概述
Hadoop RPC调用使得HDFS进程能够像本地调用一样调用另一个进程中的方法, 并且可以传递Java基本类型或者自定义类作为参数, 同时接收返回值
如果远程进程在调用过程中出现异常, 本地进程也会收到对应的异常
接口协议
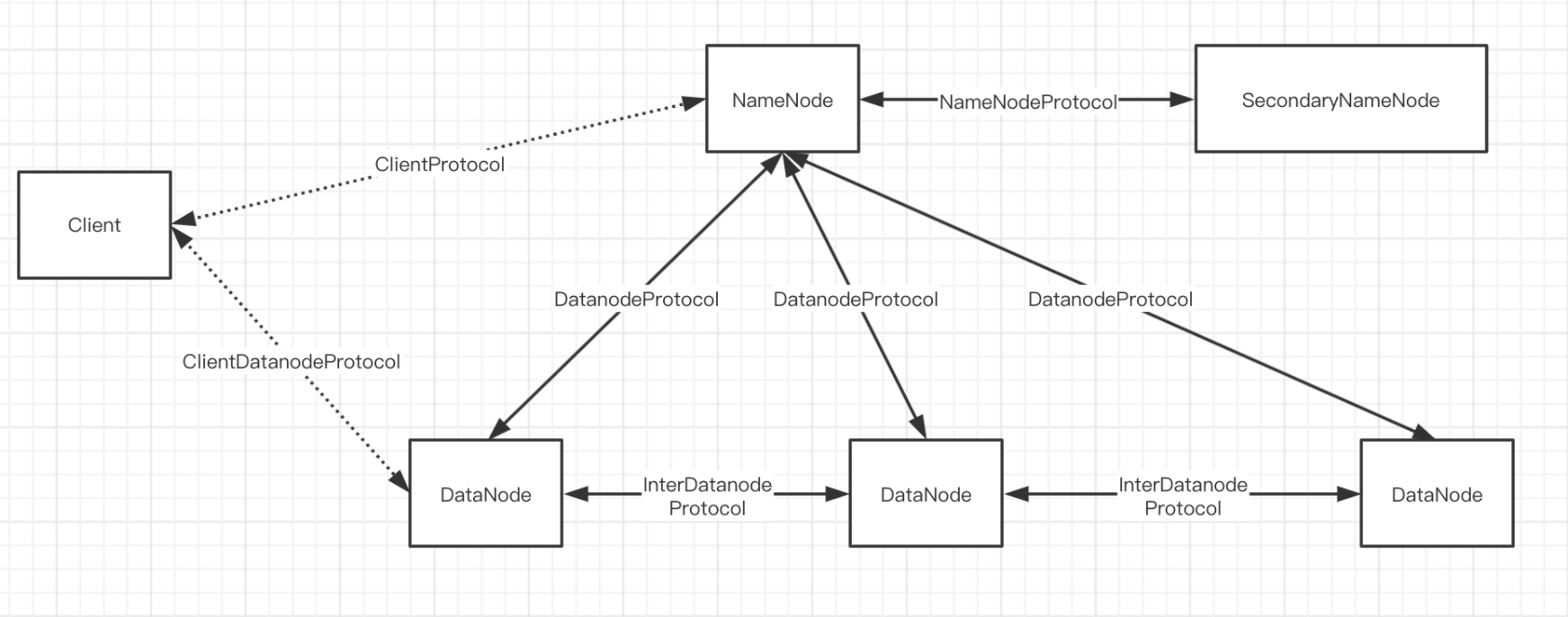
ClientProtocol
- 客户端与NameNode间通讯接口。客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与NameNode协商之后,再进行数据块的读出和写入操作
ClientDatanodeProtocol
- 客户端与数据节点间的接口。 ClientDatanodeProtocol中定义的方法主要是用于客户端获取数据节点信息时调用, 而真正的数据读写交互则是通过流式接口进行的
DataNodeProtocol
- DateNode与NameNode通信, 同时NameNode会通过这个接口中方法的返回值向数据节点下发指令
- DateNode会通过这个接口向NameNode注册、 汇报数据块的全量以及增量的存储情况。 同时, NameNode也会通过这个接口中方法的返回值, 将NameNode指令带回该数据块, 根据这些指令, 数据节点会执行数据块的复制、 删除以及恢复操作
InterDatanodeProtocol
- DateNode与DateNode间的接口, 数据节点会通过这个接口和其他数据节点通信。 这个接口主要用于数据块的恢复操作, 以及同步数据节点上存储的数据块副本的信息
NameNodeProtocol
- SecondaryNameNode与NameNode间的接口
DataTransferProtocol
- DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS客户端与数据节点以及数据节点与数据节点之间的数据块传输输就是基于DataTransferProtocol接口实现的
其他接口
- 主要包括安全相关接口(RefreshAuthorizationPolicyProtocol、RefreshUser MappingsProtocol)、HA相关接口(HAServiceProtocol)等
[
](https://blog.csdn.net/zhanglong_4444/article/details/105586527)
接口协议详情
ClientProtocol
ClientProtocol定义了所有由客户端发起的、 由Namenode响应的操作
按照接口方法分类:
- HDFS文件读相关的操作
- HDFS文件写以及追加写的相关操作
- 管理HDFS命名空间(namespace) 的相关操作
- 系统问题与管理相关的操作
- 快照相关的操作
- 缓存相关的操作
- 其他操作
读数据相关方法
ClientProtocol与客户端读取文件相关的方法主要有两个:getBlockLocations()和reportBadBlocks()
/*** 客户端会调用ClientProtocol.getBlockLocations()方法* 获取HDFS文件指定范围内所有数据块的位置信息。** 这个方法的参数是HDFS文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名* 以及它们的位置信息* 使用LocatedBlocks对象封装。** 每个数据块的位置信息指的是存储这个数据块副本的所有Datanode的信息,* 这些Datanode会以与当前客户端的距离远近排序。** 客户端读取数据时,会首先调用getBlockLocations()方法获取HDFS文件的所有数据块的位置信息,* 然后客户端会根据这些位置信息从数据节点读取数据块。*/@Idempotent@ReadOnly(atimeAffected = true, isCoordinated = true)LocatedBlocks getBlockLocations(String src, long offset, long length) throws IOException;
