO、面向通道 Channel 和缓冲区 Buffer的操作。
NIO主要涉及三个新概念:缓冲区Buffer、通道Channel、选择器Selector。
学习NIO前需要了解操作系统 内核空间与用户空间,内核态与用户态相关概念:
从根上理解用户态与内核态 - SegmentFault 思否
零拷贝
使用非直接缓冲区的复制
使用非直接缓冲区操作文件输入,在内核空间和用户空间之间一共要进行4次数据文件的复制,要在内核态和用户态之间切换4次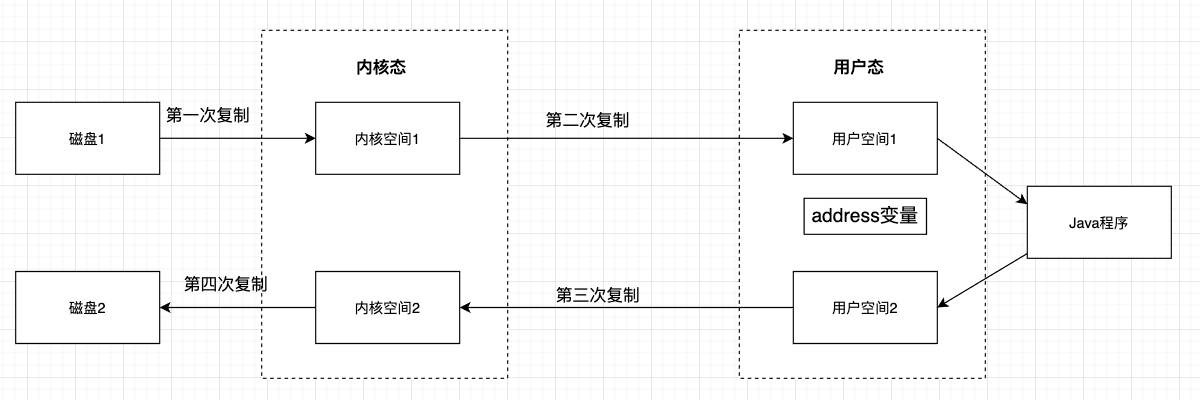
//使用直接缓冲区复制文件
public static void test2_2() throws IOException{
long start = System.currentTimeMillis();
FileInputStream input= new FileInputStream("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test.mp4");
FileOutputStream out= new FileOutputStream("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test copy2.mp4");
//获取通道
FileChannel inChannel = input.getChannel() ;
FileChannel outChannel = out.getChannel() ;
// 创建直接缓冲区
ByteBuffer buffer = ByteBuffer.allocateDirect(1024) ;
while(inChannel.read(buffer) != -1){
buffer.flip() ;
outChannel.write(buffer );
buffer.clear() ;
}
if(outChannel!=null) outChannel.close();
if(inChannel!=null) inChannel.close();
if(out!=null) out.close();
if(input!=null) input.close();
long end = System.currentTimeMillis();
System.out.println("复制操作消耗的时间(毫秒):"+(end-start));
}
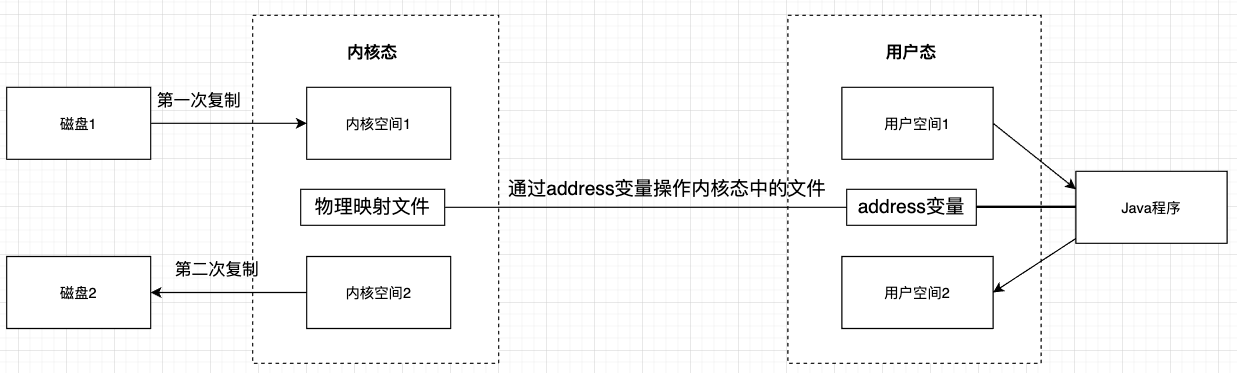
使用直接缓冲区实现零拷贝
JVM中通过一个address变量指向OS中的一块内存(物理映射文件),这样通过JVM使用OS中的内存。
避免了内核空间和用户空间之间的复制,数据的复制操作只发生在内核空间。
用户空间和内核空间之间的复制次数为 0,这就是零拷贝。
// 在直接缓冲区,使用内存映射文件,完成复制
public static void test3() throws IOException{
long start = System.currentTimeMillis();
//用文件的输入通道
FileChannel inChannel
= FileChannel.open(Paths.get("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test.mp4"), StandardOpenOption.READ);
//用文件的输出通道
FileChannel outChannel = FileChannel.open(Paths.get("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test3.mp4"),
