混淆矩阵
在介绍指标之前,首先需要了解下二分类问题的混淆矩阵,即通过模型对数据进行分类后得到「预测」的「正例」和「负例」与「真实」的「正样本」和「负样本」的对比统计。
| 真实「正样本」 | 真实「负样本」 | |
|---|---|---|
| 预测「正例」 | TP(True Positive) | FP(False Positive) |
| 预测「负例」 | FN(False Negative) | TN(True Negative) |
模型指标
- 准确率(正确率,Acc,Accuracy)
表示所有预测样本中「正确判断」正样本和负样本的比例。比如一张全是判断题的考卷,所有判断正确的题目总和即最终考试成绩。不过在正负样本「比例不均衡」的情况下时意义并不大,就好比一张考卷如果99%的答案都为否,那么只要答案时全部答否就能得到99分,兰德系数(传送门)。
- ACC =(TP + TN)/(TP + FP + FN + TN)
- 精确率(查准率,P,Precision)
表示所有「预测为正例」的样本中「预测成功」的数量。例如推荐场景中把点击的样本视为正样本,相比未展示推荐的用户,我们更关心展示推荐(预测为正例)的样本中的用户点击了多少,点击的样本比例越高精确性越高,模型就越有效。
- P = TP /(TP + FP)
- 召回率(查全率,灵敏度,R,Recall)