/**** 客户端会调用ClientProtocol.reportBadBlocks()方法向Namenode汇报错误的数据块。* 当客户端从数据节点读取数据块且发现数据块的校验和并不正确时,* 就会调用这个方法向Namenode汇报这个错误的数据块信息。** The client wants to report corrupted blocks (blocks with specified* locations on datanodes).* @param blocks Array of located blocks to report*/@Idempotentvoid reportBadBlocks(LocatedBlock[] blocks) throws IOException;
写/追加写数据相关方法
支持HDFS文件的写操作:create()、append()、addBlock()、complete()、 abandonBlock()、updateBlockForPipeline()和updatePipeline() 等
/*** create()方法用于在HDFS的文件系统目录树中创建一个新的空文件,创建的路径由src参数指定。* 这个空文件创建后对于其他的客户端是“可读”的,但是这些客户端不能删除、* 重命名或者移动这个文件,直到这个文件被关闭或者租约过期。** 客户端写一个新的文件时,会首先调用create()方法在文件系统目录树中创建一个空文件,* 然后调用addBlock()方法获取存储文件数据的数据块的位置信息,* 最后客户端就可以根据位置信息建立数据流管道,向数据节点写入数据。**/@AtMostOnceHdfsFileStatus create(String src, FsPermission masked,String clientName, EnumSetWritable<CreateFlag> flag,boolean createParent, short replication, long blockSize,CryptoProtocolVersion[] supportedVersions, String ecPolicyName)throws IOException;/*** append()方法用于打开一个已有的文件,* 如果这个文件的最后一个数据块没有写满, 则返回这个数据块的位置信息(使用LocatedBlock对象* 封装);** 如果这个文件的最后一个数据块正好写满,则创建一个新的数据块并添加到这个文件中,* 然后返回这个新添加的数据块的位置信息。** 客户端追加写一个已有文件时,会先调用append()方法获取最后一个可写数据块的位置信息,* 然后建立数据流管道,并向数据节点写入追加的数据。* 如果客户端将这个数据块写满,与create()方法一样,客户端会调用addBlock()方法获取新的数据块**/@AtMostOnceLastBlockWithStatus append(String src, String clientName,EnumSetWritable<CreateFlag> flag) throws IOException;/*** 客户端调用addBlock()方法向指定文件添加一个新的数据块,* 并获取存储这个数据块副本的所有数据节点的位置信息(使用LocatedBlock对象封装)。** 要特别注意的是,调用addBlock()方法时还要传入上一个数据块的引用。* Namenode在分配新的数据块时,会顺便提交上一个数据块,这里previous参数就是上一个数据块的* 引用。** excludeNodes参数则是数据节点的黑名单,保存了客户端无法连接的一些数据节点,* 建议Namenode在分配保存数据块副本的数据节点时不要考虑这些节点。** favoredNodes参数则是客户端所希望的保存数据块副本的数据节点的列表。* 客户端调用addBlock()方法获取新的数据块的位置信息后,会建立到这些数据节点的数据流管道,* 并通过数据流管道将数据写入数据节点。