StandardOpenOption.WRITE,
StandardOpenOption.READ,
StandardOpenOption.CREATE);
//输入通道和输出通道之间的内存映射文件(内存映射文件处于堆外内存中)
MappedByteBuffer inMappedBuf = inChannel.map(FileChannel.MapMode.READ_ONLY, 0, inChannel.size());
MappedByteBuffer outMappedBuf = outChannel.map(FileChannel.MapMode.READ_WRITE, 0, inChannel.size());
//直接对内存映射文件进行读写
byte[] dst = new byte[inMappedBuf.limit()];
inMappedBuf.get(dst);
outMappedBuf.put(dst);
inChannel.close();
outChannel.close();
long end = System.currentTimeMillis();
System.out.println("复制操作消耗的时间(毫秒):"+(end-start));
}
使用文件描述符实现零拷贝
文件描述符: 内核空间中的一个缓冲区,用于记录文件大小与内存地址
只需要一次复制:
- 将磁盘文件复制到内核空间,并用文件描述符记录文件大小和内存位置
- 将文件描述符复制到输出缓冲区,根据文件描述符找到文件内容并输出到目标磁盘
(文件描述符与文件内容的协同工作,需要操作系统底层支持scatter-and-gather功能)
//在直接缓冲区中,将输入通道的数据直接转发给输出通道(零拷贝)
public static void test4() throws IOException{
long start = System.currentTimeMillis();
FileChannel inChannel = FileChannel.open(Paths.get("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test.mp4"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("/Users/sky-mbp16/CODING/FILE_UP_LOAD/test copy4.mp4"), StandardOpenOption.WRITE, StandardOpenOption.READ, StandardOpenOption.CREATE);
// 将输入通道的文件转发到目标输出通道
inChannel.transferTo(0, inChannel.size(), outChannel);
/*
也可以使用输出通道完成复制,即上条语句等价于以下写法:
outChannel.transferFrom(inChannel, 0, inChannel.size());
*/
inChannel.close();
outChannel.close();
long end = System.currentTimeMillis();
System.out.println("复制操作消耗的时间(毫秒):"+(end-start));
}
文件加锁
FileChannel中提供了lock方法对文件加锁,可以对文件加共享锁或独占锁。
共享锁
public class FileLockTest {
