flush:将写缓存中的数据,上传到hdfs上,每次flush后,每个写缓存中的列族文件都会在hdfs上产生一个存储文件
HFile索引结构解析
HFile 中索引结构根据索引层级的不同分为两种:single-level 和 mutil-level,前者表示单层索引,后者表示多级索引,一般为两级或三级。HFile V1版本中只有single-level一种索引结构,V2版本中引入多级索引。之所以引入多级索引,是因为随着 HFile 文件越来越大,Data Block 越来越多,索引数据也越来越大,已经无法全部加载到内存中(V1版本中一个Region Server的索引数据加载到内存会占用几乎6G空间),多级索引可以只加载部分索引,降低内存使用空间。存储文件HFile结构解析,我们提到 Bloom Filter 内存使用问题是促使V1版本升级到V2版本的一个原因,再加上这个原因,这两个原因就是V1版本升级到V2版本最重要的两个因素
V2版本 Index Block 有两类:Root Index Block 和 NonRoot Index Block,其中 NonRoot Index Block 又分为Intermediate Index Block 和 Leaf Index Block 两种。HFile中索引结构类似于一棵树,Root Index Block 表示索引数根节点,Intermediate Index Block 表示中间节点,Leaf Index block 表示叶子节点,叶子节点直接指向实际数据块
HFile中除了 Data Block 需要索引之外,上一篇文章提到过 Bloom Block 也需要索引,索引结构实际上就是采用了single-level 结构,文中 Bloom Index Block 就是一种 Root Index Block
对于 Data Block,由于HFile刚开始数据量较小,索引采用 single-level 结构,只有 Root Index 一层索引,直接指向数据块。当数据量慢慢变大,Root Index Block满了之后,索引就会变为 mutil-level 结构,由一层索引变为两层,根节点指向叶子节点,叶子节点指向实际数据块。如果数据量再变大,索引层级就会变为三层
下面就针对 Root index Block 和 NonRoot index Block 两种结构进行解析,因为 Root Index Block 已经在上面一篇文章中分析过,此处简单带过,重点介绍 NonRoot Index Block 结构(InterMediate Index Block 和 Ieaf Index Block 在内存和磁盘中存储格式相同,都为NonRoot Index Block格式)
Root Index Block
Root Index Block 表示索引树根节点索引块,可以作为 bloom 的直接索引,也可以作为 data 索引的根索引。而且对于single-level 和 mutil-level 两种索引结构对应的 Root Index Block 略有不同,本文以mutil-level索引结构为例进行分析(single-level索引结构是mutual-level的一种简化场景),在内存和磁盘中的格式如下图所示: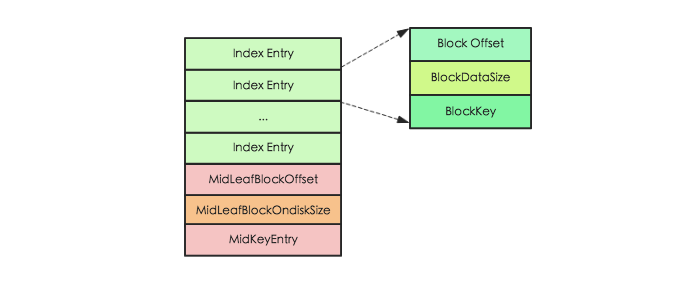
其中 Index Entry 表示具体的索引对象,每个索引对象由3个字段组成,Block Offset 表示索引指向数据块的偏移量,BlockDataSize 表示索引指向数据块在磁盘上的大小,BlockKey 表示索引指向数据块中的第一个key。除此之外,还有另外3个字段用来记录 MidKey 的相关信息,MidKey 表示 HFile 所有 Data Block 中中间的一个Data Block,用于在对HFile进行 split 操作时,快速定位 HFile 的中间位置。需要注意的是 single-level 索引结构和 mutil-level 结构相比,就只缺少MidKey这三个字段