**/@IdempotentLocatedBlock addBlock(String src, String clientName,ExtendedBlock previous, DatanodeInfo[] excludeNodes, long fileId,String[] favoredNodes, EnumSet<AddBlockFlag> addBlockFlags)throws IOException;/*** 当客户端完成了整个文件的写入操作后,会调用complete()方法通知Namenode。** 这个操作会提交新写入HDFS文件的所有数据块,* 当这些数据块的副本数量满足系统配置的最小副本系数(默认值为1),* 也就是该文件的所有数据块至少有一个有效副本时,* complete()方法会返回true,* 这时Namenode中文件的状态也会从构建中状态转换为正常状态;* 否则,complete()会返回false,客户端就需要重复调用complete()操作,直至该方法返回true。**/@Idempotentboolean complete(String src, String clientName,ExtendedBlock last, long fileId)throws IOException;/*** abandonBlock()方法用于处理客户端建立数据流管道时数据节点出现故障的情况。** 客户端调用abandonBlock()方法放弃一个新申请的数据块。*** 问题1: 创建数据块失败** 当客户端获取了一个新申请的数据块,发现无法建立到存储这个数据块副本的某些数据节点的连接时,* 会调用abandonBlock()方法通知名字节点放弃这个数据块,* 之后客户端会再次调用addBlock()方法获取新的数据块,* 并在传入参数时将无法连接的数据节点放入 excludeNodes参数列表中,* 以避免Namenode将数据块的副本分配到该节点上,* 造成客户端 再次无法连接这个节点的情况。*** 问题2: 如果客户端已经成功建立了数据流管道,在客户端写某个数据块时,* 存储这个数据块副本的某个数据节点出现了错误该如何处理** 客户端首先会调用getAdditionalDatanode()方法向Namenode申请一个新的Datanode来替代出现故* 障的Datanode,* 然后客户端会调用updateBlockForPipeline()方法向Namenode申请为这个数据块分配新的时间戳,* 这样故障节点上的没能写完整的数据块的时间戳就会过期,在后续的块汇报操作中会被删除。* 最后客户端就可以使用新的时间戳建立新的数据流管道,来执行对数据块的写操作了。* 数据流管道建立成功后,客户端还需要调用updatePipeline()方法更新* Namenode中当前数据块的数据流管道信息。至此,一个完整的恢复操作结束。*** 问题3: 在写数据的过程中,Client节点也有可能在任意时刻发生故障** 对于任意一个Client打开的文件都需要Client定期调用ClientProtocol.renewLease()* 方法更新租约* 如果Namenode长时间没有收到Client的租约更新消息,* 就会认为Client发生故障,这时就会触发一次租约恢复操作,* 关闭文件并且同步所有数据节点上这个文件数据块的状态,确保HDFS系统中这个文件是正确且一致保存的。**/@Idempotentvoid abandonBlock(ExtendedBlock b, long fileId,String src, String holder)throws IOException;
命名空间管理&系统问题与管理操作
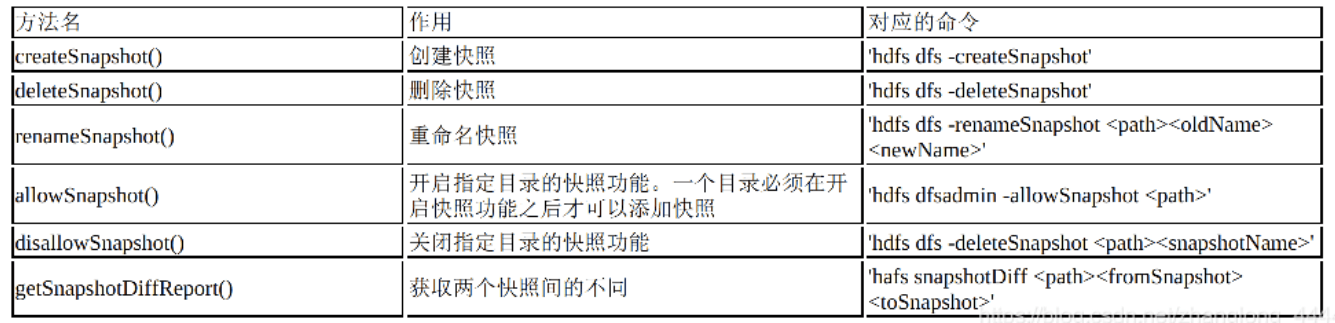
快照相关操作
快照保存了一个时间点上HDFS某个路径中所有数据的拷贝,快照可以将失效的集群回滚到之前一个正常的时间点上。用户可以通过hdfs dfs命令执行创建、删除以及重命名快照等操作,ClientProtocol也定义了对应的方法来支持快照命令
在创建快照之前,必须先通过hdfs dfsadmin-allowSnapshot命令开启目录的快照功能,否则不可以在该目录上创建快照
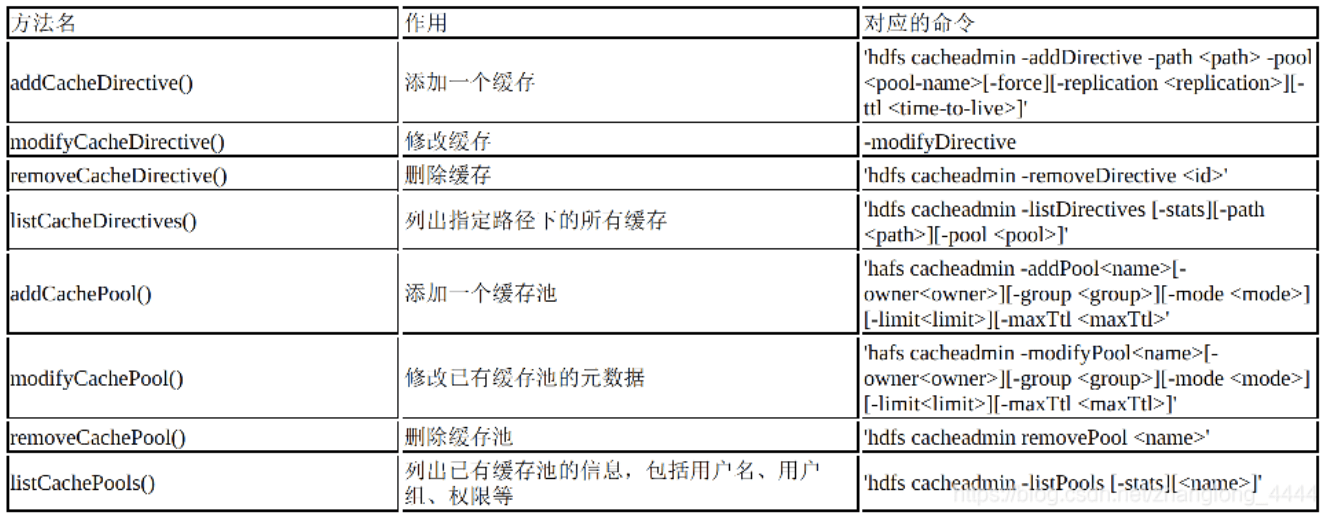
缓存相关
用户可以指定一些经常被使用的数据或者高优先级任务对应的数据, 让它们常驻内存而不被淘汰到磁盘上.