表示所有「应当为正例」的样本中「预测成功(召回)」了多少。例如风控场景把最终违约的样本视为正样本,相比正常履约的用户,我们更关心最终违约(应当为正例)的样本中的用户实际提前找出了多少,提前找出的真实违约样本比例越高则召回率越高,可以提前防止损失的资金也就越多,模型就越有效。
- R = TP /(TP + FN)
- 真正率(True Positive Rate,TPR)
真正率与召回率一致,表示所有「应当为正例」的样本中「预测成功」的比例。
- TPR = TP /(TP + FN)= Recall
- 假正率(False Positive Rete,FPR)
表示所有「应当为负例」的样本中「预测失败(被错误预测为正例)」的比例。
- FPR = FP /(FP + TN)
评估方法
- P-R曲线与Fβ-Measure
提高精确率(策略更谨慎)与提高召回率(策略更激进)往往是此消彼长的指标,我们可以使用「P-R曲线」来表达他们之间的关系。绝大多数分类模型都可以对测试集中每个样本做出「实值和概率」的预测。首先选择一个分类阈值,将「概率」大于阈值的判断为「正例」反之判断为「负例」,然后将测试样本按模型预测值「从大到小」排序,最后「顺序依次选择」样本预测值作分类阈值就可以得到多个混淆矩阵与对应的P和R值。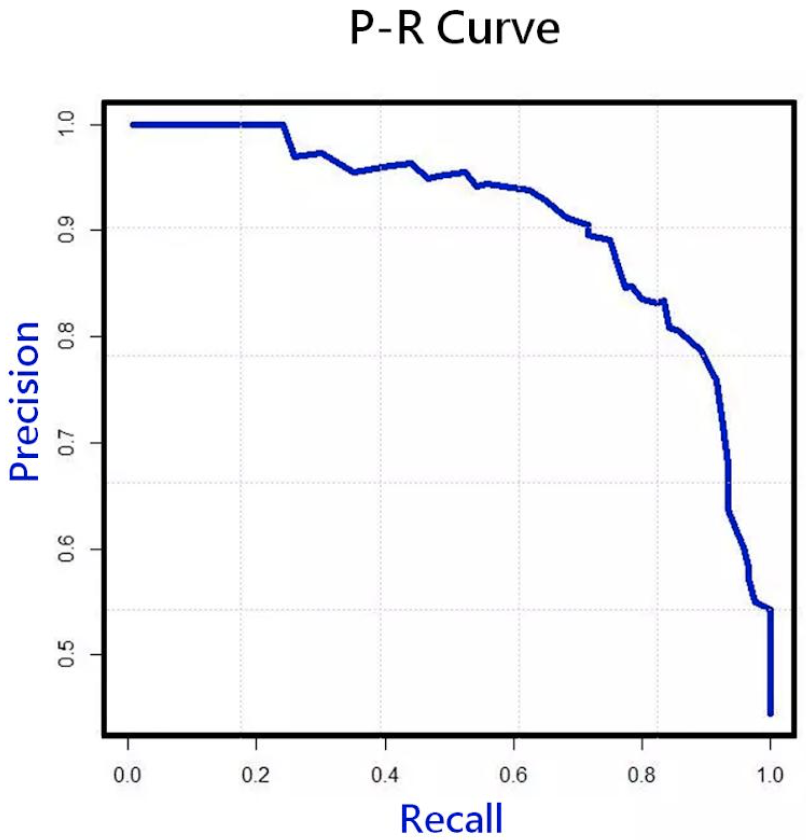
考虑业务对「精确率」和「召回率」侧重性,会引入综合指标「Fβ-Measure」来比较优劣。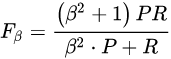
