支持向量机(Support Vector Machine,SVM),1995年Vapnik和Cortes(瓦普尼克和科尔特斯)欲找到具有“最大间隔”的决策边界,提出了强大的支持向量机(SVM)。主要思想是用一个分类超平面将样本分开从而达到分类效果,具有很强的理论论证和实验结果。它在解决小样本、非线性以及高维模式识别方面具有许多独特优势,并能推广应用到函数拟合等其他机器学习问题中。
SVM源自于统计学理论,基于VC维[1]理论和结构风险最小[2]原理,根据有限的样本信息在模型的复杂性(对特定学习样本的学习精度)和学习能力(即无错误识别样本能力)之间寻找最佳的折衷方案,以期望获得较好的推广能力(泛化能力)统计机器学习能够精确给出学习效果以及解答需要的样本量等一系列问题。
SVM的基本模型是二分类模型,属于有监督学习,是在空间当中寻找出一个超平面[2]作为分类的决策边界,对数据进行分类,且使每一类样本距离决策边界最近的样本到决策边界的距离尽可能的远,使分类误差最小化。
本章将会介绍不同SVM的核心概念、数学推理以及如何使用它们进行工作。
5.1 SVM的相关概念
5.1.1 最优分类超平面
在SVM中可以对数据集进行分类的超平面有非常多个,但是为了使分类超平面能达到最佳的分类效果。对未知样本的泛化能力最强,且有唯一解,这就需要寻找到最优分类超平面。最优分类超平面应该同时具备以下两个条件。
- 最近距离最远:在二分类样本中,每类都有距离超平面最近的样本,而最优超平面应该使这两类最近的样本到该超平面的距离尽可能远。
- 等距离:等距离是指离超平面最近的两类样本到该超平面的距离是相等的。
5.1.2 支持向量
支持是表示边界支撑的意思,二分类样本中分布距离最优分类超平面两侧最近的点且平行样最优分类超平面的训练样本(向量)就叫做支持向量,他们共同撑起了分类超平面,求解支持向量的算法被称为支持向量机。这里面“机”是代表了算法的意思。
[1]VC维:将N个点进行分类,如分成两类,那么可以有2N种分法,即可以理解成有2N个学习问题。若存在一个假设H,能准确无误地将2N种问题进行分类。那么这些点的数量N,就是H的VC维。 VC维度越高,表示函数集的复杂程度越高。也就是把经验风险降到最低,但却忽视了置信风险,结果导致结构风险也相应变高,容易产生过拟合(overfit)。
[2]置信风险: 分类器对 未知样本进行分类,得到的误差。经验风险: 训练好的分类器,对训练样本重新分类得到的误差。即样本误差。结构风险:置信风险 + 经验风险。结构风险最小化SRM(structured risk minimize)就是同时考虑经验风险与结构风险。在小样本情况下,取得比较好的分类效果。 保证分类精度(经验风险)的同时,降低学习机器的 VC 维,可以使学习机器在整个样本集上的期望风险得到控制,这应该就是SRM的原则。
当训练样本给定时,分类间隔越大,则对应的分类超平面集合的 VC 维就越小。(分类间隔的要求,对VC维的影响)
根据结构风险最小化原则,前者是保证经验风险(经验风险和期望风险依赖于学习机器函数族的选择)最小,而后者使分类间隔最大,导致 VC 维最小,实际上就是使推广性的界中的置信范围最小,从而达到使真实风险最小。
[3]在几何中,超平面(hyper plane)的本质是自由度比所在空间维度小1的子空间。自由度的概念可以简单理解为至少要给定多少个分量值才能确定一个点,在二维空间中超平面为一条直线,自由度为1;三维空间的超平面为一个二维平面,自由度为2;n维空间中超平面的自由度为n-1.5.2 SVM的分类
5.2.1 线性可分支持向量机
当训练样本线性可分时,通过硬间隔最大化学习一个线性分类器,即线性可分支持向量机(linear SVM in linearly separable case),这时SVM得到的最优超平面就是直线或者平面。图5-1所示的数据集来自第4章末尾引用的鸢尾花数据集的一部分。两个类可以轻松地被一条直线(它们是线性可分离的)分开。左图显示了三种可能的线性分类器的决策边界。其中虚线所代表的模型表现非常糟糕,甚至都无法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不会太好。相比之下,右图中的实线代表SVM分类器的决策边界,这条线不仅分离了两个类,并且尽可能远离了最近的训练实例。你可以将SVM分类器视为在类之间拟合可能的最宽的街道(平行的虚线所示)。因此也叫作硬间隔分类(hard margin maximization)。