- cache directive:表示要被缓存到内存的文件或者目录
- cache pool:用于管理一系列的cache directive,类似于命名空间。同时使用Unix风格的文件读、写、执行权限管理机制
ClientDataNodeProtocol
ClientDatanodeProtocol定义了Client与Datanode之间的接口
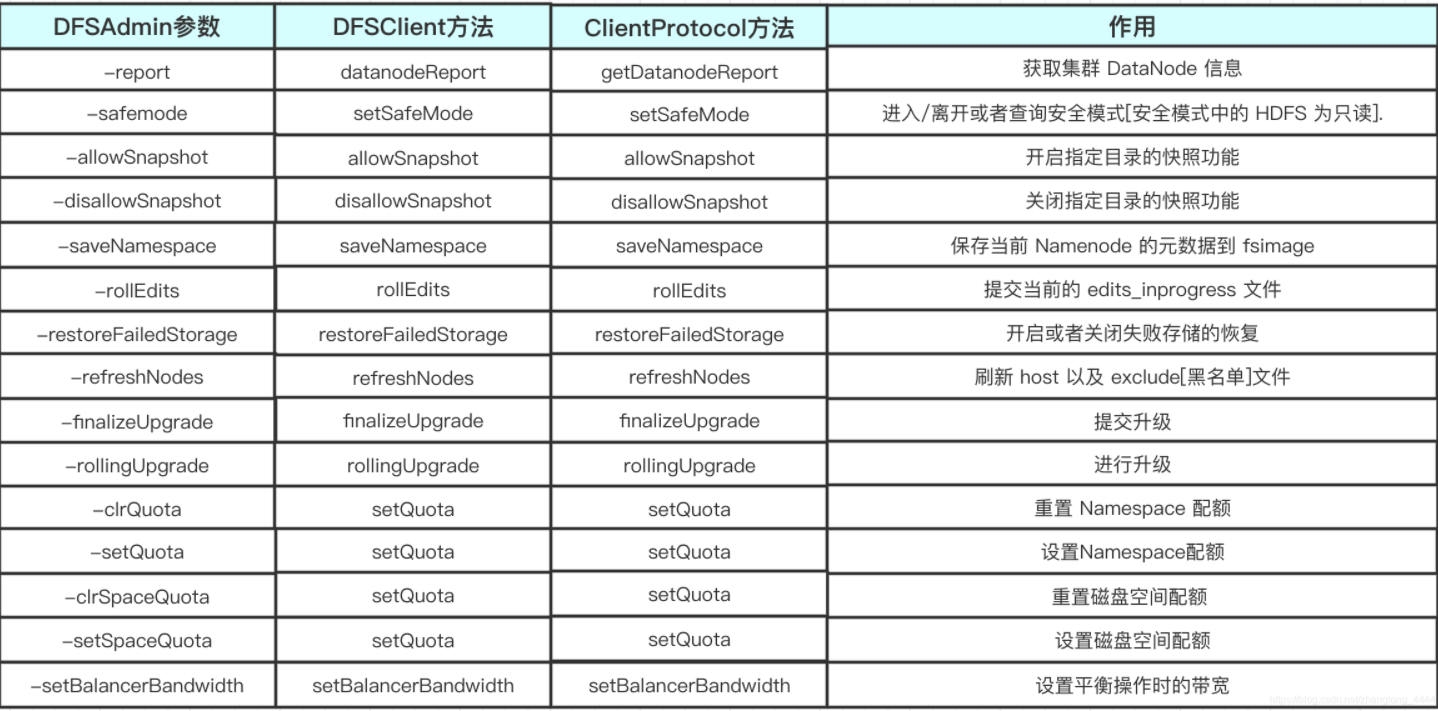
ClientDatanodeProtocol中定义的接口可以分为两部分:
- 支持HDFS文件读取操作的, 例如
getReplicaVisibleLength()以及getBlockLocalPathInfo() - 支持DFSAdmin中与数据节点管理相关的命令
```java
/**
- 在用户管理员命令中有一个’hdfs dfsadmindatanodehost:port’命令,
- 用于触发指定的Datanode重新加载配置文件,
- 停止服务那些已经从配置文件中删除的块池(blockPool),开始服务新添加的块池。 */ void refreshNamenodes() throws IOException;
/**
- 用于从指定Datanode删除blockpoolId对应的块池,如果force参数被设置了,
- 那么无论这个块池目录中有没有数据都会被强制删除;
- 否则,只有这个块池目录为空的情况下才会被删除。 *
- 如果Datanode还在服务这个块池,这个命令的执行将会失败。
- 要停止一个数据节点服务指定的块池,需要调用上面提到的refreshNamenodes()方法。 *
- deleteBlockPool()方法有两个参数,其中blockpoolId用于设置要被删除的块池ID;
- force用于设置是否强制删除。 / void deleteBlockPool(String bpid, boolean force) throws IOException;
/**
- HDFS对于本地读取,即Client和保存该数据块的Datanode在同一台物理机器上时,是有很多优化 *
- Client会调用ClientProtocol.getBlockLocaIPathInfo()方法
- 获取指定数据块文件以及数据块校验文件在当前节点上的本地路径,
- 然后利用这个本地路径执行本地读取操作,而不是通过流式接口执行远程读取,这样也就大大优化了
- 读取的性能。 *
- 客户端会通过调用DataTransferProtocol接口从数据节点获取数据块文件的文件描述符,
- 然后打开并读取文件以实现短路读操作,而不是通过ClientDatanodeProtoco接口。
/
BlockLocalPathInfo getBlockLocalPathInfo(ExtendedBlock block,
Token
token) throws IOException;
/**
- shutdownDatanode()方法用于关闭一个数据节点 */ void shutdownDatanode(boolean forUpgrade) throws IOException;
/**
- Evict clients that are writing to a datanode. *
- @throws IOException */ void evictWriters() throws IOException;
/**
- getDatanodeInfo()方法用于获取指定Datanode的信息,
- 这里的信息包括Datanode运行的HDFS版本、Datanode配置的HDFS版本,
- 以及Datanode的启动时间。对应于管理命令’hdfs dfsadmin-getDatanodeInfo’。 *
- @return software/config version and uptime of the datanode */ DatanodeLocalInfo getDatanodeInfo() throws IOException;
/**
- startReconfiguration()方法用于触发Datanode异步地从磁盘重新加载配置,并且应用该配置。
- 这个方法用于支持管理命令’hdfs dfsadmin-getDatanodeInfo-reconfigstart’。 / void startReconfiguration() throws IOException;
/**
- 查询上一次触发的重新加载配置操作的运行情况 */ ReconfigurationTaskStatus getReconfigurationStatus() throws IOException;
/**
- Get a list of allowed properties for reconfiguration.
*/
List
listReconfigurableProperties() throws IOException;
/**
- Trigger a new block report. */ void triggerBlockReport(BlockReportOptions options) throws IOException;
/**
- 获取平衡器带宽的当前值,以每秒字节数为单位 *
- @return balancer bandwidth */ long getBalancerBandwidth() throws IOException;
/**
- 用于获取数据块是存储在指定Datanode的哪个卷 (volume)上的
- Get volume report of datanode.
*/
List
getVolumeReport() throws IOException;
/**
- Submit a disk balancer plan for execution.