其中β ∈ [0,∞],当β为0时指标Fβ = P即精确率,当β为∞时指标Fβ = R即召回率。当β = 1时指标F1 = 2PR /(P + R)即F1-Measure,精确率与召回率的「调和平均数」。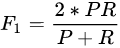
- ROC曲线与AUC
如同「P-R曲线」使用分类阈值对测试集每个样本的分类,「ROC曲线」将分类应用在了「真正率,TPR」和「假正率,FPR」的指标上。
- 当分类阈值为「最大预测值」时所有测试样本均预测为负例
- 按定义可得TPR = FPR = 0
- 当分类阈值为「最小预测值」时所有测试样本均预测是正例
- 按定义可得TPR = FPR = 1
遍历所有预测值为分类阈值后可以描绘横坐标为「假正率」,纵坐标为「真正率」的曲线称之为「ROC曲线」,用于评估哪种选择会更好。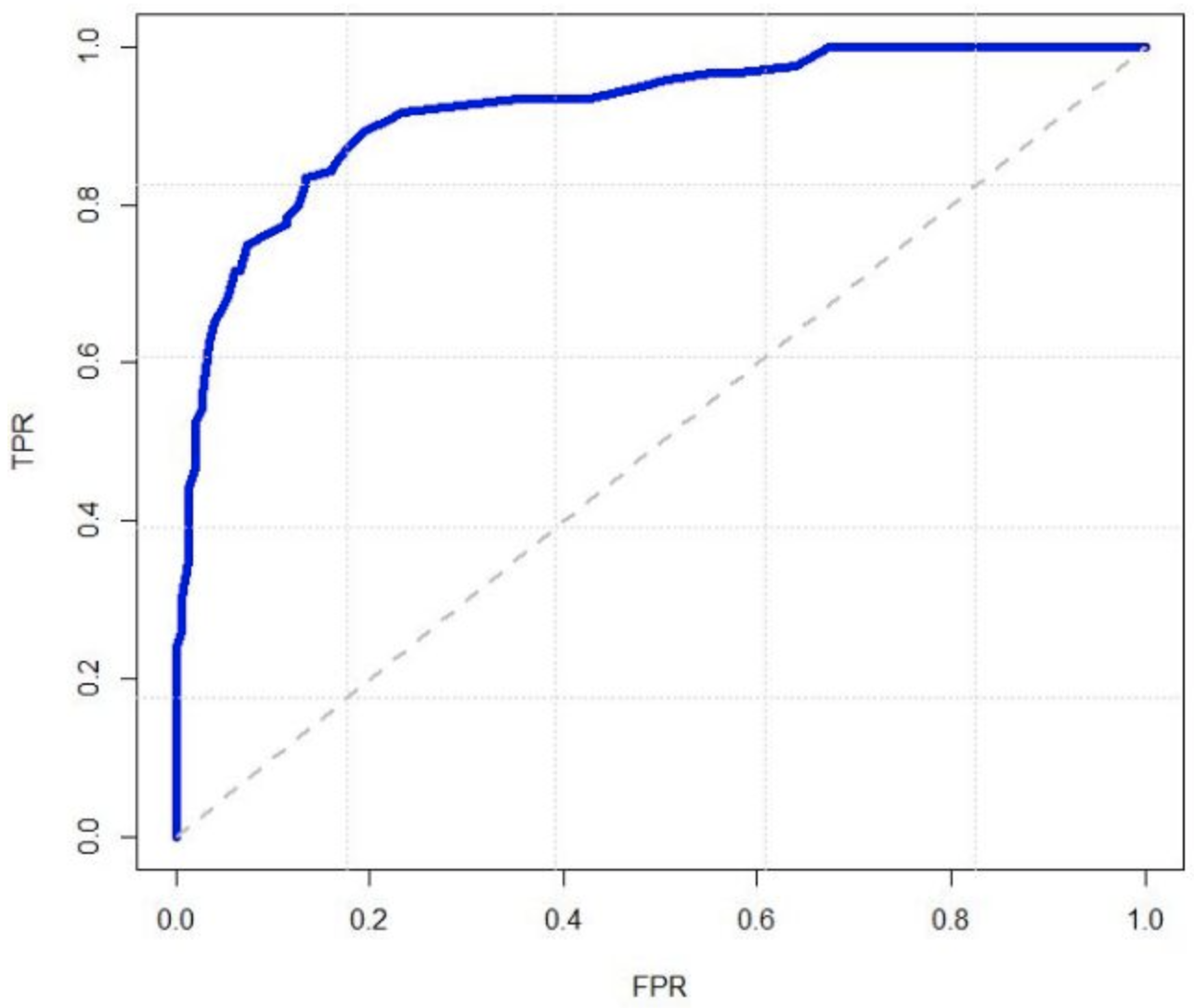
如何通过ROC曲线进行选择?假如模型A的ROC曲线「完全包住」模型B的,即任意FPR取值时A模型的TPR均大于B模型,就可以得出「A模型优于B模型」的结论。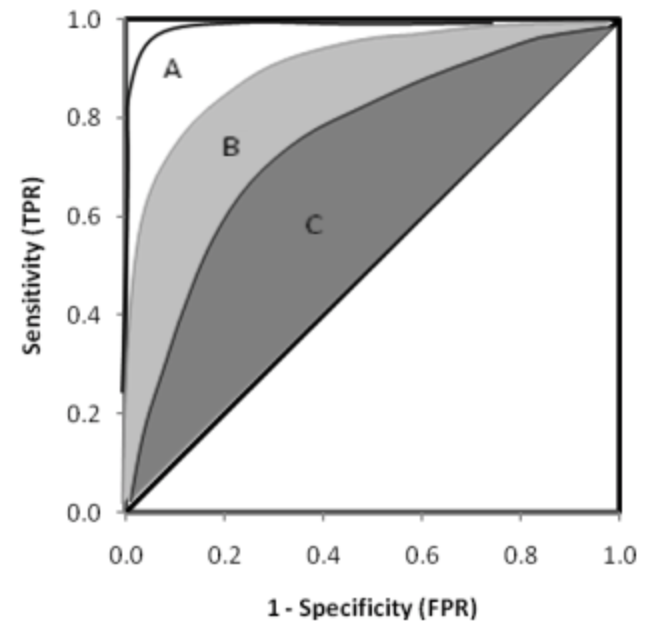
同时可以使用综合指标AUC(Area Under ROC Curve,ROC曲线下面积)评估:
- AUC = 1,效果上限,几乎不可能达到的完美基准。
- 0.5 < AUC < 1,大部分基准的得分,得分越高越有效。
- AUC = 0.5,随机分类模型的基准。