请注意,在“街道以外”的地方增加更多训练实例不会对决策边界产生影响,也就是说它完全由位于街道边缘的实例所决定(或者称之为“支持”)。这些实例被称为支持向量(在图5-1中已圈出)。SVM对特征的缩放非常敏感,如图5-2所示,在左图中,垂直刻度比水平刻度大得多,因此可能的最宽的街道接近于水平。在特征缩放(例如使用Scikit-Learn的StandardScaler)后,决策边界看起来好了很多(见右图)。

5.2.2 线性支持向量机
如果我们严格地让所有实例都不在街道上,并且位于正确的一边,这就是硬间隔分类。硬间隔分类有两个主要问题。首先,它只在数据是线性可分离的时候才有效;其次,它对异常值非常敏感。图5-3显示了有一个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们在图5-1中所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。 
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持街道宽阔和限制间隔违例(即位于街道之上,甚至在错误的一边的实例)之间找到良好的平衡,也就是当训练数据近似可分的时候,引入松弛变量,通过软间隔最大化也训练一个学习器,这就是线性支持向量机(linear SVM)也叫做软间隔分类(soft margin maximization)。
使用Scikit-Learn创建SVM模型时,我们可以指定许多超参数。C是这些超参数之一。如果将其设置为较低的值,则最终得到图5-4左侧的模型。如果设置为较高的值,我们得到右边的模型。间隔冲突很糟糕,通常最好要少一些。但是,在这种情况下,左侧的模型存在很多间隔违例的情况,但泛化效果可能会更好。 与更少的间隔冲突(右)")
如果你的SVM模型在测试集表现的并不好出现了过拟合的情况,可以尝试通过降低C值来对其进行正则化。
以下Scikit-Learn代码可加载鸢尾花数据集,缩放特征,然后训练线性SVM模型(使用C=1的LinearSVC类和稍后描述的hinge损失函数)来检测维吉尼亚鸢尾花:
import numpy as npfrom sklearn import datasetsfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import LinearSVCiris = datasets.load_iris()X = iris["data"][:, (2, 3)] # petal length, petal widthy = (iris["target"] == 2).astype(np.float64) # Iris virginicasvm_clf = Pipeline([("scaler", StandardScaler()),("linear_svc", LinearSVC(C=1, loss="hinge", random_state=42)),])svm_clf.fit(X, y)
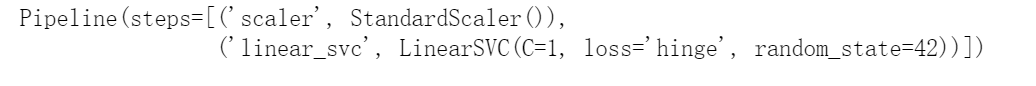
生成的模型如图5-4左图所示。 我们可以将SVC类与线性内核一起使用,而不使用LinearSVC类。创建SVC模型时,我们可以编写SVC(kernel=”linear”,C=1)。或者我们可以将SGDClassifier类与SGDClassifier(loss=”hinge”,alpha=1/(m*C))一起使用。这将使用常规的随机梯度下降(见第4章)来训练线性SVM分类器。它的收敛速度不如LinearSVC类,但是对处理在线分类任务或不适合内存的庞大数据集(核外训练)很有用。
LinearSVC类会对偏置项进行正则化,所以你需要先减去平均值,使训练集居中。如果使用StandardScaler会自动进行这一步。此外,请确保超参数loss设置为”hinge”,因为它不是默认值。最后,为了获得更好的性能,还应该将超参数dual设置为False,除非特征数量比训练实例还多(本章后文将会讨论)。
你可以像往常一样使用SVM模型分类器进行预测:
svm_clf.predict([[5.5, 1.7]])
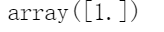
与Logistic逻辑回归分类器不同,SVM分类器不会输出每个类的概率。
5.2.3 非线性支持向量机
虽然在许多情况下,线性SVM分类器是有效的,并且通常出人意料的好,但是,有很多数据集远不是线性可分离的。处理非线性可分数据集的方法之一升维,升维就是把样本从源输入的低维空间想高维特征空间做映射,是的数据维度变大,升维可以解决低维空间中线性不可分的问题。如图5-5的左图:这是一个简单的数据集,只有一个特征x。可以看出,数据集线性不可分。但是如果将原来一维空间中的点通过升维映射到二维平面中(对应的图5-5的右图),将点x变为向量x’=[x,x2]T,生成的2D数据集则完全线性可分离。可以用 表示。
