向量距离
摘自:「博客园」
机器学习是时下流行AI技术中一个很重要的方向,无论是有监督学习还是无监督学习都使用各种「度量」来得到不同样本数据的差异度或者不同样本数据的相似度。良好的「度量」可以显著提高算法的分类或预测的准确率。
- 闵可夫斯基距离(Minkowski Distance)
摘自:「百度百科」
闵氏空间指狭义相对论中由一个时间维和三个空间维组成的时空,为俄裔德国数学家闵可夫斯基最先表述。他的平坦空间(即假设没有重力,曲率为零的空间)的概念以及表示为特殊距离量的几何学是与狭义相对论的要求相一致的。
闵可夫斯基距离统一了「N维向量空间」中两点间的「Lp距离」,是大一统的理论框架。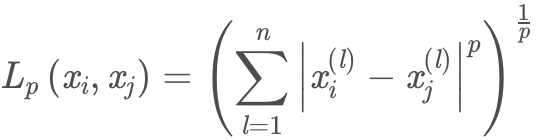
- 曼哈顿距离(Manhattan Distance)
当「p = 1」时「Lp距离」就为曼哈顿距离: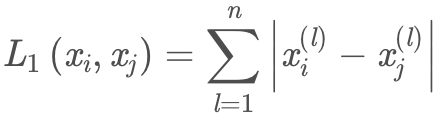
其图形如下,已原点为中心如同行走在曼哈顿大街上。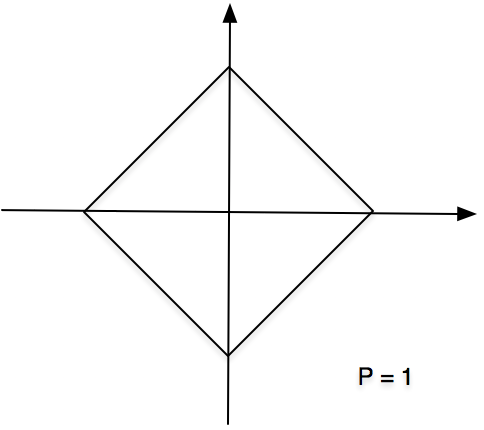
Show Me The Code
对于Java,已经有比较好的代码包支持:
double[][] x = new double[][] { { 10d, 20d }, { 15d, 20d }, { 5d, 20d }, { 1d, 15d } };double[][] y = new double[][] { { 1d, 15d }, { 5d, 20d }, { 15d, 20d }, { 10d, 20d } };ManhattanDistance ed = new ManhattanDistance();double distance = 0d;for (int i = 0; i < x.length; i++) {double[] x1 = x[i];double[] y1 = y[i];distance += ed.compute(x1, y1);}System.out.println(distance);
- 欧式距离(Euclidean Distance)
当「p = 2」时「Lp距离」就为欧式距离: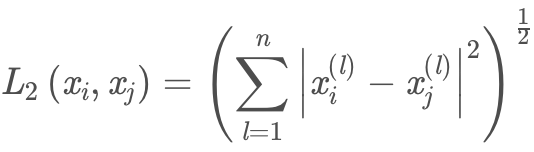
其图形如下,已原点为中心的一个圆。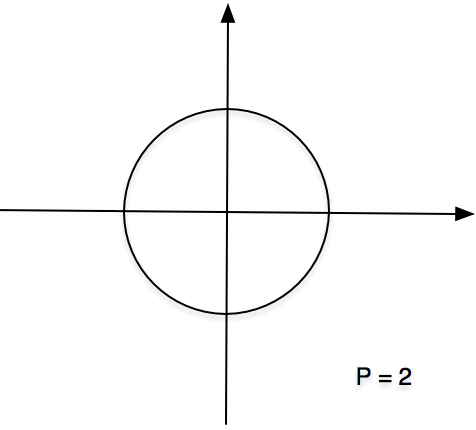
Show Me The Code
对于Java,同样有比较好的代码包支持:
double[][] x = new double[][] { { 10d, 20d }, { 15d, 20d }, { 5d, 20d }, { 1d, 15d } };
