模型特征又称为策略因子或线索,可以选择的范围非常广泛。可以是「静态信息」(例如用户画像)也可以是「动态信息」(例如用户最近一段时间的行为)。合适的模型特征可以提供更多的信息量用于业务推断。
基于收益的选择方法
进行特征选择最终还是为了模型收益,那么从提高「模型收益」的路径出发进行特征选择不失为一种非常直接的方法。
- 前向启发式
从「空集」开始,每次从「剩余特征」中「加入」一个特征构成新的「特征子集」。同时把评估结果最好的特征子集留下,迭代加入特征直到无法提升或达到评估阈值。
- 后向启发式
从「全集」开始,每次从「当前特征」中「去除」一个特征构成新的「特征子集」。同时把评估结果最好的特征子集留下,迭代加入特征直到无法提升或达到评估阈值。
基于指标的选择方法
- 覆盖率
假如有一个特征有效数据只能「覆盖少量」样本且其余均为「未知数据」。那么这个特征能够带来的业务「收益上限」不超过这个特征的覆盖率。例如信贷风控业务中,假如通过一些外部数据获取了0.1%用户的收入数据则意味着即使这个特征有足够的「区分度」,但对于业务上准确率提升上限也只有0.1%(即至多只有0.1%的用户因为该特征的引入被准确预测)。
- 差异度
不同样本在同一特征值上「差异越小」意味着「区分越低」。极端情况下假如所有样本这一特征的取值都一样,则无法从这个特征获取任何信息。用「方差」的大小来衡量这种差异。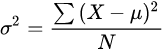
- 区分度
- Pearson相关系数(传送门)
使用「协方差」计算两个变量之间的「线性相关性」,如果两组特征存在相关性则可以降维为一个减少复杂度。
公式本身并不复杂并且相关介绍资料充裕「【十分钟理解协方差和相关系数-哔哩哔哩】https://b23.tv/CVGS7L」。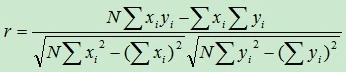
对于Java,已经有比较好的代码包支持:
double[] x = new double[] { 0.98, 0.96, 0.96, 0.94, 0.925, 0.9025, 0.875 };double[] y = new double[] { 1, 1, 1, 1, 0.961483893, 0.490591662, 0.837341784 };PearsonsCorrelation p = new PearsonsCorrelation();System.out.println(p.correlation(x, y));
- F分布、F检验
著名的统计学「三大分布」之一的「F分布(传送门)」有着广泛的应用,在方差分析、回归方程的显著性检验中都有着重要的地位。其中方差分析(Analysis of Variance)也就是著名的「ANOVA」,通过「假设检验」思想分析多个特征及其标签值是否具备「显著性差异」,如果具备则可以认为特征间是具备一定区分度的。
- T分布、T检验
著名的统计学三大分布之一的「T分布(传送门)」有着和F分布类似的作用,但与F分布使用「方差齐性」原理不同的是T分布背后的支撑理论是著名的「中心极限定理」。
- 卡方分布、卡方检验
著名的统计学三大分布最后出场的是「卡方分布(传送门)」。不同于T分布和F分布用于「数值变量」,卡方分布的适用场景是「类别变量」。
- 信息熵
摘自:「百度百科」
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有 多少信息量。直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
「信息熵(传送门)」源自「信息论」,是对「随机事件不确定性」的度量。借助信息熵的度量方法可以评估引入的特征是否可以带来更多的信息增益及更好的区分度。我们经常会使用的信息熵为「相对熵(Relative Entropy)」也称为「KL散度」。
[

若有收获,就点个赞吧
0 人点赞