public static void main(String[] args) throws FileNotFoundException, IOException, InterruptedException {
RandomAccessFile raf = new RandomAccessFile("d:/abc.txt", "rw");
FileChannel fileChannel = raf.getChannel();
/**
* 将abc.txt中position=2,size=4的内容加锁(即只对文件的部分内容加了锁)。
* lock()第三个布尔参数的含义如下:
* true:共享锁。实际上是指“读共享”:某一线程将资源锁住之后,其他线程既只能读、不能写该资源。
* false:独占锁。某一线程将资源锁住之后,其他线程既不能读、也不能写该资源。
*/
//①
/**
* true:共享锁
* false:独占锁
*/
FileLock fileLock = fileChannel.lock(2, 4, true);
System.out.println("main线程将abc.txt锁3秒...");
new Thread(
() -> {
try {
byte[] bs = new byte[8];
//②新线程对abc.txt进行读操作
// raf.read(bs,0,8);
//③新线程对abc.txt进行写操作
//raf.write("ccccccccc".getBytes(),0,8);
} catch (Exception ex) {
ex.printStackTrace();
}
}).start();
//模拟main线程将abc.txt锁3秒的操作
Thread.sleep(3000);
System.out.println("3秒结束,main释放锁");
fileLock.release();
}
}
基于零拷贝实现文件的传输


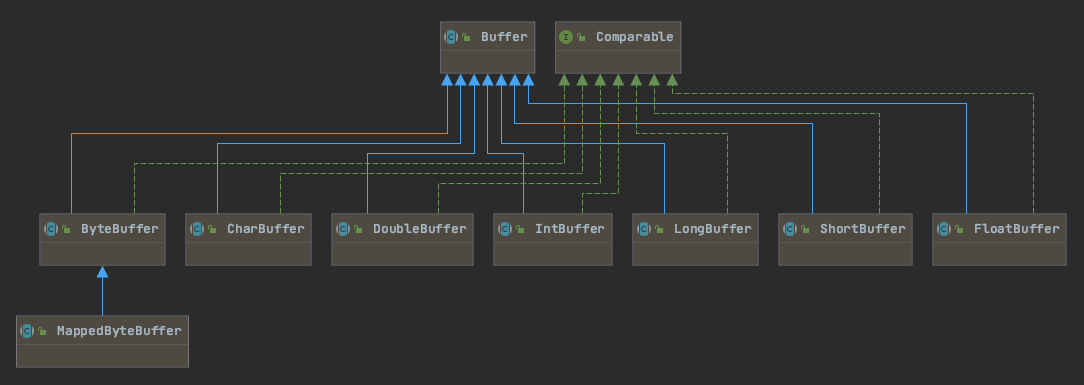
Buffer
Buffer,缓冲区,是线程用来处理数据的内存区域。
- 虽然图中有多种Buffer,但最重要的还是ByteBuffer,其他非字节缓冲区底层还是转换为字节缓冲区。
- MappedByteBuffer,是ByteBuffer专门用于内存映射文件的一种特例
缓冲区的属性
- positon
- limit
- capacity
- mark

缓冲区的方法
- put()
- get()
- flip()
从写状态转换为读状态,调用flip()方法,以便后续能读出position至limit之间的数据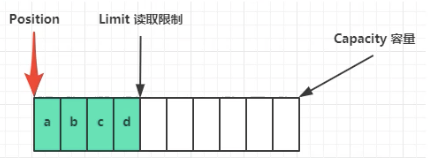
- rewind()
从头开始读缓冲区
将position置为0,limit置为数据区的大小
- clear()
切换为写模式,将position置为0,limit置为capcity,可以从头写入
- compact()
把未读完的向前压缩,并切换至写模式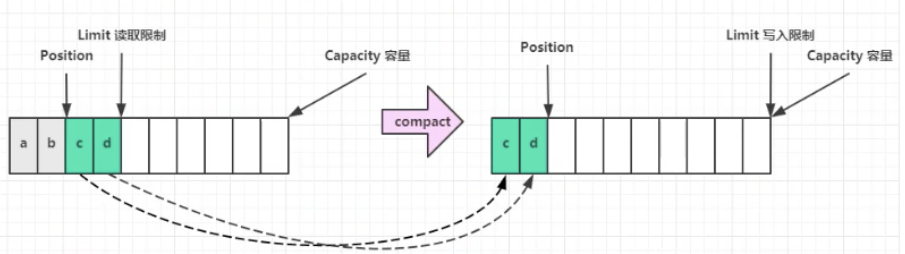
- mark() 与 reset()
mark()做标记,使标记值mark=position
reset()返回标记,使当前位置值position=mark
缓冲区的读取与写入
创建缓冲区
分配
allocate(),创建一个缓冲区对象,并分配一个私有的空间,来存储一定数量的数据元素。
缓冲区分配好后,空间大小不可变
// 直接创建一个
ByteBuffer heapBuffer = ByteBuffer.allocate(10);
ByteBuffer directBuffer = ByteBuffer.allocateDirect(10);