/
void submitDiskBalancerPlan(String planID, long planVersion, String planFile,
throws IOException;String planData, boolean skipDateCheck)
/**
- Cancel an executing plan. / void cancelDiskBalancePlan(String planID) throws IOException;
/**
Gets the status of an executing diskbalancer Plan. / DiskBalancerWorkStatus queryDiskBalancerPlan() throws IOException;
/**
- Gets a run-time configuration value from running diskbalancer instance.
- For example : Disk Balancer bandwidth of a running instance. *
- @param key runtime configuration key
- @return value of the key as a string.
- @throws IOException - Throws if there is no such key */ String getDiskBalancerSetting(String key) throws IOException; } ```
DataNodeProtocol
DatanodeProtocol是Datanode与Namenode间的接口,Datanode会使用这个接口与Namenode握手、注册、发送心跳、进行全量以及增量的数据块汇报。Namenode会在Datanode的心跳响应中携带名字节点指令, Datanode收到名字节点指令之后会执行对应的操作
租约是Namenode给予租约持有者(LeaseHolder, 一般是客户端)在规定时间内拥有文件权限(写文件)的合同
final static int DNA_UNKNOWN = 0; // unknown action/*** 数据块复制* DNA_TRANSFER指令用于触发数据节点的数据块复制操作,* 当HDFS系统中某个数据块的副本数小于配置的副本系数时,* Namenode会通过DNA_TRANSFER指令通知某个拥有这个数据块副本的Datanode将该数据块复制到其他数* 据节点上。**/final static int DNA_TRANSFER = 1; // transfer blocks to another datanode/*** 数据库删除* DNA_INVALIDATE用于通知Datanode删除数据节点上的指定数据块,* 这是因为Namenode发现了某个数据块的副本数已经超过了配置的副本系数,* 这时Namenode会通知某个数据节点删除这个数据节点上多余的数据块副本。**/final static int DNA_INVALIDATE = 2; // invalidate blocks/*** 关闭数据节点* DNA_SHUTDOWN已经废弃不用了,* Datanode接收到DNASHUTDOWN指令后会直接抛出UnsupportedOperationException异常。* 关闭Datanode是通过调用ClientDatanodeProtocol.shutdownDatanode()方法来触发的。**/final static int DNA_SHUTDOWN = 3; // shutdown node//重新注册数据节点final static int DNA_REGISTER = 4; // re-register//提交上一次升级final static int DNA_FINALIZE = 5; // finalize previous upgrade// 数据块恢复// 当客户端在写文件时发生异常退出,会造成数据流管道中不同数据节点上数据块状态的不一致,// 这时Namenode会从数据流管道中选出一个数据节点作为主恢复节点,// 协调数据流管道中的其他数据节点进行租约恢复操作,以同步这个数据块的状态。final static int DNA_RECOVERBLOCK = 6; // request a block recovery//安全相关final static int DNA_ACCESSKEYUPDATE = 7; // update access key// 更新平衡器宽度final static int DNA_BALANCERBANDWIDTHUPDATE = 8; // update balancer bandwidth//缓存数据换final static int DNA_CACHE = 9; // cache blocks//取消缓存数据块final static int DNA_UNCACHE = 10; // uncache blocks//擦除编码重建命令final static int DNA_ERASURE_CODING_RECONSTRUCTION = 11; // erasure coding reconstruction command// 块存储移动命令int DNA_BLOCK_STORAGE_MOVEMENT = 12; // block storage movement command//删除sps工作命令int DNA_DROP_SPS_WORK_COMMAND = 13; // drop sps work command/*** Register Datanode.** 一个完整的Datanode启动操作会与Namenode进行4次交互,即调用4次DatanodeProtocol定义的方法** 首先调用versionRequest()与Namenode进行握手操作,* 然后调用registerDatanode()向Namenode注册当前的Datanode,* 接着调用blockReport()汇报Datanode上存储的所有数据块,* 最后调用cacheReport()汇报Datanode缓存的所有数据块。** 成功进行握手操作后,* Datanode会调用ClientProtocol.registerDatanode()方法向Namenode注册当前的Datanode,* 这个方法的参数是一个DatanodeRegistration对象,* 它封装了DatanodeID、Datanode的存储系统的布局版本号(layoutversion)、* 当前命名空间的ID(namespaceId)、集群ID(clusterId)、* 文件系统的创建时间(ctime)以及Datanode当前的软件版本号(softwareVersion)。** namenode节点会判断Datanode的软件版本号与Namenode 的软件版本号是否兼容,* 如果兼容则进行注册操作,并返回一个DatanodeRegistration对象供Datanode后续处理逻辑使用。**/@Idempotentpublic DatanodeRegistration registerDatanode(DatanodeRegistration registration) throws IOException;/*** Datanode会定期向Namenode发送心跳,dfs.heartbeat.interval配置项配置,默认是3秒** 用于心跳汇报的接口,除了携带标识Datanode身份的DatanodeRegistration对象外,* 还包括数据节点上所有存储的状态、缓存的状态、正在写文件数据的连接数、读写数据使用的线程数等** sendHeartbeat()会返回一个HeartbeatResponse对象,* 这个对象包含了Namenode向Datanode发送的名字节点指令,以及当前Namenode的HA状态。** 需要特别注意的是,在开启了HA的HDFS集群中,* Datanode是需要同时向Active Namenode以及Standby Namenode发送心跳的,* 不过只有ActiveNamenode才能向Datanode下发名字节点指令。**/@Idempotentpublic HeartbeatResponse sendHeartbeat(DatanodeRegistration registration,StorageReport[] reports,long dnCacheCapacity,long dnCacheUsed,int xmitsInProgress,int xceiverCount,int failedVolumes,VolumeFailureSummary volumeFailureSummary,boolean requestFullBlockReportLease,@Nonnull SlowPeerReports slowPeers,@Nonnull SlowDiskReports slowDisks)throws IOException;/*** Datanode成功向Namenode注册之后,* Datanode会通过调用DatanodeProtocol.blockReport()方法向Namenode上报它管理的所有数据块的信息。* 这个方法需要三个参数:* DatanodeRegistration:用于标识当前的Datanode;* poolId:用于标识数据块所在的块池ID;* reports:是一个StorageBlockReport对象的数组,每个StorageBlockReport对象都用于记录* Datanode上一个存储空间存储的数据块。** 这里需要特别注意的是,上报的数据块是以长整型数组保存的,* 每个已经提交的数据块(finalized)以3个长整型来表示,* 每个构建中的数据块(under-construction)以4个长整型来表示。* 之所以不使用ExtendedBlock对象保存上报的数据块,* 是因为这样可以减少blockReport()操作所使用的内存,** Namenode接收到消息时,不需要创建大量的ExtendedBlock对象,* 只需要不断地从长整型数组中提取数据块即可。