表示。
如图5-6中左图在二维空间中的点x1=(x1,y1)不能用一条直线来分类。分类的决策边界是一个椭圆(非线性),不能用 来表示,但是在点不变的前提下,将原数据转换到右图中的三维空间里,就可以使用一个线性超平面进行分割数据。分类超平面用
来表示,但是在点不变的前提下,将原数据转换到右图中的三维空间里,就可以使用一个线性超平面进行分割数据。分类超平面用 来表示,其中
来表示,其中 ,
, ,
,
(x1,y1)为原二维空间中点的坐标,r则是将(x1,y1)通过某种映射函数得到的。

Hinge损失函数 : 函数max(0,1-t)被称为hinge损失函数(如图所示)。当t≥1时,函数等于0。如果t<1,其导数(斜率)等于-1;如果t>1,则导数(斜率)为0;t=1时,函数不可导。但是,在t=0处可以使用任意次导数(即-1到0之间的任意值),你还是可以使用梯度下降,就跟Lasso回归一样。
5.3 核函数
- 对于低维空间中非线性可分的数据,可以将特征映射到高维空间(可以是无穷维)中,即升维,以达到在高维空间线性可分的目的,其中的关键是找到低维到高维的非线性映射函数f(x),和确定参数以及高维特征空间维数等。
- 非线性可分样例映射到高维空间后,需要计算高维空间中,数据向量化后的内积,计算量巨大而且困难,甚至会导致维数灾难,这些问题可以通过核函数来解决。
- 核函数是对低维数据的内积计算其结果与高维数据的内积运算结果相同,因此不需要再选取映射函数,用核函数运算的结果代替高维数据的内积,避免了直接在高维空间中进行复杂运算。
需要注意的是核函数与低维到高维的映射函数f(x)之间没有关系,核函数只是用来避免高维空间复杂运算的一种简便计算方法。
5.3.1 核函数的定义
若存在映射函数 可以将数据集
可以将数据集 映射到
映射到 ,即
,即 ,使得对于所有的x,y∈
,使得对于所有的x,y∈ ,函数
,函数 ,则称
,则称 为核函数,
为核函数, 为映射函数,
为映射函数, 为
为 与
与 的向量内积。
的向量内积。
5.3.2 核函数的特点
核函数的应用广泛和核函数的如下特点有关:
- 核函数是在原数据空间进行计算,避免了维数灾难,大大减小了计算量,可以有效处理高维输入。
- 无需知道映射函数
 的形式和参数。
的形式和参数。 - 核函数的形式和参数变化会改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变核函数方法的性能
- 核函数方法可以和不同的算法结合,形成多种不同的基于核函数的计算犯法,这两部分的设计可以单独进行,并可以为不同的应用选择不对核函数以及算法。
5.3.3 常用的几种核函数
线性核函数(linear kernel)
线性核函数(linear kernel)是最简单的核函数,对应的公式为 线性核函数可以直接用,主要用于数据线性可分的情况,不需要设置任何参数,数据也不需要做任何变换。
线性核函数可以直接用,主要用于数据线性可分的情况,不需要设置任何参数,数据也不需要做任何变换。
多项式核函数(Polynomial kernel function)
多项式核函数 (Polynomial kernel function)也是一种很常见的核函数,对应的公式5-1如下:
在公式5-1中有γ,d,c三个参数,其中γ表示对内积 进行放缩,γ>0,且一般等于1/类别数。c代表常数项,取值范围c≥0,当c>0时,称为非齐次多项式;c=0时,称为齐次多项式。d为整数,代表多项式的阶数,一般设d=2。升维时维度随着d增大而增大,计算量也随之增大,复杂性过高,容易出现过拟合。当参数d=1,γ=1,c=0时,K(x,y)为线性核函数。
进行放缩,γ>0,且一般等于1/类别数。c代表常数项,取值范围c≥0,当c>0时,称为非齐次多项式;c=0时,称为齐次多项式。d为整数,代表多项式的阶数,一般设d=2。升维时维度随着d增大而增大,计算量也随之增大,复杂性过高,容易出现过拟合。当参数d=1,γ=1,c=0时,K(x,y)为线性核函数。
让我们在卫星数据集上进行测试:这是一个用于二元分类的小数据集,其中数据点的形状为两个交织的半圆(见图5-7)。你可以使用make_moons()函数生成此数据集: ```python import matplotlib.pyplot as plt import numpy as np from sklearn.svm import SVC from sklearn.datasets import make_moons from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures
X, y = make_moons(n_samples=100, noise=0.15, random_state=42) polynomial_svm_clf = Pipeline([ (“poly_features”, PolynomialFeatures(degree=3)), (“scaler”, StandardScaler()), (“svm_clf”, LinearSVC(C=10, loss=”hinge”, random_state=42)) ])
polynomialsvm_clf.fit(X, y) def plot_predictions(clf, axes): x0s = np.linspace(axes[0], axes[1], 100) x1s = np.linspace(axes[2], axes[3], 100) x0, x1 = np.meshgrid(x0s, x1s) X = np.c[x0.ravel(), x1.ravel()] y_pred = clf.predict(X).reshape(x0.shape) y_decision = clf.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2) plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1)
plt.figure(dpi=600) plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5]) plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
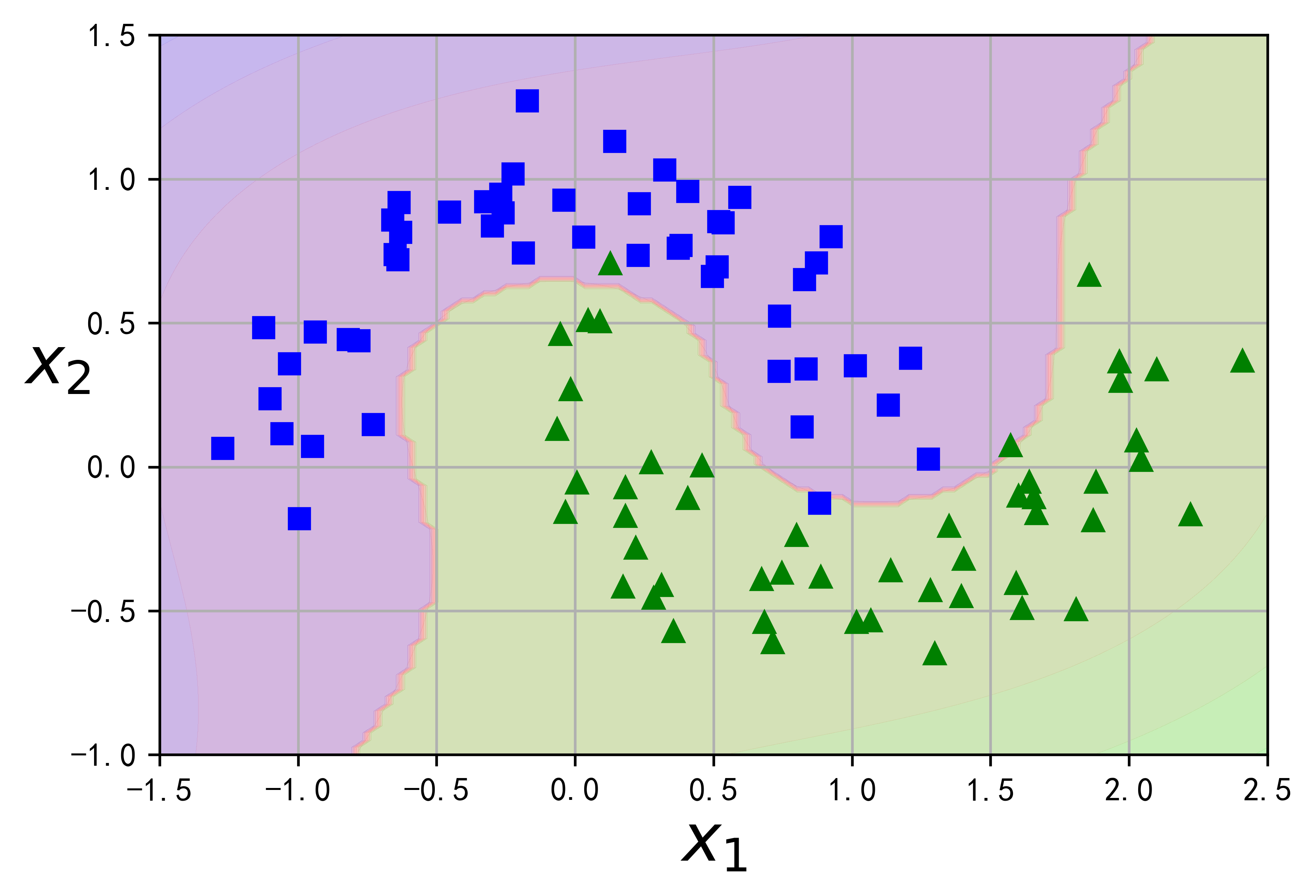<br />以下这段代码使用了一个3阶多项式内核训练SVM分类器。如图5-8的左图所示。而右图是另一个使用了10阶多项式核函数的SVM分类器。显然,如果模型过拟合,你应该降低多项式阶数;反过来,如果欠拟合,则可以尝试使之提升。超参数coef0控制的是模型受高阶多项式还是低阶多项式影响的程度。```pythonfrom sklearn.svm import SVCpoly_kernel_svm_clf = Pipeline([("scaler", StandardScaler()),("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))])poly_kernel_svm_clf.fit(X, y)
poly100_kernel_svm_clf = Pipeline([("scaler", StandardScaler()),("svm_clf", SVC(kernel="poly", degree=10, coef0=100, C=5))])poly100_kernel_svm_clf.fit(X, y)
fig, axes = plt.subplots(ncols=2, figsize=(16,4), dpi=600, sharey=True)plt.sca(axes[0])plot_predictions(poly_kernel_svm_clf, [-1.5, 2.45, -1, 1.5])plot_dataset(X, y, [-1.5, 2.4, -1, 1.5])plt.title(r"$d=3, r=1, C=5$", fontsize=18)plt.sca(axes[1])plot_predictions(poly100_kernel_svm_clf, [-1.5, 2.45, -1, 1.5])plot_dataset(X, y, [-1.5, 2.4, -1, 1.5])plt.title(r"$d=10, r=100, C=5$", fontsize=18)plt.ylabel("")plt.show()

寻找正确的超参数值的常用方法是网格搜索(见第2章)。先进行一次粗略的网格搜索,然后在最好的值附近展开一轮更精细的网格搜索,这样通常会快一些。多了解每个超参数实际上是用来做什么的,有助于你在超参数空间层正确搜索。
高斯径向基核函数(gaussian RBF kernel)
高斯径向基核函数是应用最广泛的一种核函数,对应的公式如下。
公式5-2:

