最原始的 HBase CMS GC 相当严重,经常会因为碎片过多导致Promotion Failure,严重影响业务的读写请求。幸运的是,HBase并没有止步不前,很多优化方案相继被提出并贡献给社区,本文要介绍的就是几个比较重要的核心优化,分别是针对 Memstore 所作的两个优化:Thread-Local Allocation Buffer 和 MemStore Chunk Pool 以及针对 BlockCache 所作的优化:BucketCache方案。在详细介绍这几个优化之前有必要简单介绍一下HBase GC优化的目标,很直观的,第一是要尽量避免长时间的Full GC,避免影响用户的读写请求;第二是尽量减少GC时间,提高读写性能;接着分别来看HBase针对GC所做的各种优化
MemStore GC优化:Thread-Local Allocation Buffer
HBase数据写入操作实际上并没有直接将数据写入磁盘,而是先写入内存并顺序写入HLog,之后等待满足某个特定条件后统一将内存中的数据刷新到磁盘。一个RegionServer通常由多个Region组成,每张Region通常包含一张表的多个列族,而每个列族对应一块内存区域,这块内存被称为MemStore,很显然,一个RegionServer会由多个Region构成,一个Region会由多个MemStore构成
最原始的HBase版本存在很严重的内存碎片,经常会导致长时间的Full GC,其中最核心的问题就出在MemStore这里。因为一个RegionServer由多个Region构成,不同Region的数据写入到对应Memstore,在JVM看来其实是混合在一起写入Heap的,此时假如Region1上对应的所有MemStore执行落盘操作,就会出现下图所示场景: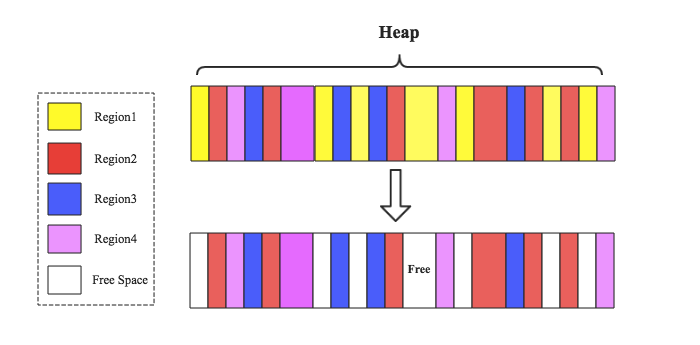
为了优化这种内存碎片可能导致的Full GC,HBase借鉴了Arena Allocation内存管理方式,它通过顺序化分配内存、内存数据分块等特性使得内存碎片更加粗粒度,有效改善Full GC情况;
具体实现原理如下:
- 每个MemStore会实例化出来一个MemStoreLAB
- MemStoreLAB会申请一个2M大小的Chunk数组和一个Chunk偏移量,初始值为0
- 当一个KeyValue值插入MemStore后,MemStoreLAB会首先通过
KeyValue.getBuffer()取得data数组,并将data数组复制到Chunk数组中,之后再将Chunk偏移量往前移动data.length - 如果当前Chunk满了之后,再调用new byte[ 2 1024 1024]申请一个新的Chunk
很显然,通过申请2M大小的Chunk可以使得内存碎片更加粗粒度,官方在优化前后通过设置 -xx:PrintFLSStatistics = 1统计了老年代的Max Chunk Size分别随时间的变化曲线,如下图所示: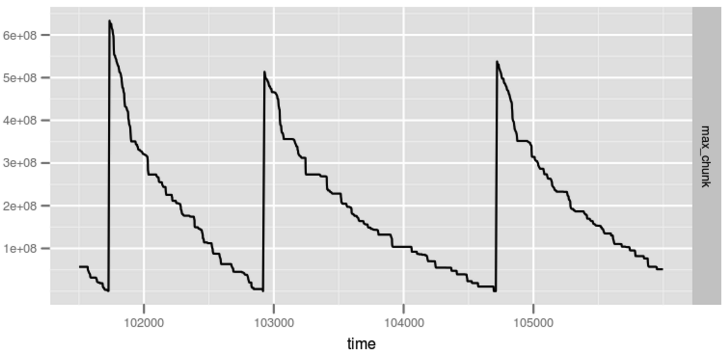
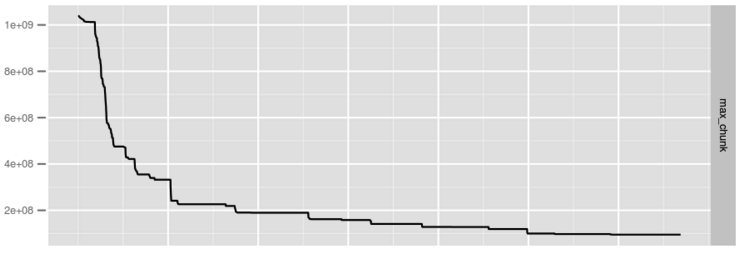
由上图可以看出,未优化前碎片会大量出现导致频繁的Full GC,优化后虽然依然会产生大量碎片,但是最大碎片大小一直会维持在1e+08左右,极大地降低了Full GC频率
MemStore GC优化:MemStore Chunk Pool
然而一旦一个Chunk写满之后,系统就会重新申请一个新的Chunk,这些Chunk大部分都会经过多次YGC之后晋升到老生代,如果某个Chunk再没有被引用就会被JVM垃圾回收。很显然,不断申请新的Chunk会导致YGC频率不断增多,YGC频率增加必然会导致晋升到老生代的Chunk增多,进而增加CMS GC发生的频率。如果这些Chunk能够被循环利用,系统就不需要申请新的Chunk,这样就会使得YGC频率降低,晋升到老生代的Chunk就会减少,CMS GC发生的频率就会降低。这就是MemStore Chunk Pool的核心思想,具体实现如下:
- 系统会创建一个Chunk Pool来管理所有未被引用的chunks,这些chunk就不会再被JVM当作垃圾回收掉了