**/@Idempotentpublic DatanodeCommand blockReport(DatanodeRegistration registration,String poolId, StorageBlockReport[] reports,BlockReportContext context) throws IOException;/*** Namenode接收到blockReport()请求之后,* 会根据Datanode上报的数据块存储情况建立数据块与数据节点之间的对应关系。* 同时,Namenode会在blockReport()的响应中携带名字节点指令,* 通知数据节点进行重新注册、发送心跳、备份或者删除Datanode本地磁盘上数据块副本的操作。* 这些名字节点指令都是以DatanodeCommand对象封装的** blockReport()方法只在Datanode启动时以及指定间隔时执行一次。* 间隔是由 dfs.blockreport.intervalMsec参数配置的,默认是6小时执行一次。*/@Idempotentpublic DatanodeCommand cacheReport(DatanodeRegistration registration,String poolId, List<Long> blockIds) throws IOException;/*** Datanode会定期(默认是5分钟,不可以配置)调用blockReceivedAndDeleted()方法* 向Namenode汇报Datanode新接受的数据块或者删除的数据块。** Datanode接受一个数据块,可能是因为Client写入了新的数据块,* 或者从别的Datanode上复制一个数据块到当前Datanode。** Datanode删除一个数据块,则有可能是因为该数据块的副本数量过多,* Namenode向当前Datanode下发了删除数据块副本的指令。** 我们可以把blockReceivedAndDeleted()方法理解为blockReport()的增量汇报,* 这个方法的参数包括DatanodeRegistration对象、增量汇报数据块所在的块池ID,* 以及StorageReceivedDeletedBlocks对象的数组,** 这里的StorageReceived DeletedBlocks对象封装了Datanode的一个数据存储上新添加以及删除的* 数据块集合。** Namenode接受了这个请求之后,会更新它内存中数据块与数据节点的对应关系。**/@Idempotentpublic void blockReceivedAndDeleted(DatanodeRegistration registration,String poolId,StorageReceivedDeletedBlocks[] rcvdAndDeletedBlocks)throws IOException;/*** 该方法用于向名字节点上报运行过程中 发生的一些状况,如磁盘不可用等*/@Idempotentpublic void errorReport(DatanodeRegistration registration,int errorCode,String msg) throws IOException;/*** 此方法的返回值是一个NamespaceInfo对象,NamespaceInfo对象会封装当前HDFS集群的命名空间信息,** 包括存储系统的布局版本号(layoutversion)、* 当前的命名空间的ID(namespaceId)、集群ID(clusterId)、* 文件系统的创建时间 (ctime)、构建时的HDFS版本号(buildVersion)、* 块池ID(blockpoolId)、当前的软件版本号(softwareVersion)等。** Datanode获取到NamespaceInfo对象后,* 就会比较Datanode当前的HDFS版本号和Namenode的HDFS版本号,* 如果Datanode版本与Namenode版本不能协同工作,则抛出异常,* Datanode也就无法注册到该Namenode上。* 如果当前Datanode上已经有了文件存储的目录,* 那么Datanode还会检查Datanode存储上的块池ID、文件系统ID以及集群ID与Namenode返回的是否一致。*/@Idempotentpublic NamespaceInfo versionRequest() throws IOException;/*** reportBadBlocks()与ClientProtocol.reportBad.Blocks()方法很类似,* Datanode会调用这个方法向Namenode汇报损坏的数据块。** Datanode会在三种情况下调用这个方法:** 1.DataBlockScanner线程定期扫描数据节点上存储的数据块,发现数据块的校验出现错误时;** 2.数据流管道写数据时,Datanode接受了一个新的数据块,进行数据块校验操作出现错误时;** 3.进行数据块复制操作(DataTransfer),Datanode读取本地存储的数据块时,发现本地数据块副本* 的长度小于Namenode记录的长度,则认为该数据块已经无效,会调用reportBadBlocks()方法。** reportBadBlocks()方法的参数是LocatedBlock对象,这个对象描述了出现错误数据块的位置,** Namenode收到reportBadBlocks()请求后,会下发数据块副本删除指令删除错误的数据块。**/@Idempotentpublic void reportBadBlocks(LocatedBlock[] blocks) throws IOException;/*** Commit block synchronization in lease recovery** 用于在租约恢复操作时同步数据块的状态。* 在租约恢复操作时,主数据节点完成所有租约恢复协调操作后调用commitBlockSynchronization()方法* 同步Datanode和Namenode上数据块的状态,* 所以commitBlockSynchronization()方法包含了大量的参数。**/@Idempotentpublic void commitBlockSynchronization(ExtendedBlock block,long newgenerationstamp, long newlength,boolean closeFile, boolean deleteblock, DatanodeID[] newtargets,String[] newtargetstorages) throws IOException;}
InterDataNodeProtocol
Datanode与Datanode之间的接口,主要用于租约恢复操作
/*** 客户端打开一个文件进行写操作时,首先要获取这个文件的租约,并且还需要定期更新租约* 当Namenode的租约监控线程发现某个HDFS文件租约长期没有更新时,* 就会认为写这个文件的客户端发生异常,* 这时Namenode就需要触发租约恢复操作,同步数据流管道中所有Datanode上该文件数据块的状态,* 并强制关闭这个文件。*** 租约恢复的控制并不是由Namenode负责的,而是Namenode从数据流管道中选出一个主恢复节点,* 然后通过下发DatanodeCommand的恢复指令触发这个数据节点控制租约恢复操作,* 也就是由这个主恢复节点协调整个租约恢复操作的过程。** 主恢复节点会调用InterDatanodeProtocol接口来指挥数据流管道的其他数据节点进行租约恢复。*** 租约恢复操作其实很简单,* 就是将数据流管道中所有数据节点上保存的同一个数据块状态(时间戳和数据块长度)同步一致。* 当成功完成租约恢复后,* 主恢复节点会调用DatanodeProtocol.commitBlockSynchronization()方法* 同步namenode节点上该数据块的时间戳和数据块长度,保持名字节点和数据节点的一致。** 由于数据流管道中同一个数据块状态(长度和时间戳)在不同的Datanode上可能是不一致的,* 所以主恢复节点会首先调用InterDatanodeProtocol.initReplicaRecovery()方法* 获取数据流管道中所有数据节点上保存的指定数据块的状态,* 这里的数据块状态使用ReplicaRecoveryInfo类封装。* 主恢复节点会根据收集到的这些状态,确定一个当前数据块的新长度,* 并且使用Namenode下发的recoverId作为数据块的新时间戳。** 当完成了所有的同步操作后,* 主恢复节点节就可以调用DatanodeProtocol.commitBlockSynchronization()* 将Namenode上该数据块的长度和时间戳同步为新的长度和时间戳,* 这样Datanode和Namenode的数据也就一致了。**/@KerberosInfo(serverPrincipal = DFSConfigKeys.DFS_DATANODE_KERBEROS_PRINCIPAL_KEY,clientPrincipal = DFSConfigKeys.DFS_DATANODE_KERBEROS_PRINCIPAL_KEY)@InterfaceAudience.Privatepublic interface InterDatanodeProtocol {Logger LOG = LoggerFactory.getLogger(InterDatanodeProtocol.class.getName());public static final long versionID = 6L;/*** 由于数据流管道中同一个数据块状态(长度和时间戳)在不同的Datanode上可能是不一致的,* 所以主恢复节点会首先调用InterDatanodeProtocol.initReplicaRecovery()方法* 获取数据流管道中所有数据节点上保存的指定数据块的状态,* 这里的数据块状态使用ReplicaRecoveryInfo类封装。* 主恢复节点会根据收集到的这些状态,确定一个当前数据块 的新长度,* 并且使用Namenode下发的recoverId作为数据块的新时间戳。** Initialize a replica recovery.** @return actual state of the replica on this data-node or* null if data-node does not have the replica.*/ReplicaRecoveryInfo initReplicaRecovery(RecoveringBlock rBlock)throws IOException;/*** 将数据流管道中所有节点上该数据块的长度同步为新的长度,将数据块的时间戳同步为新的时间戳。** Update replica with the new generation stamp and length.*/String updateReplicaUnderRecovery(ExtendedBlock oldBlock, long recoveryId,long newBlockId, long newLength)throws IOException;}
