Apache Hadoop
- Hadoop是Apache软件基金会旗下的一款Java开源软件框架
- HDFS(分布式文件系统):解决海量数据存储
- MapReduce(分布式运算编程框架):解决海量数据计算
- Yarn(作业调度和集群资源管理框架):解决集群资源任务调度
大数据导论
- 问题
- 海量数据如何存储
- 海量数据如何计算
大数据的特点
数据体量大
- 采集数据量大
- 存储数据量大
- 计算数据量大
种类、来源多样化
- 种类:结构化(严格的schem信息,e.g. 数据库)、半结构化(e.g. json、xml)、非结构化
- 来源:日志文件、图片、音频、视频
低价值密度
- 信息海量但是价值密度低
- 深度复杂的挖掘分析需要机器学习参与
速度快
- 数据增长速度快
- 获取数据速度快
- 数据处理速度快
数据的质量
- 数据的准确性
- 数据的可信赖度
大数据应用场景
电商
- 精准广告位、个性化推荐、大数据杀熟
传媒
- 精准营销、猜你喜欢、交互推荐
金融
- 信用评估、风控、客户细分、精细化营销
交通
- 拥堵预测、智能红绿灯、导航最优规划
电信
- 基站选址优化、與情监控、客户用户画像
安防领域
- 犯罪预防、天网监控
医疗领域
- 智慧医疗、疾病预防、病源追踪
大数据业务分析基本步骤
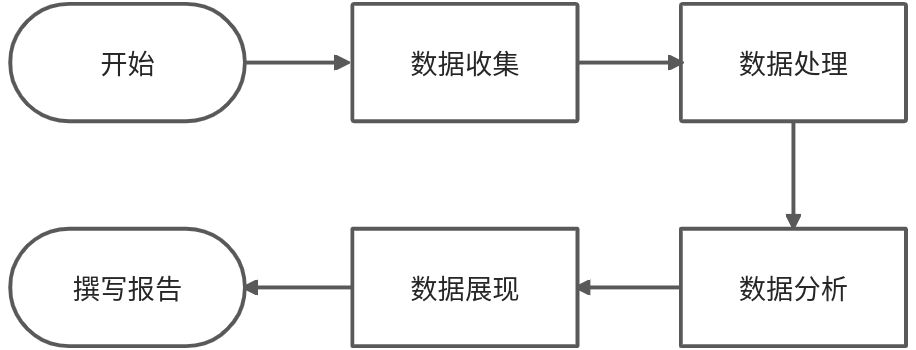
明确分析目的和思路
- 目的:为数据的收集、处理和分析提供清晰的指引方向
- 思路:使分析框架体系化
- 先分析什么,后分析什么
- 保证分析维度的完整性,分析结果的有效性以及正确性
数据收集
- 数据从无到有
- 数据传输搬运的过程:采集数据库数据到数据分析平台
- 业务数据:RDBMS
- 日志数据:服务器、应用日志
- 爬虫数据:爬虫数据库
- 互联网公开数据
数据处理
- 数据清洗、数据转化、数据提取、数据计算
数据分析
- 数据挖掘本质是一种高级的数据分析方法:分类、聚类、关联、预测
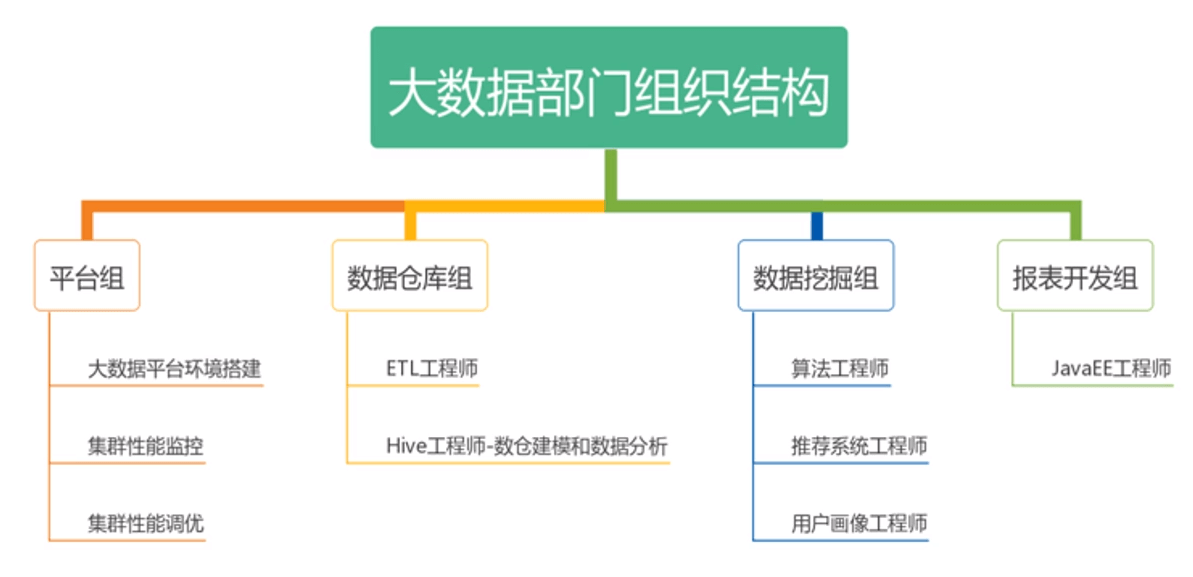
大数据部门组织架构
分布式技术
- 分布式:多台机器,每台机器上部署不同的组件
- 集群:多台机器,每台机器上部署相同的组件
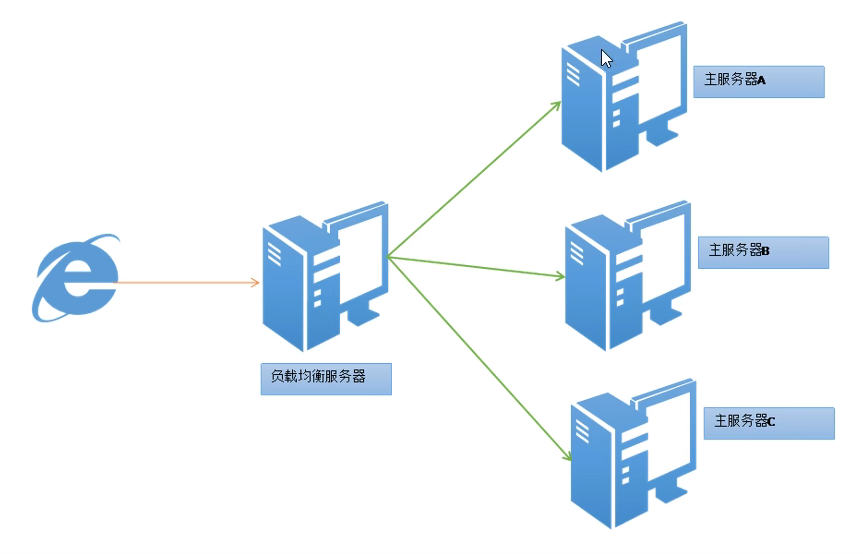
负载均衡
- 将负载进行平衡、分摊到多个操作单元上进行运行(侧重于集群)
故障转移
- 即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作

若有收获,就点个赞吧
0 人点赞
