摘自:「百度百科」
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体喜好来推荐用户感兴趣信息,个人通过合作机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
认识协同过滤
协同过滤(Collaborative Filtering,CF)是使用「行为数据」,利用「集体智慧」的算法,其实现分为两大类:
- 基于数理统计(记忆)
- 基于模型参数(学习)
这里主要介绍基于数理统计的CF。
计算相似度
使用协同过滤前首先要计算相似度。让我们从案例开始:
有如下用户对物品(I)评分的二维表格:
| I1 | I2 | I3 | I4 | I5 | I6 | I7 | |
|---|---|---|---|---|---|---|---|
| A | 4 | 5 | 1 | ||||
| B | 5 | 5 | 4 | 5 | |||
| C | 2 | 4 | |||||
| D | 3 | 3 |
表格记录用户对物品的评分,如用户A对I1的评分为4。那如何量化用户与用户之间的相似度呢?
- Jaccard相似度
Jaccard相似度利用共同喜好物品的数量占比来进行预估: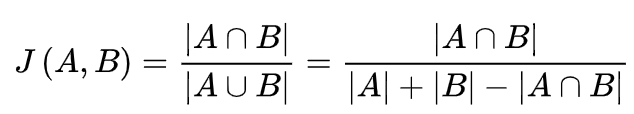
- A∩B:表示用户A和用户B同时喜好物品的数量
- A∪B:表示用户A喜好物品数量和用户B喜好物品数量
如果用代码来表示的话:
public static void main(String[] args) {Integer[] a = new Integer[] { 4, null, null, 5, 1, null, null };Integer[] b = new Integer[] { 5, 5, 4, null, null, null, null };Integer[] c = new Integer[] { null, null, null, 2, 4, 5, null };Integer[] d = new Integer[] { null, 3, null, null, null, null, 3 };distance(a, b);distance(a, c);distance(a, d);}public static void distance(Integer[] x1, Integer[] x2) {double ab = 0d;double a = 0d;double b = 0d;for (int i = 0; i < x1.length; i++) {if (x1[i] != null && x2[i] != null) {ab++;}if (x1[i] != null) {a++;}if (x2[i] != null) {b++;}}System.out.println(ab / (a + b - ab));}
从结果可知「J(A,B) = 1/5 < J(A,C) = 2/4」,用户C比用户B更接近用户A。
同时对于Java,已经有比较好的代码包支持:
public static void main(String[] args) {Integer[] a = new Integer[] { 4, null, null, 5, 1, null, null };Integer[] b = new Integer[] { 5, 5, 4, null, null, null, null };Integer[] c = new Integer[] { null, null, null, 2, 4, 5, null };Integer[] d = new Integer[] { null, 3, null, null, null, null, 3 };distance(a, b);distance(a, c);distance(a, d);}public static void distance(Integer[] x1, Integer[] x2) {JaccardSimilarity s = new JaccardSimilarity();StringBuffer bf1 = new StringBuffer();StringBuffer bf2 = new StringBuffer();for (int i = 0; i < x1.length; i++) {if (x1[i] != null) {bf1.append(i);}if (x2[i] != null) {bf2.append(i);}}System.out.println(s.apply(bf1, bf2));}
但Jaccard相似度也有其缺点,就是「没有考虑评分本身」。
- 余弦相似度
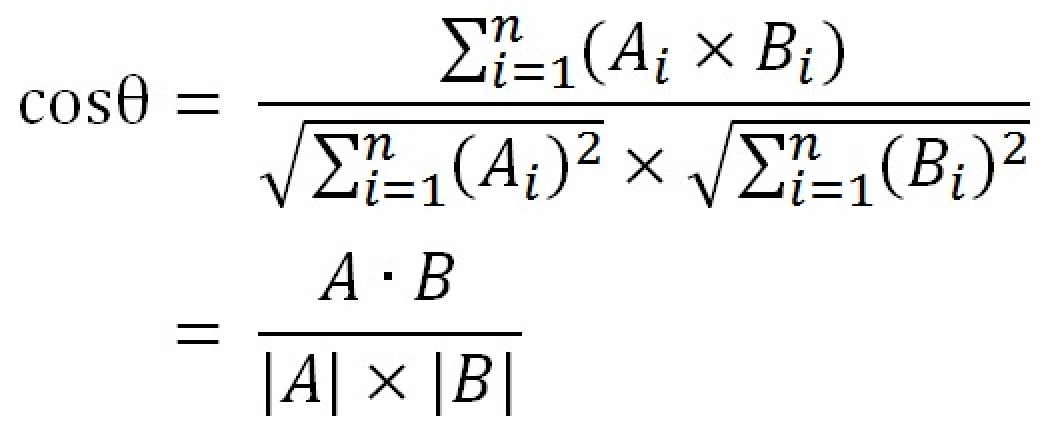
余弦相似度是另一种衡量相似度的公式,先从代码来看:
public static void main(String[] args) {
Integer[] a = new Integer[] { 4, null, null, 5, 1, null, null };
Integer[] b = new Integer[] { 5, 5, 4, null, null, null, null };
Integer[] c = new Integer[] { null, null, null, 2, 4, 5, null };
Integer[] d = new Integer[] { null, 3, null, null, null, null, 3 };
distance(a, b);
distance(a, c);
distance(a, d);
}
public static void distance(Integer[] x1, Integer[] x2) {
double ab = 0d;
double a = 0d;
double b = 0d;
for (int i = 0; i < x1.length; i++) {
double _x1 = x1[i] != null ? x1[i] : 0;
double _x2 = x2[i] != null ? x2[i] : 0;