double[][] y = new double[][] { { 1d, 15d }, { 5d, 20d }, { 15d, 20d }, { 10d, 20d } };
EuclideanDistance ed = new EuclideanDistance();
double distance = 0d;
for (int i = 0; i < x.length; i++) {
double[] x1 = x[i];
double[] y1 = y[i];
distance += ed.compute(x1, y1);
}
System.out.println(distance);
- 切比雪夫距离(Chebyshev Distance)
当「p = ∞」时「Lp距离」就为切比雪夫距离: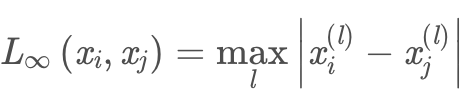
其图形如下,已原点为中心的正方体。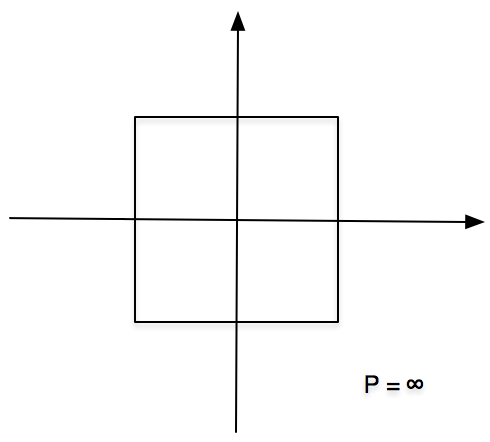
Show Me The Code
对于Java,同样有比较好的代码包支持:
double[][] x = new double[][] { { 10d, 20d }, { 15d, 20d }, { 5d, 20d }, { 1d, 15d } };
double[][] y = new double[][] { { 1d, 15d }, { 5d, 20d }, { 15d, 20d }, { 10d, 20d } };
ChebyshevDistance ed = new ChebyshevDistance();
double distance = 0d;
for (int i = 0; i < x.length; i++) {
double[] x1 = x[i];
double[] y1 = y[i];
distance += ed.compute(x1, y1);
}
System.out.println(distance);
- 马氏距离(Mahalanobis Distance)
表示数据的协方差距离,是有效计算「不同样本集」距离的方法。马氏距离「不受量纲影响」,两点之间距离与原始数据「测量单位无关」是由标准化数据和中心化数据(即协方差)计算表示「点与一个分布」之间的距离。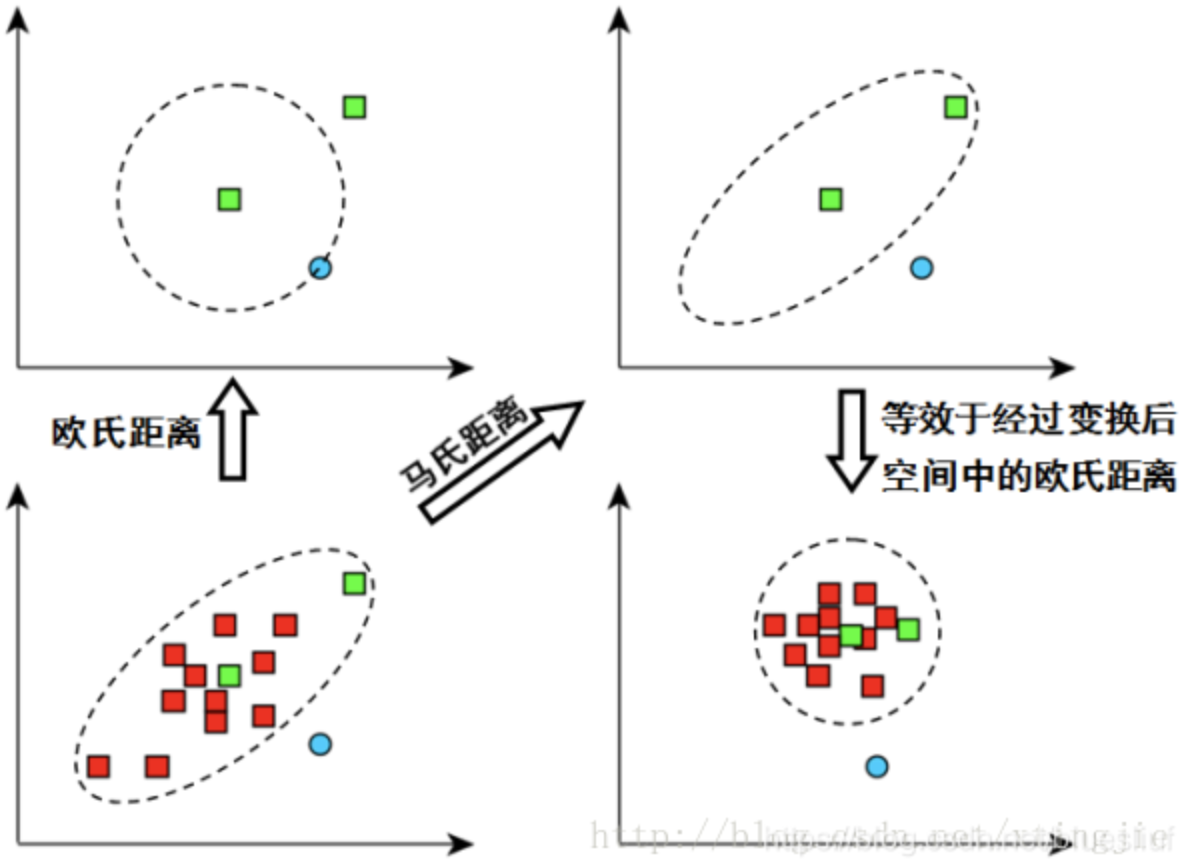
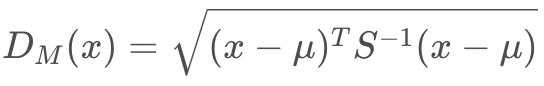
Show Me The Code
对于R,已经有比较好的代码包支持:
x=matrix(c(3,4,5,6,2,2,8,4),nrow=2)