其中σ>0称为核半径,是用户定义的用于确定到达率或者说函数值跌落到0的速度参数。如果x和y很接近,则核函数值为1,如果x和y相差很大,则核函数值约为0,通常γ= 1/n_features。这个函数类似于高斯分布,因此径向基核函数(Radial Basis Function kernel,RBF)也被称为高斯核函数(gaussian kernel),RBF是指数形式,通过泰勒展开式,展开后可以得到无穷多的多项式。所以RBF可以得到原始特征数据映射到无穷维后的计算结果。
运用高斯RBF核函数作为相似函数,通过对原始数据集添加相似特征的方法称为RBF核技巧,这些特征经过相似函数计算得出,相似函数可以测量每个实例与一个特定地标之间的相似度。以前面提到过的一维数据集为例,在x1=-2和x1=1处添加两个地标(见图5-9中的左图)。接下来,我们采用高斯径向基函数(RBF)作为相似函数,γ=0.3(见公式5-2)。现在我们准备计算新特征。例如,我们看实例x1=-1:它与第一个地标-2的距离为1,与第二个地标1的距离为2。因此它的新特征为x2=exp(-0.3×12)≈0.74,x3=exp(-0.3×22)≈0.30。图5-8的右图显示了转换后的数据集(去除了原始特征),现在你可以看出,数据呈线性可分离了。
与多项式特征方法一样,用RBF核技巧也可以用任意机器学习算法,但是要计算出所有附加特征,其计算代价可能非常昂贵,尤其是对大型训练集来说。然而,RBF核技巧再一次施展了它的SVM魔术:它能够产生的结果就跟添加了许多相似特征一样(但实际上也并不需要添加)。我们来使用SVC类试试高斯RBF核:
rbf_kernel_svm_clf = Pipeline([("scaler", StandardScaler()),("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))])rbf_kernel_svm_clf.fit(X, y)
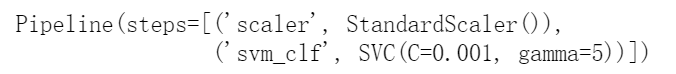
图5-10的左下方显示了这个模型。其他图显示了超参数gamma(γ)和C使用不同值时的模型。增加gamma值会使钟形曲线变得更窄(见图5-9的左图),因此每个实例的影响范围随之变小:决策边界变得更不规则,开始围着单个实例绕弯。反过来,减小gamma值使钟形曲线变得更宽,因而每个实例的影响范围增大,决策边界变得更平坦。所以γ就像是一个正则化的超参数:模型过拟合,就降低它的值,如果欠拟合则提升它的值(类似超参数C)。
其他核函数
下表列出了不经常使用的一些其他核函数。详细介绍请读者自行查阅资料。
表5-1:其他核函数类别(x,y表示输入空间的向量)
| 名称 | 表达式 | 参数 |
|---|---|---|
| ANOVA kernel | 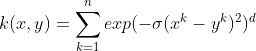 |
回归 |
| hyberbolic tangent (sigmoid)kernel |
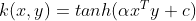 |
主要用于神经网络;正常 alpha=1/N,N是数据维度;alpha>0,c<0; 非正定核 |
| rational quadratic kernel | 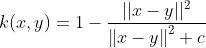 |
有理二次核的计算量比高斯核小,当使用高斯核代价太大时,它可以作为一种选择 |
| Multiquadric Kernel | 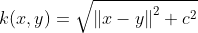 |
非正定核 |
| Inverse Multiquadric Kernel | 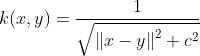 |
与高斯核一样,其结果是一个满秩的核矩阵,从而形成一个无限维的特征空间 |
| Circular Kernel | 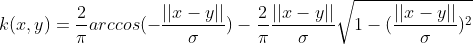 if 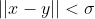 , zero otherwise , zero otherwise |
圆核用于地球静力学应用。它是一个各向同性固定核的例子,在R2中是正定的 |
| Spherical Kernel | 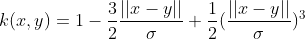 if 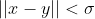 , zero otherwise , zero otherwise |
球核与圆核相似,但在R3中是正定的 |
