HBase BlockCache系列文章到了终结篇,在SlabCache被早早地淘汰之后,仅剩LRU(LRUBlockCache)和CBC(CombinedBlockCache)。这篇文章主要对比LRU和CBC(offheap模式)分别在四种场景下几种指标(GC、Throughput、Latency、CPU、IO等)的表现情况。四种场景分别是缓存全部命中、大部分缓存命中、少量缓存命中、缓存基本未命中
说明:本文所有图都以时间为横坐标,纵坐标为对应指标。每张图都会分别显示LRU和CBC的四种场景数据,总计八种场景,下面数据表示LRU的四种场景分布在时间段21:36:39~22:36:40,CBC的四种场景分布在时间段23:02:16~00:02:17,看图的时候需要特别注意
LRU: Tue Jul 22 21:36:39 PDT 2014 run size=32, clients=25 ; lrubc time=1200 缓存全部命中 Tue Jul 22 21:56:39 PDT 2014 run size=72, clients=25 ; lrubc time=1200 大量缓存命中 Tue Jul 22 22:16:40 PDT 2014 run size=144, clients=25 ; lrubc time=1200 少量缓存命中 Tue Jul 22 22:36:40 PDT 2014 run size=1000, clients=25 ; lrubc time=1200 缓存基本未命中 CBC: Tue Jul 22 23:02:16 PDT 2014 run size=32, clients=25 ; bucket time=1200 缓存全部命中 Tue Jul 22 23:22:16 PDT 2014 run size=72, clients=25 ; bucket time=1200 大量缓存命中 Tue Jul 22 23:42:17 PDT 2014 run size=144, clients=25 ; bucket time=1200 少量缓存命中 Wed Jul 23 00:02:17 PDT 2014 run size=1000, clients=25 ; bucket time=1200 缓存基本未命中
GC
GC指标是HBase运维最关心的指标,出现一次长时间的GC就会导致这段时间内业务方的所有读写请求失败,如果业务方没有很好的容错,就会出现丢数据的情况出现。根据下图可知,只有在‘缓存全部命中’的场景下,LRU总GC时间25ms比CBC的75ms短;其他三种场景下,LRU表现都没有CBC好,总GC时间基本均是CBC的3倍左右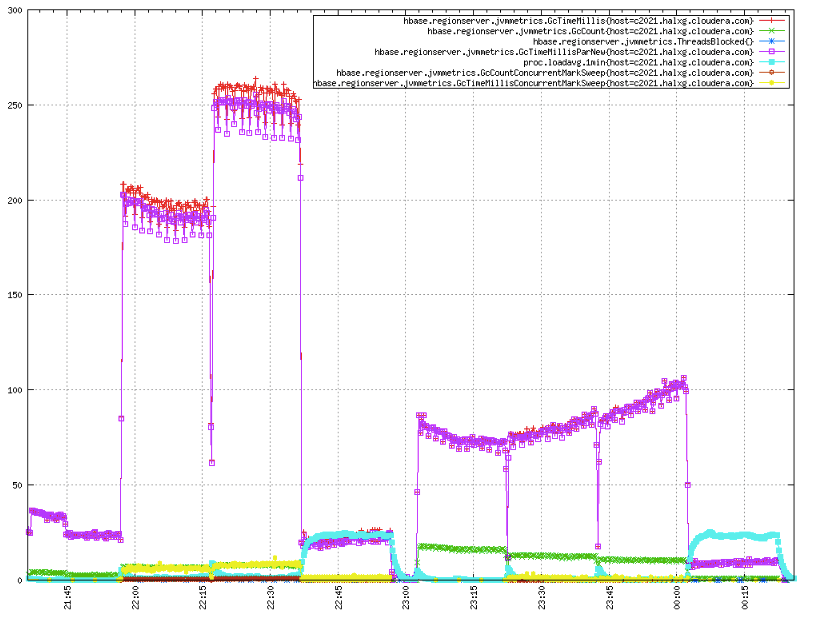
Thoughput
吞吐量可能是所有HBase用户初次使用最关心的问题,这基本反映了HBase的读写性能。下图是随机读测试的吞吐量曲线,在‘缓存全部命中’以及‘大量缓存命中’这两种场景下,LRU可谓是完胜CBC,特别是在‘缓存全部命中’的场景下,LRU的吞吐量甚至是CBC的两倍;而在‘少量缓存命中’以及‘缓存基本未命中’这两种场景下,两者的表现基本相当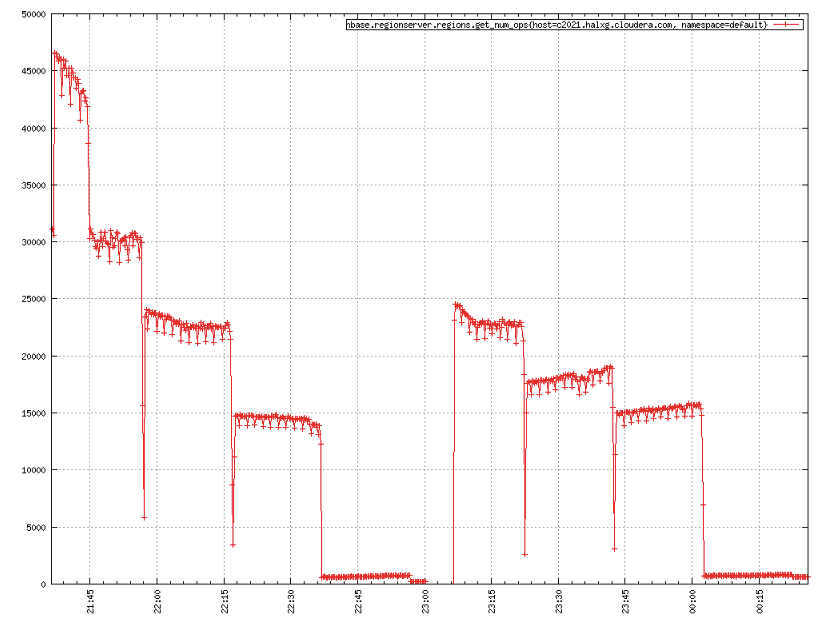
Latency