Root Index Block 会在 HFile 解析的时候直接加载到内存中,此处需要注意在 Trailer Block 中有一个字段为dataIndexCount,就表示此处 Index Entry 的个数。因为 Index Entry 并不定长,只有知道 Entry 的个数才能正确的将所有Index Entry加载到内存
NonRoot Index Block
当HFile中 Data Block 越来越多,single-level 结构的索引已经不足以支撑所有数据都加载到内存,需要分化为 mutil-level 结构。mutil-level 结构中 NonRoot Index Block 作为中间层节点或者叶子节点存在,无论是中间节点还是叶子节点,其都拥有相同的结构,如下图所示: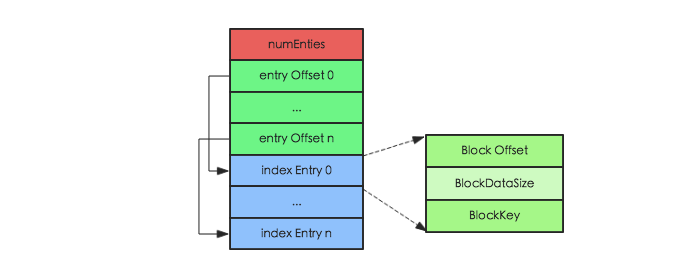
和 Root Index Block 相同,NonRoot Index Block 中最核心的字段也是 Index Entry,用于指向叶子节点块或者数据块。不同的是,NonRoot Index Block 结构中增加了 block 块的内部索引 entry Offset 字段,entry Offset 表示 index Entry在该 block 中的相对偏移量(相对于第一个index Entry),用于实现 block 内的二分查找。所有非根节点索引块,包括Intermediate index block 和 leaf index block,在其内部定位一个key的具体索引并不是通过遍历实现,而是使用二分查找算法,这样可以更加高效快速地定位到待查找key
HFile数据完整索引流程
了解了HFile中数据索引块的两种结构之后,就来看看如何使用这些索引数据块进行数据的高效检索。整个索引体系类似于MySQL的B+树结构,但是又有所不同,比B+树简单,并没有复杂的分裂操作。具体见下图所示: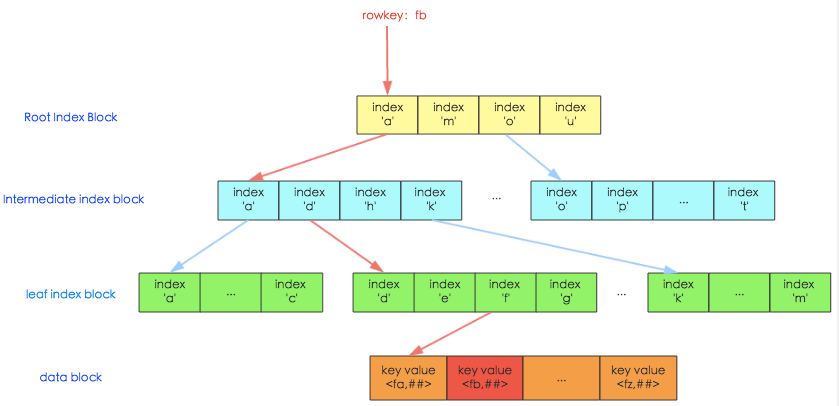
图中上面三层为索引层,在数据量不大的时候只有最上面一层,数据量大了之后开始分裂为多层,最多三层,如图所示。最下面一层为数据层,存储用户的实际key-value数据。这个索引树结构类似于InnoSQL的聚集索引,只是HBase并没有辅助索引的概念
图中红线表示一次查询的索引过程(HBase中相关类为 HFileBlockIndex 和 HFileReaderV2),基本流程可以表示为:
- 用户输入rowkey为fb,在root index block中通过二分查找定位到fb在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为 root index block 常驻内存,所以这个过程很快
- 将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index ‘d’和’h’之间,接下来访问索引’d’指向的叶子节点
- 同理,将索引’d’指向的中间节点索引块加载到内存,一样通过二分查找定位找到fb在index ‘f’和’g’之间,最后需要访问索引’f’指向的数据块节点
- 将索引’f’指向的数据块加载到内存,通过遍历的方式找到对应的keyvalue
上述流程中因为中间节点、叶子节点和数据块都需要加载到内存,所以io次数正常为3次。但是实际上HBase为block提供了缓存机制,可以将频繁使用的block缓存在内存中,可以进一步加快实际读取过程。所以,在HBase中,通常一次随机读请求最多会产生3次io,如果数据量小(只有一层索引),数据已经缓存到了内存,就不会产生io
索引块分裂