# 原始矩阵
xmean=mean(x[1,])
# 4.5
ymean=mean(x[2,])
# 4
x[1,]=x[1,]-xmean
x[2,]=x[2,]-ymean
m=cov(t(x))
# 7 2 2.666667
m=solve(m)
q=matrix(c(3,4,5,6),nrow=2)
# 需要计算(3,4)和(5,6)
t=q[,1]-q[,2]
sqrt((t%*%m)%*%t(t(t)))
sqrt(mahalanobis(c(3,4),c(5,6),cov(t(x))))
# 需要计算(3,4)和(5,6), cov为协方差矩阵
文本距离
- 汉明距离(Hamming Distance)
摘自:「百度百科」
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念表示两个(相同长度)字对应位不同的数量,我们以d(x,y)表示两个字x,y之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
汉明距离理解为:对两个「等长」字符串而言,将其中一个字符串「逐字」替换为另一个字符串的「最小替换次数」。
Show Me The Code
对于Java,同样有比较好的代码包支持:
HammingDistance h = new HammingDistance();
System.out.println(h.apply("scale", "salty"));
- 莱温斯坦距离(Levenshtein Distance)
摘自:「百度百科」
莱文斯坦距离是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
以案例来解释汉明距离和莱温斯坦距离的区别:
| s | c | a | l | e |
|---|---|---|---|---|
| s | a | l | t | y |
图中灰色部分表示差别,所以汉明距离为「4」,而莱温斯坦距离则通过「插入和删除」得到距离为「3」。
| 0 | s | c | a | l | e |
|---|---|---|---|---|---|
| 1 | s | a | l | e | |
| 2 | s | a | l | t | |
| 3 | s | a | l | t | y |
Show Me The Code
对于Java,同样有比较好的代码包支持:
LevenshteinDistance l = new LevenshteinDistance();
System.out.println(l.apply("scale", "salty"));