DataTransferProtocol
DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS客户端与数据节点以及数据节点与数据节点之间的数据块传输输就是基于DataTransferProtocol接口实现的
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.hdfs.protocol.datatransfer;import java.io.IOException;import org.apache.hadoop.classification.InterfaceAudience;import org.apache.hadoop.classification.InterfaceStability;import org.apache.hadoop.fs.StorageType;import org.apache.hadoop.hdfs.protocol.BlockChecksumOptions;import org.apache.hadoop.hdfs.protocol.DatanodeInfo;import org.apache.hadoop.hdfs.protocol.ExtendedBlock;import org.apache.hadoop.hdfs.protocol.StripedBlockInfo;import org.apache.hadoop.hdfs.security.token.block.BlockTokenIdentifier;import org.apache.hadoop.hdfs.server.datanode.CachingStrategy;import org.apache.hadoop.hdfs.shortcircuit.ShortCircuitShm.SlotId;import org.apache.hadoop.security.token.Token;import org.apache.hadoop.util.DataChecksum;import org.slf4j.Logger;import org.slf4j.LoggerFactory;/*** DataTransferProtocol接口调用并没有使用Hadoop RPC框架提供的功能,* 而是定义了用于发送DataTransferProtocol请求的Sender类,* 以及用于响应DataTransferProtocol请求的Receiver类,** Sender类和Receiver类都实现了DataTransferProtocol接口。* 我们假设DFSClient发起了一个DataTransferProtocol.readBlock()操作,* 那么DFSClient会调用Sender将这个请求序列化,并传输给远端的Receiver。* 远端的Receiver接收到这个请求后,会反序列化请求,然后调用代码执行读取操作。**/@InterfaceAudience.Private@InterfaceStability.Evolvingpublic interface DataTransferProtocol {Logger LOG = LoggerFactory.getLogger(DataTransferProtocol.class);/** Version for data transfers between clients and datanodes* This should change when serialization of DatanodeInfo, not just* when protocol changes. It is not very obvious.*//** Version 28:* Declare methods in DataTransferProtocol interface.*/int DATA_TRANSFER_VERSION = 28;/*** Read a block.** @param blk the block being read.* @param blockToken security token for accessing the block.* @param clientName client's name.* @param blockOffset offset of the block.* @param length maximum number of bytes for this read.* @param sendChecksum if false, the DN should skip reading and sending* checksums* @param cachingStrategy The caching strategy to use.** 从当前Datanode读取指定的数据块。*/void readBlock(final ExtendedBlock blk,final Token<BlockTokenIdentifier> blockToken,final String clientName,final long blockOffset,final long length,final boolean sendChecksum,final CachingStrategy cachingStrategy) throws IOException;/*** 将指定数据块写入数据流管道(pipeLine)中。* Write a block to a datanode pipeline.* The receiver datanode of this call is the next datanode in the pipeline.* The other downstream datanodes are specified by the targets parameter.* Note that the receiver {@link DatanodeInfo} is not required in the* parameter list since the receiver datanode knows its info. However, the* {@link StorageType} for storing the replica in the receiver datanode is a* parameter since the receiver datanode may support multiple storage types.** @param blk the block being written.* @param storageType for storing the replica in the receiver datanode.* @param blockToken security token for accessing the block.* @param clientName client's name.* @param targets other downstream datanodes in the pipeline.* @param targetStorageTypes target {@link StorageType}s corresponding* to the target datanodes.* @param source source datanode.* @param stage pipeline stage.* @param pipelineSize the size of the pipeline.* @param minBytesRcvd minimum number of bytes received.* @param maxBytesRcvd maximum number of bytes received.* @param latestGenerationStamp the latest generation stamp of the block.* @param requestedChecksum the requested checksum mechanism* @param cachingStrategy the caching strategy* @param allowLazyPersist hint to the DataNode that the block can be* allocated on transient storage i.e. memory and* written to disk lazily* @param pinning whether to pin the block, so Balancer won't move it.* @param targetPinnings whether to pin the block on target datanode* @param storageID optional StorageIDs designating where to write the* block. An empty String or null indicates that this* has not been provided.* @param targetStorageIDs target StorageIDs corresponding to the target* datanodes.