| Power Kernel | 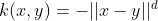 |
幂核也称为三角核。它是尺度不变核的一个例子,并且也是条件正定的。 |
| Log Kernel | 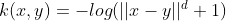 |
对于图像来说,Log内核似乎特别有趣,但它只是在一定条件下是正的 |
| Spline Kernel | 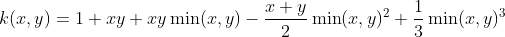 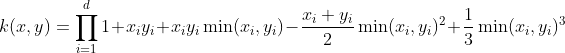 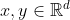 |
以分段三次多项式的形式给出 |

5.3.4 常用核函数的选择
选择核函数分为两个部分:一是确定核函数,二是确定核函数类型后相关参数的选择。根据具体的数据选择恰当的核函数是机器学习应用领域中一个重大难题。
在实际问题中,针对上述比较常用的几个核函数,选择的方法如下。
一、根据先验知识预先选定核函数,针对特征向量类型选用核函数。
线性核函数:主要用于线性可分的情况。参数少,速度快,对于一般数据,分类效果已经很理想了。适用于维度大,样本数量差不多的数据集。即训练集数据量不够支持训练一个复杂的非线性模型时。如果维数较少,样本数量很多,可以手动添加一些维数再使用。
多项式核函数:非常适合用于图像处理。可调节参数(可通过交叉验证或者枚举法)获得好效果。
高斯径向基核函数:主要用于非线性可分的情形,使用范围较广是SVM的默认核函数,适用于维数较低和样本数量中等如样本数1-1000的数据集。
高斯径向基核函数和多项式核函数都不擅长处理量纲不统一的数据集,在量纲不统一的情况下,可以用sklearn.preprocessing中的MinMaxScaler和StandardScaler进行标准化或者归一化处理。
二、采用交叉验证(Cross-Validation)方法,选择核函数时,分别试用不同的核函数,通过仿真试验,在同等条件之下对比分析,归纳误差比较小的核函数就是较好的一个。
三、采用混合核函数方法,其基本思想是将不同的核函数结合之后有更好的特性。该方法也是目前主流的方法。
表5-2:SVM中经常使用的核函数及其相关参数
| kernel输入 | 含义 | 解决问题 | 核函数表达式 | 参数gamma | 参数degree | 参数coef0 |
|---|---|---|---|---|---|---|
| “Linear” | 线性核函数 | 线性可分 | K(x,y)=x·y | 否 | 是 | 否 |
| “poly” | 多项式核 | 偏线性 | 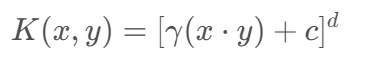 |
是 | 是 | 否 |
| “rbf” | 高斯径向基核 | 非线性 | 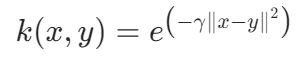 |
否 | 是 | 是 |
5.3.5 计算复杂度
liblinear库为线性SVM实现了一个优化算法,LinearSVC正是基于该库的。该算法不支持核技巧,不过它与训练实例的数量和特征数量几乎呈线性相关:其训练时间复杂度大致为O(m×n)。
如果你想要非常高的精度,算法需要的时间更长。它由容差超参数ε(在Scikit-Learn中为tol)来控制。大多数分类任务中,默认的容差就够了。
SVC则是基于libsvm库的,这个库的算法支持核技巧[2]。训练时间复杂度通常在 O(m2×n)和O(m3×n)之间。很不幸,这意味着如果训练实例的数量变大(例如成千上万的实例),它将会慢得可怕,所以这个算法完美适用于复杂但是中小型的训练集。但是,它还是可以良好地适应特征数量的增加,特别是应对稀疏特征(即每个实例仅有少量的非零特征)。在这种情况下,算法复杂度大致与实例的平均非零特征数成比例。表5-2比较了Scikit-Learn的SVM分类器类。
表5-3:用于SVM分类的Scikit-Learn类的比较
| 类 | 时间复杂度 | 核外支持 | 需要缩放 | 核技巧 |
|---|---|---|---|---|
| LinearSVC | O(mxn) | 否 | 是 | 否 |
| SGDClassifier | O(mxn) | 是 | 是 | 否 |
| SVC | O(m2xn) 到 O(m3xn) | 否 | 是 | 是 |