- AUC < 0.5,低于基准,负向模型。
- Lift曲线
表示与「先验精确率,PRE」相比,不同分类阈值下模型「精确率」的倍数。这里「先验精确率,PRE」即为所有测试样本中正样本占比。那么「Lift值」为: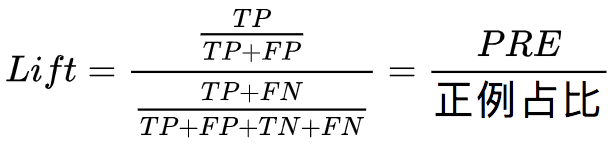
如果将横坐标定义为分类阈值并按「从大到小」的顺序预测正样本占比。纵轴定义为对应分类阈值下的「Lift值」则可以的出对应曲线: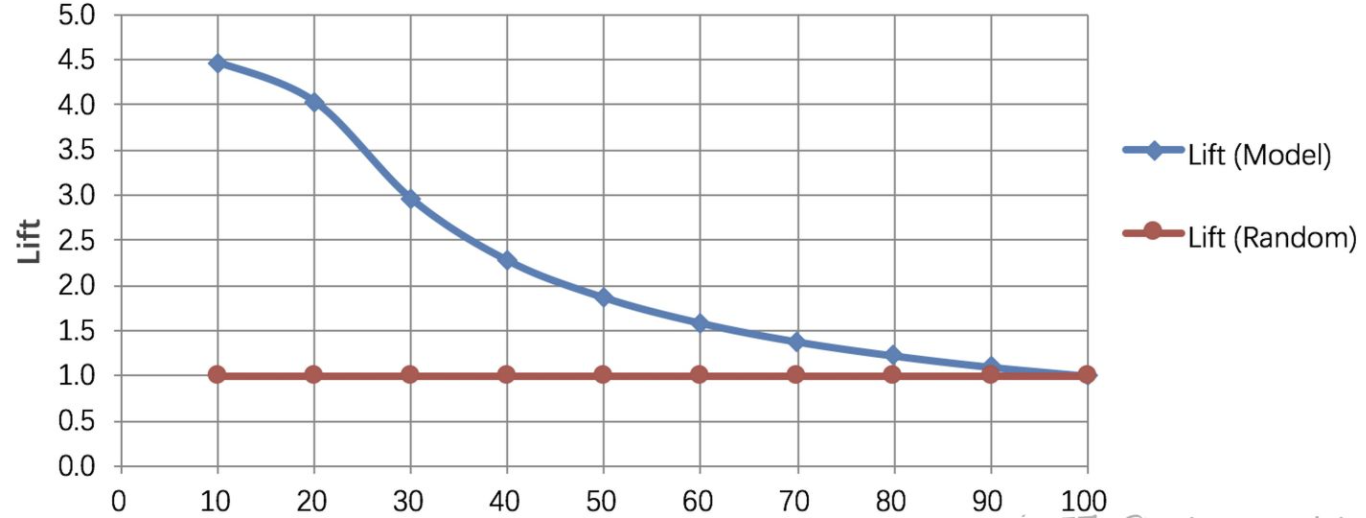
从图像可以观测到,模型对前10%的样本预测分类的精确率是随机策略的4.5倍。「Lift曲线」描述的是与「不利用」模型相比,「利用」模型的预测能力「变好」了多少,指数越大模型的运行效果越好。
- K-S曲线(Kolmogorov-Smirnov)
与「ROC曲线」类似用于评估「真正率TPR」和「假正率FPR」,但与之不同的是其横轴与「Lift曲线」的横轴一致,而纵轴则是对应分类阈值下的TPR与FPR取值。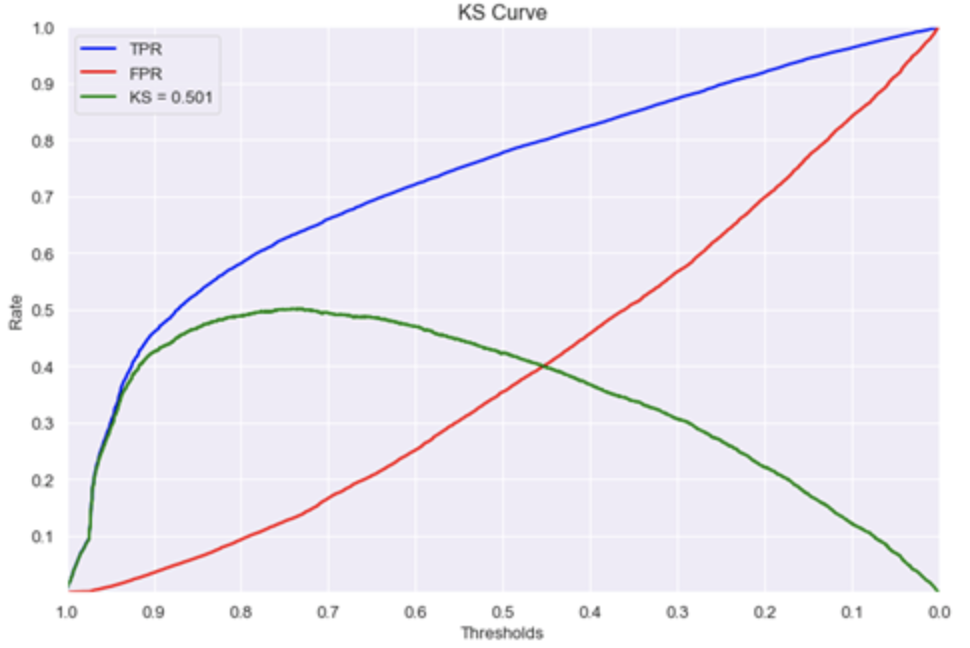 >
>
从图像可以观测到「真正率TPR」与「假正率FPR」之间的「差距TPR - FPR」越大意味着在这一分类阈值下模型能够「尽可能多」的正确找出正样本和「尽可能少」的误判负样本。一些基本参考值如下:
- KS < 0.2,没有区分能力。
- 0.2 < KS < 0.3,具有一定区分能力,勉强可以接受。
- 0.3 < KS < 0.5,具有较强的区分能力。