position: [0], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 00 00 00 00 00 00 00 |.......... |
+--------+-------------------------------------------------+----------------+
allocate() allocateDirect()比较
- allocate(),返回的是堆内存,堆内存受JVM管控,会有垃圾回收
- allocateDirect(),返回的是直接内存(系统内存)
包装
包装操作,需要传入一个数组,创建一个缓冲区对象,但是不分配空间来存储元素,而是使用传入的数组空间作为缓冲区的存储空间
byte[] bytes = {'a','b','c','d','1','2','3','4'};
ByteBuffer wrapBuffer1 = ByteBuffer.wrap(bytes);
position: [0], limit: [8]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 31 32 33 34 |abcd1234 |
+--------+-------------------------------------------------+----------------+
// 第2、3个参数,为缓冲区对象指定position、limit
ByteBuffer wrapBuffer2 = ByteBuffer.wrap(bytes,2,4);
position: [2], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 31 32 33 34 |abcd1234 |
+--------+-------------------------------------------------+----------------+
复制缓冲区
duplicate()
复制一个缓冲区,与原缓冲区共享内存与元素内容,但自己单独维护一套position、limit
slice()
缓冲区与字符串的转换
// 1.字符串getBytes得到字符数组
ByteBuffer buffer = ByteBuffer.allocate(16);
ByteBufferUtil.debugAll(buffer);
byte[] bytes = "hello".getBytes();
buffer.put(bytes);
ByteBufferUtil.debugAll(buffer);
// 利用charset指定编码转换为String,并且直接切换为读模式
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("hello");
ByteBufferUtil.debugAll(buffer1);
// 同样利用charset可以从Buffer中读出字符串,但是需要注意,decode(Buffer)方法中的参数buffer必须为读模式
String s = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(s);
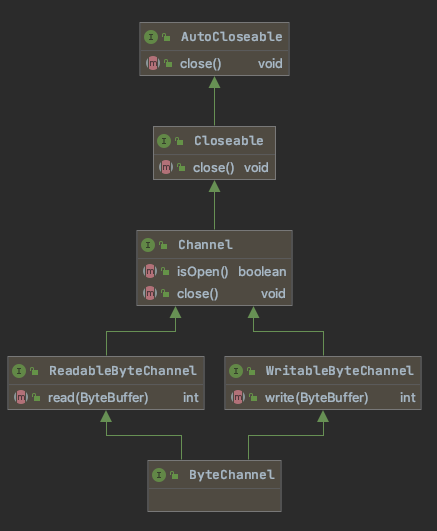
Channel
Buffer缓冲区是数据的载体,Channel通道就是传输数据的通道
通道的基本概念
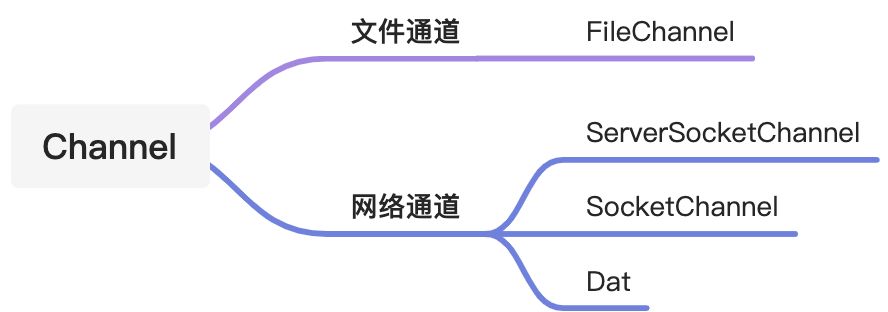
通道的分类
打开通道
如何创建通道?