Mercer定理: 根据Mercer定理,如果函数K(a,b)符合几个数学条件——也就是Mercer条件(K必须是连续的,并且在其参数上对称,所以K(a,b)=K(b,a),等等),则存在函数φ将a和b映射到另一空间(可能是更高维度的空间),使得K(a,b)=φ(a)Tφ(b)。所以你可以将K用作核函数,因为你知道φ是存在的,即使你不知道它是什么。对于高斯RBF核函数,可以看出,φ实际上将每个训练实例映射到了一个无限维空间,幸好不用执行这个映射。注意,也有一些常用的核函数(如S型核函数)不符合Mercer条件的所有条件,但是它们在实践中通常也表现不错。
5.4 SVM回归
正如前面提到的,SVM算法非常全面:它不仅支持线性和非线性分类,而且还支持线性和非线性回归。诀窍在于将目标反转一下:不再尝试拟合两个类之间可能的最宽街道的同时限制间隔违例,SVM回归要做的是让尽可能多的实例位于街道上,同时限制间隔违例(也就是不在街道上的实例)。街道的宽度由超参数ε控制。图5-11显示了用随机线性数据训练的两个线性SVM回归模型,一个间隔较大(ε=1.5),另一个间隔较小(ε=0.5)。 
在间隔内添加更多的实例不会影响模型的预测,所以这个模型被称为ε不敏感。你可以使用Scikit-Learn的LinearSVR类来执行线性SVM回归。以下代码生成如图5-11所示的模型(训练数据需要先缩放并居中)。
from sklearn.svm import LinearSVRsvm_reg = LinearSVR(epsilon=1.5, random_state=42)svm_reg.fit(X, y)
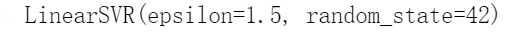
svm_reg1 = LinearSVR(epsilon=1.5, random_state=42)svm_reg2 = LinearSVR(epsilon=0.5, random_state=42)svm_reg1.fit(X, y)svm_reg2.fit(X, y)def find_support_vectors(svm_reg, X, y):y_pred = svm_reg.predict(X)off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)return np.argwhere(off_margin)svm_reg1.support_ = find_support_vectors(svm_reg1, X, y)svm_reg2.support_ = find_support_vectors(svm_reg2, X, y)eps_x1 = 1eps_y_pred = svm_reg1.predict([[eps_x1]])
def plot_svm_regression(svm_reg, X, y, axes):x1s = np.linspace(axes[0], axes[1], 100).reshape(100, 1)y_pred = svm_reg.predict(x1s)plt.plot(x1s, y_pred, "k-", linewidth=2, label=r"$\hat{y}$")plt.plot(x1s, y_pred + svm_reg.epsilon, "k--")plt.plot(x1s, y_pred - svm_reg.epsilon, "k--")plt.scatter(X[svm_reg.support_], y[svm_reg.support_], s=180, facecolors='#FFAAAA')plt.plot(X, y, "bo")plt.xlabel(r"$x_1$", fontsize=18)plt.legend(loc="upper left", fontsize=18)plt.axis(axes)fig, axes = plt.subplots(ncols=2, figsize=(9, 4), sharey=True)plt.sca(axes[0])plot_svm_regression(svm_reg1, X, y, [0, 2, 3, 11])plt.title(r"$\epsilon = {}$".format(svm_reg1.epsilon), fontsize=18)plt.ylabel(r"$y$", fontsize=18, rotation=0)#plt.plot([eps_x1, eps_x1], [eps_y_pred, eps_y_pred - svm_reg1.epsilon], "k-", linewidth=2)plt.annotate('', xy=(eps_x1, eps_y_pred), xycoords='data',xytext=(eps_x1, eps_y_pred - svm_reg1.epsilon),textcoords='data', arrowprops={'arrowstyle': '<->', 'linewidth': 1.5})plt.text(0.91, 5.6, r"$\epsilon$", fontsize=20)plt.sca(axes[1])plot_svm_regression(svm_reg2, X, y, [0, 2, 3, 11])plt.title(r"$\epsilon = {}$".format(svm_reg2.epsilon), fontsize=18)plt.show()