读写延迟是另一个用户很关心的指标,下图表示在所有四种情况下LRU和CBC都在伯仲之间,LRU君略胜一筹
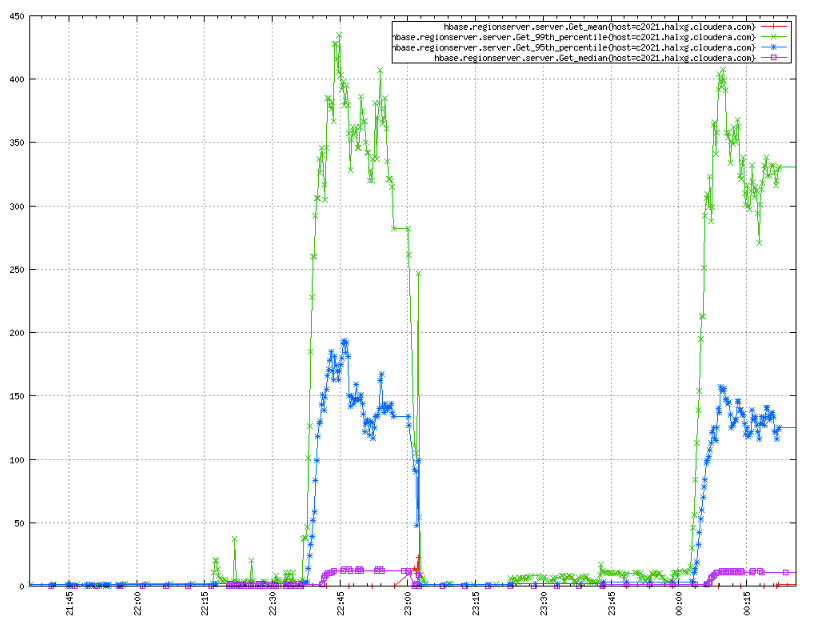
IO
接下来两张图是资源使用图,从IO使用情况来看,两者在四种场景下也基本相同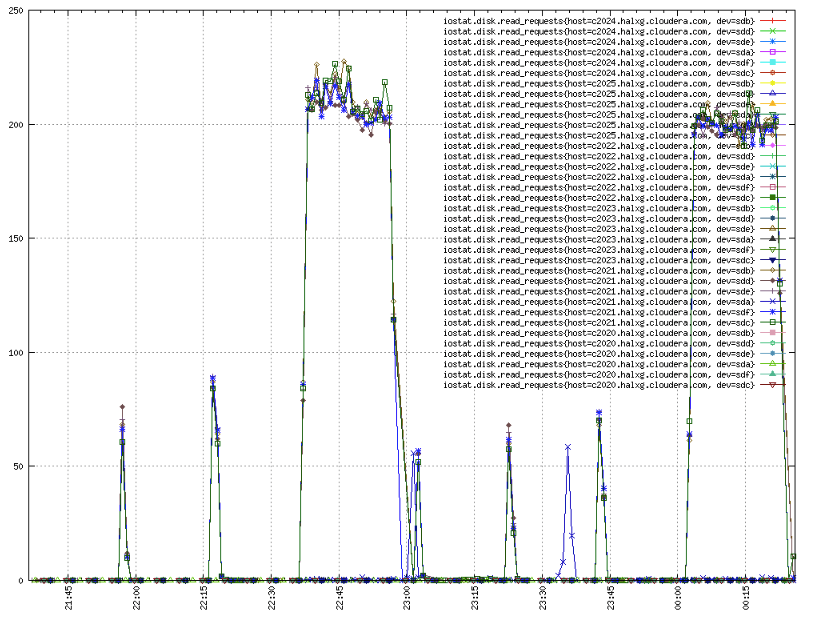
CPU
再来看看CPU使用情况,在‘缓存全部命中’以及‘大量缓存命中’这两种场景下,LRU依然完胜CBC,特别是在‘缓存全部命中’的场景下,CBC差不多做了两倍于LRU的工作;而在‘少量缓存命中’以及‘缓存基本未命中’这两种场景下,两者的表现基本相当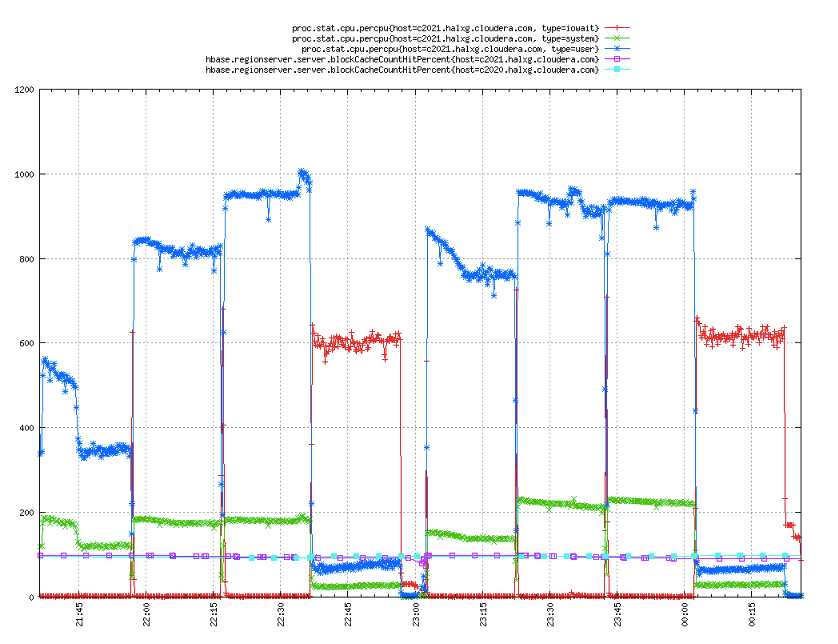
结论
看完了所有比较重要的指标对比数据,我们可以得出以下两点:
- 在’缓存全部命中’场景下,LRU可谓完胜CBC。因此如果总数据量相比JVM内存容量很小的时候,选择LRU
- 在所有其他存在缓存未命中情况的场景下, LRU的GC性能几乎只有CBC的1/3,而吞吐量、读写延迟、IO、CPU等指标两者基本相当,因此建议选择CBC
理论解释
之所以在’缓存全部命中’场景下LRU的各项指标完胜CBC,而在’缓存大量未命中’的场景下,LRU各项指标与CBC基本相当,是因为HBase在读取数据的时候,如果都缓存命中的话,对于CBC,需要将堆外内存先拷贝到JVM内,然后再返回给用户,流程比LRU君的堆内内存复杂,延迟就会更高。而如果大量缓存未命中,内存操作就会占比很小,延迟瓶颈主要在于IO,使得LRU和CBC两者各项指标基本相当

若有收获,就点个赞吧
0 人点赞