- Jaccard距离(Jaccard Distance)
在协同过滤中有介绍(传送门),通过计算共有文本的占比来量化距离(相似度)。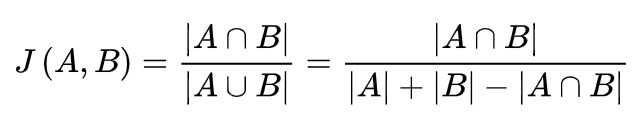
Show Me The Code
对于Java,同样有比较好的代码包支持:
JaccardDistance j = new JaccardDistance();
System.out.println(j.apply("scale", "salty"));
- 余弦距离(Cosine Distance)
在协同过滤中有介绍(传送门),当文本相似度的长度很大但内容相近时,使用词频作为特征计算余弦距离来量化文本距离(相似度)。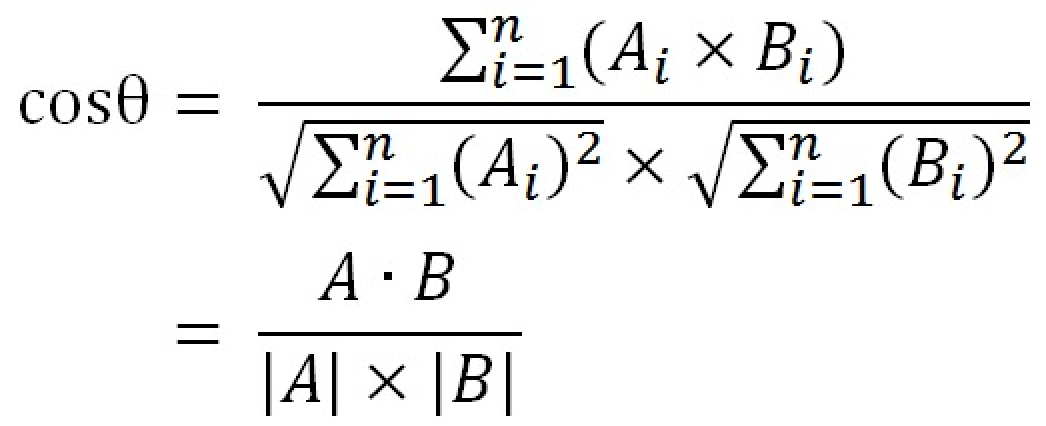
Show Me The Code
对于Java,同样有比较好的代码包支持:
CosineDistance c = new CosineDistance();
System.out.println(c.apply("scale", "salty"));
- JaroWinkler Distance
要了解JaroWinkler距离需要先从「Jaro相似度」开始:

- s1、s2:要对比的两个字符串长度
- m:匹配字符数量
- t:允许换位数目
- j:最后得分

- s1、s2:要比对的两个字符长度
- w:匹配窗口值
例如字符串「CRATE」和「TRACE」有「R、A、E」是匹配即「m = 3」。「C、T」虽然都出现在字符串中但通过「公式二」得出匹配窗口「 (5/2) - 1 = 1.5」。而「C、T」字符距离均「大于1.5」所以不算匹配,因此「t = 0」。
再回到以下案例来可知:
| s | c | a | l | e |
|---|---|---|---|---|
| s | a | l | t | y |


从「Jaro相似度」转换为「Jaro-Winkler相似度」:
- L:字符串「公共前缀」长度,最大值为「4」
- P:常量因子,对于有公共前缀分数会向上调整但不能超过「0.25」否则相似度会超过1,常量的默认值为「0.1」
那么再次计算Jw相似度可得:
可见Jaro-Winkler算法给予了起始部分就相同的字符串「更高分数」,常用于数据连接和重复记录方面的领域。
Show Me The Code
对于Java,同样有比较好的代码包支持:
JaroWinklerDistance w = new JaroWinklerDistance();
System.out.println(w.apply("scale", "salty"));

若有收获,就点个赞吧
0 人点赞