- socket通道可以通过的.open()方法
- 文件通道只能一个打开的RandomAccessFile/FileInputStream/FileOutputStream对象上调用getChannel()方法来获取。
- 通过 FileInputStream 获取的 channel 只能读
- 通过 FileOutputStream 获取的 channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
实现了
ReadableByteChannel接口的通道,可读; 实现了WritableByteChannel接口的通道,可写; ByteChannel接口本身没有定义新的API方法,它只实现了以上两个接口作为聚集。常用的通道都实现了ByteChannel,所以常用的通道都是可读可写的,可以双向传输数据
使用通道
读取
会从 channel 读取数据填充 ByteBuffer,返回值表示读到了多少字节,-1 表示到达了文件的末尾
int readBytes = channel.read(buffer);
写入
向SocketChannel写入数据
ByteBuffer buffer = ...;
buffer.put(...); // 存入数据
buffer.flip(); // 切换读模式
while(buffer.hasRemaining()) {
channel.write(buffer);
}
在 while 中调用 channel.write 是因为 write 方法并不能保证一次将 buffer 中的内容全部写入 channel
位置信息
- 获取当前位置
long pos = channel.position();
- 设置当前位置
long newPos = ...;
channel.position(newPos);
设置当前位置时,如果设置为文件的末尾
- 这时读取会返回 -1
- 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
强制写入
操作系统处于性能的考虑,会将数据先写入缓存(页缓存)中,而不是立刻写入磁盘。调用force(ture)方法可以将文件内容和元数据(文件的权限信息等)立刻写入磁盘
文件通道
FileChannel
网络通道
ServerSocketChannel
SocketChannel
DatagramChannel
Selector
选择器,也叫多路复用器,一个选择器可以监控多个通道的输入输出情况,提供了特定的API能够选出所监控通道已经就绪的IO操作。通过选择器,⼀个单线程可以处理数百、数千、数万、甚⾄更多的通道,可以大大减小线程间切换的开销。
通道注册至选择器
调用可选择通道的 register( )方法会将它注册到一个选择器上。
register()方法
- register()方法是在
SelectableChannel上,而不是Selector上 SelectableChannel的register方法,返回一个封装了通道与选择器关系的选择键对象SelectionKey- 如果试图注册一个处于阻塞 状态的通道,register( )将抛出未检查的 IllegalBlockingModeException 异常。此外,通道 一旦被注册,就不能回到阻塞状态。试图这么做的话,将在调用 configureBlocking( )方法时将抛出 IllegalBlockingModeException 异常。
- 一个给定的通道可以被注册到多于一或多个选择器上
Selector的键属性
已注册的键(SelectionKey)的集合,通过
keys()方法返回public abstract Set<SelectionKey> keys();已就绪的键的集合,是keys的子集。每个键的通道被选择器在前一个选择操作(select()方法)中判断为已经准备好的并且包含于键的interest集合中的操作。通过selectedKeys()方法
public abstract Set<SelectionKey> selectedKeys();已取消的键的集合,是keys的子集。这个集合包含了
cancel()方法调用的键,键已无效,但还没有被注销。这个集合时选择器对象的私有成员,无法直接访问
Selector的选择方法select()
可以通过下面三种方法来监听是否有事件发生,方法的返回值代表有多少 channel 发生了事件
方法1,阻塞直到绑定事件发生
int count = selector.select();
方法2,阻塞直到绑定事件发生,或是超时(时间单位为 ms)
int count = selector.select(long timeout);
方法3,不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件
int count = selector.selectNow();
处理事件
选择监控的通道事件类型有以下4种:
处理read事件
为ByteBuffer分配大小
- 每个channel都需记录可能被切分的消息,ByteBuffer不能channel共用,每个channel需要维护一个独立的ByteBuffer
- ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现 http://tutorials.jenkov.com/java-performance/resizable-array.html
- 另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
处理write事件
服务器向客户端发送数据
优化
利用多线程优化
- 利用多核cpu的优势,为连接、读写不同的操作创建多个线程
总结
实现了SelectableChannel接口的Channel可以在Selector上注册,register()注册方法返回的是通道与选择器的对应关系对象SelectionKey
Pipe
FileLock
IO模型
同步阻塞(BIO)、同步非阻塞(NIO)、多路复用、信号驱动、异步IO(AIO)

若有收获,就点个赞吧
0 人点赞