ab += _x1 * _x2;
a += _x1 * _x1;
b += _x2 * _x2;
}
System.out.println(ab / (Math.sqrt(a) * Math.sqrt(b)));
}
从结果可知「Cos(A,B) = 0.38 > Cos(A,C) = 0.32」,用户B比用户C更接近用户A。
当然余弦相似度同样有其缺点,就是「缺失值默认为0」,解释为用户对物品没有行为那么「喜好就是0」。
同时对于Java,同样有比较好的代码包支持:
public static void main(String[] args) {
Integer[] a = new Integer[] { 4, null, null, 5, 1, null, null };
Integer[] b = new Integer[] { 5, 5, 4, null, null, null, null };
Integer[] c = new Integer[] { null, null, null, 2, 4, 5, null };
Integer[] d = new Integer[] { null, 3, null, null, null, null, 3 };
distance(a, b);
distance(a, c);
distance(a, d);
}
public static void distance(Integer[] x1, Integer[] x2) {
JaccardSimilarity s = new JaccardSimilarity();
StringBuffer bf1 = new StringBuffer();
StringBuffer bf2 = new StringBuffer();
for (int i = 0; i < x1.length; i++) {
if (x1[i] != null) {
bf1.append(i);
}
if (x2[i] != null) {
bf2.append(i);
}
}
System.out.println(s.apply(bf1, bf2));
}
- 皮尔逊相关系数(传送门)
最后一种相似度计算方式为皮尔逊相关系数。对于余弦相似度不同的是,皮尔逊相关系数计算相似度时「使用平均值替代缺失值」。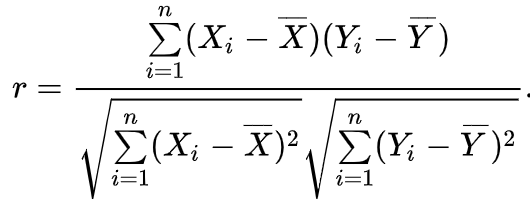
先从代码来看:
public static void main(String[] args) {
Integer[] a = new Integer[] { 4, null, null, 5, 1, null, null };
Integer[] b = new Integer[] { 5, 5, 4, null, null, null, null };
Integer[] c = new Integer[] { null, null, null, 2, 4, 5, null };
Integer[] d = new Integer[] { null, 3, null, null, null, null, 3 };
distance(a, b);
distance(a, c);
distance(a, d);
}
public static void distance(Integer[] x1, Integer[] x2) {
PearsonsCorrelation p = new PearsonsCorrelation();
double[] _x1 = new double[x1.length];
double[] _x2 = new double[x2.length];
Mean m1 = new Mean();
Mean m2 = new Mean();
for (int i = 0; i < x1.length; i++) {
if (x1[i] != null) {
m1.increment(x1[i]);
}
if (x2[i] != null) {
m2.increment(x2[i]);
}
}
for (int i = 0; i < x1.length; i++) {
_x1[i] = x1[i] != null ? x1[i] : m1.getResult();
_x2[i] = x2[i] != null ? x2[i] : m2.getResult();
}
System.out.println(System.out.println(p.correlation(_x1, _x2)););
}
从结果可知「P(A,B) = 0.09 > P(A,C) = -0.56」,这里会有两个结论:
- 用户B比用户C更接近用户A
- 用户C与用户A不相似(负相关),喜好相悖。
协同评分
以上我们已经计算出了所有用户之间的相似度了,那如何预估用户A对于I5的喜好呢?
假设以下二维表格,其中用户A与用户B和用户C最相似,求预估用户A对于I5的喜好。
| I1 | I2 | I3 | I4 | I5 | I6 | I7 | |
|---|---|---|---|---|---|---|---|
| A | 4 | 5 | |||||
| B | 5 | 5 | 4 | 3 | 5 | ||
| C | 2 | 5 | |||||
| D | 3 | 3 |
- 方法1,直接平均
Sim(A,I5) = (3 + 5) / 2 = 4
- 方法2,加权平均
- 已经得知用户B的相似度为0.38,用户C的相似度为0.32
- Sim(A,I5) = (3 0.38 + 5 0.32) / (0.38 + 0.32) = 3.91
优化协同
协同过滤可以分为两种维度的评分:
- 基于用户的协同过滤
称之为U2U2I,表示为和用户A喜好相同的用户B也喜欢物品X。是假设喜好类似的人喜欢的物品也高度相似。
适用于用户增速小于物品增速的场景(新闻,内容)
- 基于物品的协同过滤
称之为U2I2I,表示为喜好物品X的用户A也喜好物品Y。是假设物品与物品间存在相似度,通过同时喜好两个物品的用户来体现。
适用于物品增速小于用户增速的场景(电商,电影)
更多参考
- 【怎样实现基于协同过滤的推荐系统-哔哩哔哩】

若有收获,就点个赞吧
0 人点赞