- KS > 0.75,往往表示有异常。
在没有模型异常的情况下,利用「最值唯一性」,使用TPR-FPR「最高点」作为模型能力的评估标准。
- MAE、MSE
在一些例如「消费额度预估」、「配送时间预估」等业务场景中从混淆矩阵出发进行评估就不再适用了,这时「平均绝对误差,MAE」就可以比较好的评估「预测结果」与「真实结果」之间的「差异」。
与MAE配合评估的包括「均方误差,MSE」和「均方根误差,RMSE」,这些误差越小意味着预测结果与真实结果的平均差异越小,模型结果与真实世界越接近。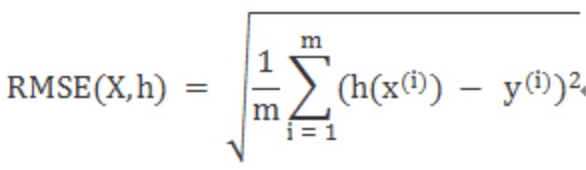
- Residual
残差即估计值与真实值之差。在理想线性模型五大假设其中之一便是「残差应该是正态分布且与估计值无关」。如果残差和估计值有关则说明模型仍然有值得去改进的地方。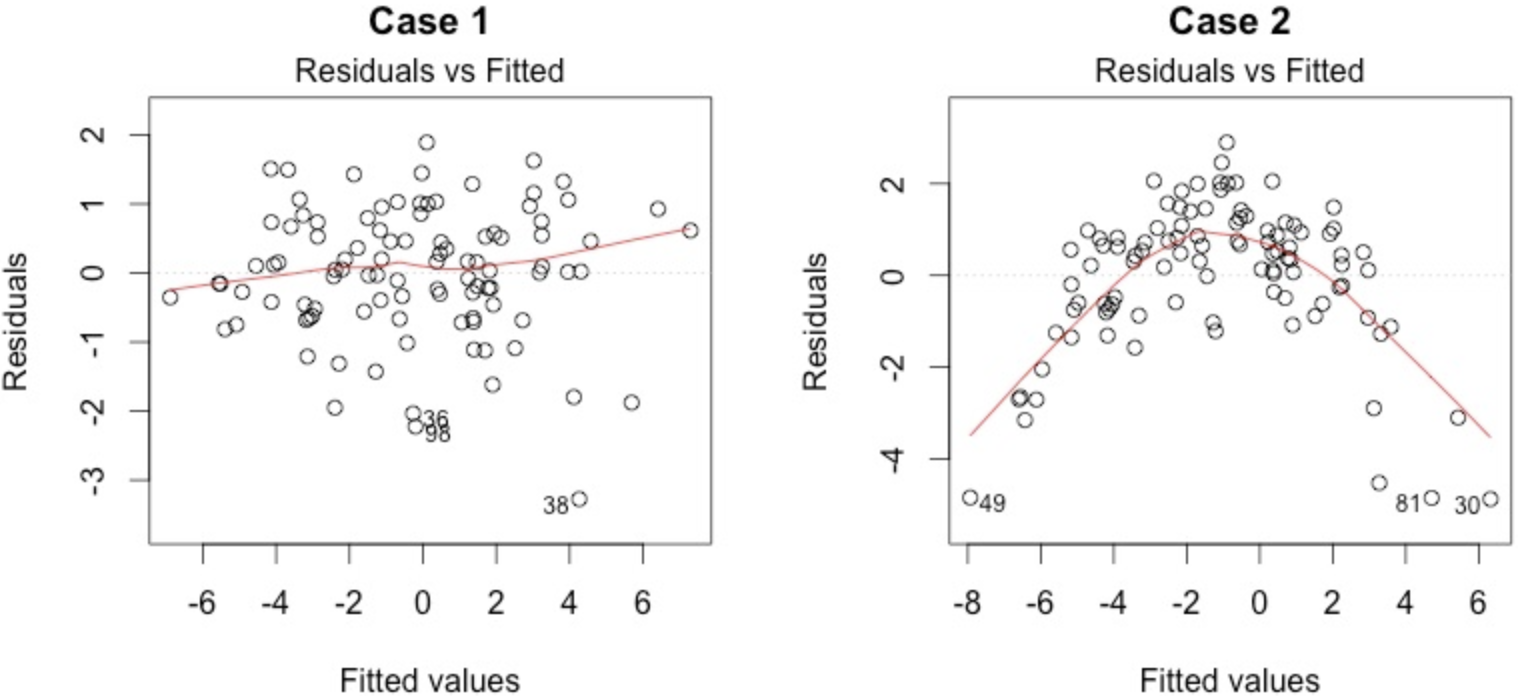
左边残差和估计值「基本无关」但右边残差和估计值几乎成二次关系,那么模型就需要进行修正。
可以通过「Kolmogorov-Smirnov(KS,传送门)」测试残差和估计值是否有关。
[
](https://www.yuque.com/shenjiawei-ejwcz/ie5l6h/rv2wpo)
[
](https://blog.csdn.net/qq_35837578/article/details/88357551)

若有收获,就点个赞吧
0 人点赞
