摘自:「简书」
威尔逊得分排序算法,Wilson Score,用于质量排序,数据含有好评和差评,综合考虑评论数与好评率,得分越高,质量越高。
案例入手
假设项目A是60张赞成票40张反对票,项目B是550张赞成票450张反对票,哪个更好呢?
- 如果只是简单计算好评率?
- 项目A => 60%,项目B => 55%
- 以结果来看,貌似项目A更好吧。
- 威尔逊算法场景
威尔逊算法是基于用户行为的排序算法,所以要排序的东西,不管是文章、商品或者评论等等。同时算法数据需要具备「二项式分布(伯努利实验)」的特性,即有好坏才适合用这个算法。二项式分布的置信区间有多种计算公式,最常见的是正态区间,教科书里几乎都是这种方法。但是它只适用于样本较多的情况np > 5且n(1 − p) > 5,对于小样本的准确性很差。
1927年美国数学家威尔逊提出了一个修正公式,被称为「威尔逊区间」,很好地解决了小样本的准确性问题。威尔逊算法需要具备如下特性:
- 每次事件都独立,互不影响
- 每次结果只有两种(赞同或拒绝,0或1)
- 重复n次后,赞同数为u,赞同率为p = u/n
威尔逊算法公式
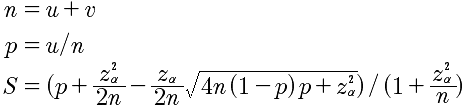
需要注意的是Z参数,表示对应某个置信水平的Z统计量,这是一个常数,可以通过查表或统计软件得到。一般情况下在95%的置信水平下,Z统计量的值为1.96。
这样一来,算法的思路就比较清晰了:- 计算每个Case的P值(比如好评率)
- 负样本为0,P值为1则S为1(最高得分)
- 正样本为0,P值为0则S为0(最差得分)
- P值不变,正样本越大,分子减少速度小于分母减少速度(得分越高)
- 计算每个好评率的置信区间(如Z Test或T Test)
- 根据置信区间的「下限值」进行排名,值越大排名越高
- 计算每个Case的P值(比如好评率)
Show Me The Code
对于Java,已经有比较好的代码包支持:
import org.apache.commons.math3.stat.interval.WilsonScoreInterval;public class Main {public static void main(String[] args) {WilsonScoreInterval score = new WilsonScoreInterval();System.out.println(score.createInterval(100, 60, 0.95));System.out.println(score.createInterval(1000, 550, 0.95));}}
可知第一组得分为0.5020,而第二组的得分为0.5190,是不是违背直觉?
对于其他语言,提供如下伪代码:
public static double compute(double p, double z, int n) {double u = p + (z * z) / (2 * n) - z / (2 * n) * Math.sqrt(4 * n * (1 - p) * p + z * z);double l = 1 + (z * z) / n;return u / l;}System.out.println(Main.compute(550/1000d, 1.959964, 1000));System.out.println(Main.compute(60/100d, 1.959964, 100));
其中参数p表示二项式分布中的成功概率,参数z表示Z统计量,参数n表示样本总量
**
调整适应正态分布
虽然威尔逊算法基于二项式分布,但从二项式分布特性来看,当样本总量n足够大时可以采用正态分布替代二项式分布。所以威尔逊算法在进行一定调整后也支持正态分布。
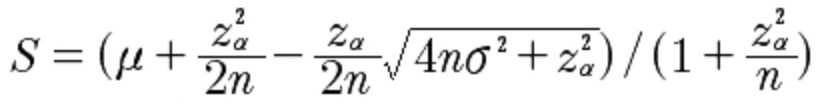
- σ为正态分布的样本标准差
- μ为正态分布的样本平均值

若有收获,就点个赞吧
0 人点赞