上文中已经提到,当数据量少、文件小的时候,只需要一个 root index block 就可以完成索引,即索引树只有一层。当数据不断写入,文件变大之后,索引数据也会相应变大,索引结构就会由single-level变为mulit-level,期间涉及到索引块的写入和分裂,本节来关注一下数据写入是如何引起索引块分裂的。
Memstore Flush深度解析中提到 memstore flush 主要分为3个阶段,第一个阶段会将 memstore 中的 key-value 数据snapshot,第二阶段再将这部分数据 flush 到 HFile,并生成在临时目录,第三阶段将临时文件移动到指定的ColumnFamily 目录下。很显然,第二阶段将 keyvalue 数据 flush 到 HFile 将会是关注的重点(flush相关代码在DefaultStoreFlusher 类中)。整个flush阶段又可以分为两阶段:
- append阶段:memstore 中 key-value 首先会写入到 HFile 中的数据块
finalize阶段:修改HFlie中meta元数据块,索引数据块以及Trailer数据块等
append流程
具体key-value数据的 append 以及 finalize 过程在HFileWriterV2文件中,其中append流程可以大体表征为:
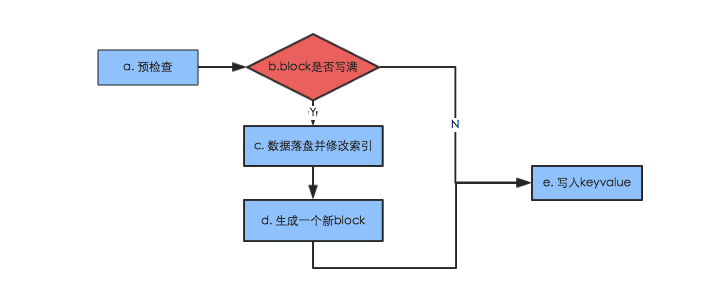
预检查:检查key的大小是否大于前一个key,如果大于则不符合HBase顺序排列的原理,抛出异常;检查value是否是null,如果为null也抛出异常
- block是否写满:检查当前Data Block是否已经写满,如果没有写满就直接写入key-value;否则就需要执行数据块落盘以及索引块修改操作
- 数据落盘并修改索引:如果DataBlock写满,首先将block块写入流;再生成一个leaf index entry,写入leaf Index block;再检查该 leaf index block 是否已经写满需要落盘,如果已经写满,就将该leaf index block写入到输出流,并且为索引树根节点 root index block 新增一个索引,指向叶子节点(second-level index)
- 生成一个新的block:重新reset输出流,初始化startOffset为-1
- 写入key-value:将key-value以流的方式写入输出流,同时需要写入memstoreTS;除此之外,如果该key是当前block的第一个key,需要赋值给变量 firstKeyInBlock
finalize阶段
memstore中所有 key-value 都经过 append 阶段输出到 HFile 后,会执行一次 finalize 过程,主要更新 HFile 中元数据块、索引数据块以及Trailer数据块,其中对索引数据块的更新是我们关心的重点,此处详细解析,上述append流程中c步骤’数据落盘并修改索引’会使得root index block不断增多,当增大到一定程度之后就需要分裂,分裂示意图如下图所示: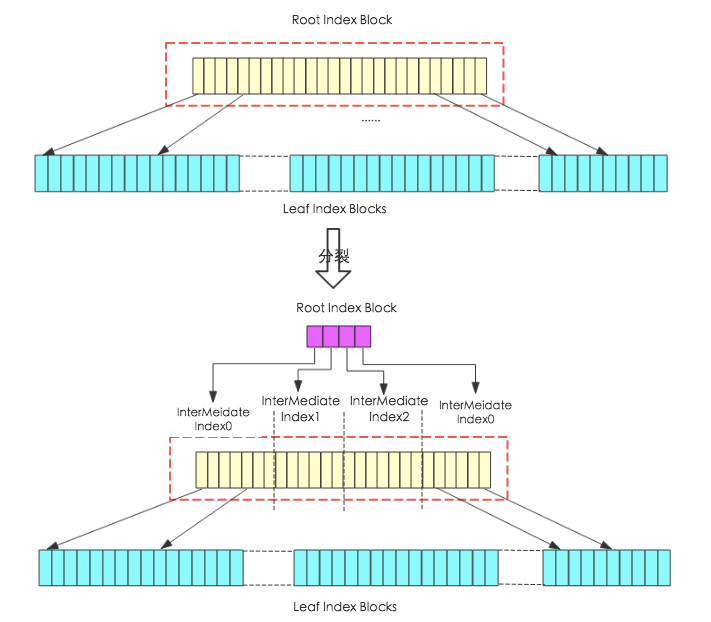
上图所示,分裂前索引结构为second-level结构,图中没有画出Data Blocks,根节点索引指向叶子节点索引块。finalize阶段系统会对 Root Index Block 进行大小检查,如果大小大于规定的大小就需要进行分裂,图中分裂过程实际上就是将原来的 Root Index Block 块分割成4块,每块独立形成中间节点 InterMediate Index Block,系统再重新生成一个Root Index Block(图中红色部分),分别指向分割形成的4个interMediate Index Block。此时索引结构就变成了third-level结构

若有收获,就点个赞吧
0 人点赞