*/void writeBlock(final ExtendedBlock blk,final StorageType storageType,final Token<BlockTokenIdentifier> blockToken,final String clientName,final DatanodeInfo[] targets,final StorageType[] targetStorageTypes,final DatanodeInfo source,final BlockConstructionStage stage,final int pipelineSize,final long minBytesRcvd,final long maxBytesRcvd,final long latestGenerationStamp,final DataChecksum requestedChecksum,final CachingStrategy cachingStrategy,final boolean allowLazyPersist,final boolean pinning,final boolean[] targetPinnings,final String storageID,final String[] targetStorageIDs) throws IOException;/*** 将指定数据块复制(transfer)到另一个Datanode上。** 数据块复制操作是指数据流管道中的数据节点出现故障,* 需要用新的数据节点替换异常的数据节点时,* DFSClient会调用这个方法将数据流管道中异常数据节点上已经写入的数据块复制到新添加的数据节点上。** Transfer a block to another datanode.* The block stage must be* either {@link BlockConstructionStage#TRANSFER_RBW}* or {@link BlockConstructionStage#TRANSFER_FINALIZED}.** @param blk the block being transferred.* @param blockToken security token for accessing the block.* @param clientName client's name.* @param targets target datanodes.* @param targetStorageIDs StorageID designating where to write the* block.*/void transferBlock(final ExtendedBlock blk,final Token<BlockTokenIdentifier> blockToken,final String clientName,final DatanodeInfo[] targets,final StorageType[] targetStorageTypes,final String[] targetStorageIDs) throws IOException;/*** 获取一个短路(short circuit)读取数据块的文件描述符* Request short circuit access file descriptors from a DataNode.** @param blk The block to get file descriptors for.* @param blockToken Security token for accessing the block.* @param slotId The shared memory slot id to use, or null* to use no slot id.* @param maxVersion Maximum version of the block data the client* can understand.* @param supportsReceiptVerification True if the client supports* receipt verification.**/void requestShortCircuitFds(final ExtendedBlock blk,final Token<BlockTokenIdentifier> blockToken,SlotId slotId, int maxVersion, boolean supportsReceiptVerification)throws IOException;/*** 释放一个短路读取数据块的文件描述符。* Release a pair of short-circuit FDs requested earlier.** @param slotId SlotID used by the earlier file descriptors.*/void releaseShortCircuitFds(final SlotId slotId) throws IOException;/*** 获取保存短路读取数据块的共享内存* Request a short circuit shared memory area from a DataNode.** @param clientName The name of the client.*/void requestShortCircuitShm(String clientName) throws IOException;/*** 将从源Datanode复制来的数据块写入本地Datanode。* 写成功后通 知NameNode,并且删除源Datanode上的数据块。** 这个方法主要用在数据块平衡 操作(balancing)的场景下。* source datanode 和 original datanode 必须不同.** Receive a block from a source datanode* and then notifies the namenode* to remove the copy from the original datanode.* Note that the source datanode and the original datanode can be different.* It is used for balancing purpose.** @param blk the block being replaced.* @param storageType the {@link StorageType} for storing the block.* @param blockToken security token for accessing the block.* @param delHint the hint for deleting the block in the original datanode.* @param source the source datanode for receiving the block.* @param storageId an optional storage ID to designate where the block is* replaced to.*/void replaceBlock(final ExtendedBlock blk,final StorageType storageType,final Token<BlockTokenIdentifier> blockToken,final String delHint,final DatanodeInfo source,final String storageId) throws IOException;/*** Copy a block.* It is used for balancing purpose.** 复制当前Datanode上的数据块。这个方法主要用在数据块平衡操作 的场景下。** @param blk the block being copied.* @param blockToken security token for accessing the block.*/void copyBlock(final ExtendedBlock blk,final Token<BlockTokenIdentifier> blockToken) throws IOException;/*** 获取指定数据块的校验值。* Get block checksum (MD5 of CRC32).** @param blk a block.* @param blockToken security token for accessing the block.* @param blockChecksumOptions determines how the block-level checksum is* computed from underlying block metadata.* @throws IOException*/void blockChecksum(ExtendedBlock blk,Token<BlockTokenIdentifier> blockToken,BlockChecksumOptions blockChecksumOptions) throws IOException;/*** Get striped block group checksum (MD5 of CRC32).** @param stripedBlockInfo a striped block info.* @param blockToken security token for accessing the block.* @param requestedNumBytes requested number of bytes in the block group* to compute the checksum.* @param blockChecksumOptions determines how the block-level checksum is* computed from underlying block metadata.* @throws IOException*/void blockGroupChecksum(StripedBlockInfo stripedBlockInfo,Token<BlockTokenIdentifier> blockToken,long requestedNumBytes,BlockChecksumOptions blockChecksumOptions) throws IOException;}

若有收获,就点个赞吧
0 人点赞