- 如果一个Chunk没有再被引用,将其放入Chunk Pool
- 如果当前Chunk Pool已经达到了容量最大值,就不会再接纳新的Chunk
- 如果需要申请新的Chunk来存储KeyValue,首先从Chunk Pool中获取,如果能够获取得到就重复利用,如果为null就重新申请一个新的Chunk
官方针对该优化也进行了简单的测试,使用jstat -gcutil对优化前后的JVM GC情况进行了统计,具体的测试条件和测试结果如下所示:
测试条件:
HBase版本:0.94 JVM参数:-Xms4G -Xmx4G -Xmn2G 单条数据大小:Row size=50 bytes, Value size=1024 bytes 实验方法:50 concurrent theads per client, insert 10,000,000 rows
| YGC | YGCT | FGC | FGCT | GCT | |
|---|---|---|---|---|---|
| 优化前 | 747 | 36.503 | 48 | 2.492 | 38.995 |
| 优化后 | 711 | 20.344 | 4 | 0.284 | 20.628 |
很显然,经过优化后YGC时间降低了40+%左右,FGC的次数以及时间更是大幅下降
BlockCache优化:BucketCache方案
LRUBlockCache是目前HBase的默认方案,这种方案会将内存区分为3个部分:single-access区、mutil-access区以及in-memory区,一个Block块从HDFS中加载出来之后首先放入single区,后续如果有多次请求访问到这块数据的话,就会将这块数据移到mutil-access区。随着Block数据从single-access区晋升到mutil-access区,基本就伴随着对应的内存对象从young区到old区 ,晋升到old区的Block被淘汰后会变为内存垃圾,最终由CMS回收掉,CMS回收之后必然会产生大量的内存碎片,碎片空间一直累计就会产生臭名昭著的Full GC
为了减少频繁 CMS GC 产生的碎片问题,社区采纳了阿里开发者的新方案:BucketCache。这种方案还是采用“将小碎片整理为大碎片”的思路,由程序在初始化的时候就申请了很多大小为2M的Bucket,数据Block的Get/Cache动作只是对这片空间的访问/覆写,CMS碎片会自然大大降低。BucketCache有三种工作模式:heap、offheap以及file,其中heap模式表示将数据存储在JVM堆内存,offheap模式表示将数据Block存储到操作系统内存,file模式表示将数据Block存储到类似于SSD的外部高速缓存上;很显然,offheap模式和file模式根本没有将数据Block存在JVM堆内存,所以几乎不会出现Full GC,而heap模式即使数据存储在JVM堆内存,也会因为内存由程序独立管理大大降低内存碎片。
针对BlockCache的两种实现方案,分别简单地对内存碎片产生情况和GC情况进行了统计,结果如下: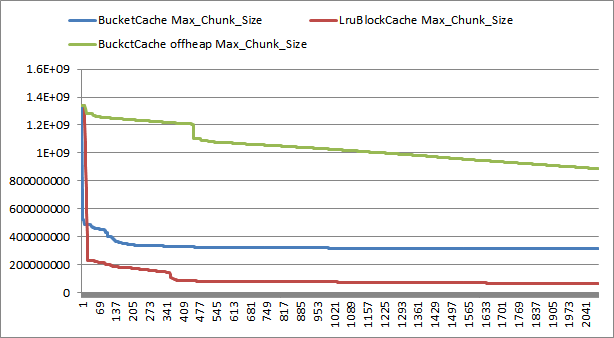
| YGC | YGCT(s) | FGC | FGCT(s) | GCT(s) | |
|---|---|---|---|---|---|
| LRUBlockCache | 79 | 26.8 | 75 | 13 | 39.8 |
| BucketCache | 171 | 11 | 1 | 0.462 | 11.462 |
从结果可以看出,BucketCache大大减少了碎片的产生,而且YGC和FGC时间也极大地得到了改善。需要注意的是,此结论是在部分缓存未命中的情况下得出的,缓存全部命中的场景结果会有所不同
YGC:从应用程序启动到采样时年轻代中gc次数 YGCT:从应用程序启动到采样时年轻代中gc所用时间(s) FGC:从应用程序启动到采样时old代(全gc)gc次数 FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s) GCT:从应用程序启动到采样时gc用的总时间(s)

若有收获,就点个赞吧
0 人点赞
