摘自:「百度百科」
邻近算法或者说K最近邻(KNN)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
物以类聚,人以群分
「寻找最近的K个数据,推测新数据的分类」
这是KNN的基础思想,要判断一个新数据的类别就看他的邻居都是谁。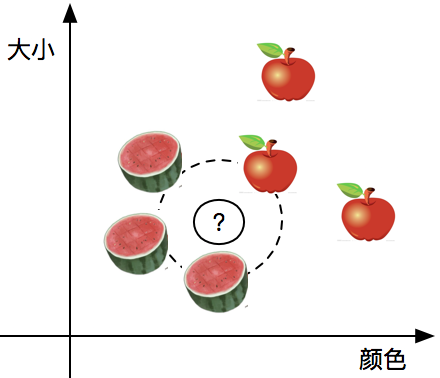
假设任务是分类水果,已知分类有「西瓜」和「苹果」。
- 通过观察样本「大小和颜色」确定在「坐标系」中的位置
- 如果周围「西瓜」多则确认是西瓜,反之则确认是「苹果」
其中KNN中的「K」指的是「K个」邻居。例如「K = 3」则表示离样本「距离」最近的「3个」样本来判断样本类别。
- 大小和颜色是数据的「特征」
- 西瓜和苹果是数据的「标签」
距离(传送门)则可以选择「曼哈顿距离、欧式距离、切比雪夫距离」中的符合实际业务的算法。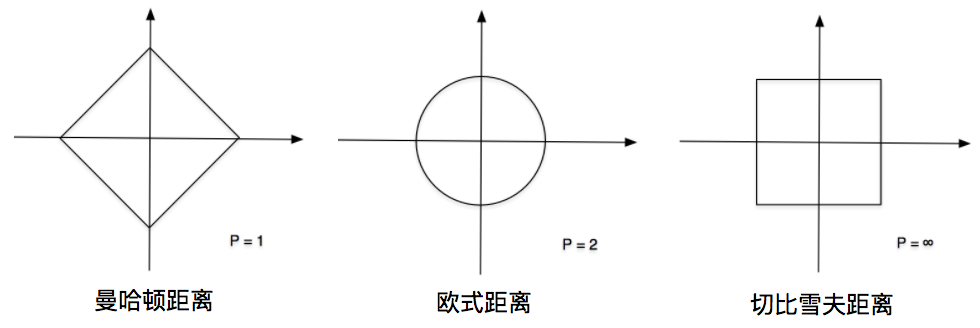
对于KNN来说「K」的取值非常重要。
- 如果「K太小」如「K = 1」则可能受到距离最近的个例数据影响,导致波动较大
- 如果「K太大」如「K = 9」则可能受到距离较远的特殊数据影响,导致分类模糊
K取受「问题自身和数据集大小」决定,不同问题K取值不同。可以参考经验或「均方根误差,RMSE(传送门)」。
总结来说,KNN算法就是在定义好「距离和K值」前提下,对于任意「新样本」将其「分类为」与该样本「距离最近」的「K个样本」中「类别最多」的那个类别。
计算步骤
- 已知「样本S」

- Xi:表示平面坐标系上坐标(如(a1,b1)(a2,b2))
- Yi:表示样本所属类别(如Yi ∈ {C1,C2} )
- 计算距离(常用为欧式距离)
- 计算「Xi」间的距离
- 升序排序
- 如果距离选择欧式距离且「K = 1」时称为「最近邻模型」
- 取前「K个」
- 加权平均
- TopK个样本中「类别最多」的样本为「参数类别」
参考视频
- 【什么是KNN(K近邻算法)?【知多少】-哔哩哔哩】
- 【【智源学院】30分钟KNN算法-有意思专题系列(K-Nearest Neighbor, KNN)-哔哩哔哩】

若有收获,就点个赞吧
0 人点赞