要解决非线性回归任务,可以使用核化的SVM模型。例如,图5-12显示了在一个随机二次训练集上使用二阶多项式核的SVM回归。左图几乎没有正则化(C值很大),右图则过度正则化(C值很小)。
以下代码使用Scikit-Learn的SVR类(支持核技巧)生成如图5-12所示的模型:
from sklearn.svm import SVRsvm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1, gamma="scale")svm_poly_reg.fit(X, y)
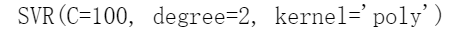
from sklearn.svm import SVRsvm_poly_reg1 = SVR(kernel="poly", degree=2, C=100, epsilon=0.1, gamma="scale")svm_poly_reg2 = SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1, gamma="scale")svm_poly_reg1.fit(X, y)svm_poly_reg2.fit(X, y)
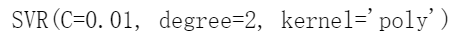
fig, axes = plt.subplots(ncols=2, figsize=(9, 4), sharey=True)plt.sca(axes[0])plot_svm_regression(svm_poly_reg1, X, y, [-1, 1, 0, 1])plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg1.degree, svm_poly_reg1.C, svm_poly_reg1.epsilon), fontsize=18)plt.ylabel(r"$y$", fontsize=18, rotation=0)plt.sca(axes[1])plot_svm_regression(svm_poly_reg2, X, y, [-1, 1, 0, 1])plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg2.degree, svm_poly_reg2.C, svm_poly_reg2.epsilon), fontsize=18)plt.show()
5.5 线性可分SVM的数学原理
当训练样本线性可分时,对应的SVM为线性可分SVM。SVM通过求支持向量到分类超平面的最大距离来确定最优分类超平面,这就转化为优化问题,SVM就是要解决这个最优化的问题。接下来我们以二维平面空间中线性可分的二分类问题为例,详细对整个求解过程进行数学推导和计算,本小节内容中涉及大量数学公式推导以及数学概念的引入,如果读者对其中的推导过程或数学概念不理解,则需要阅读参考本文涉及到的数学内容。
5.5.1 分类决策函数
假设有数据集为 ,其中
,其中 ,
, ,Xi为第i个特征向量,也称为实例。
,Xi为第i个特征向量,也称为实例。 ,yi为Xi的类标签。yi=1,则Xi为正例;yi=-1,则称Xi为负例。
,yi为Xi的类标签。yi=1,则Xi为正例;yi=-1,则称Xi为负例。
对于任意样本Xi,其相应的分类决策函数f(x)如下所示:
如果存在某个超平面H,其对应的数学公式如下:
能够将数据集中的正实例点和负实例点完全正确的划分到超平面的两侧。设X1和X2为H上面的两个点,对应的公式为 ,两个相减可得
,两个相减可得 。因为X1和X2是H上面的两个点,所以X1-X2必平行于H并垂直于w,可以得到w必垂直于超平面H,因此称w为超平面H的法向量。
。因为X1和X2是H上面的两个点,所以X1-X2必平行于H并垂直于w,可以得到w必垂直于超平面H,因此称w为超平面H的法向量。
为计算方便,我们设过支持向量并且平行于H的两条线表示如下:
将满足上面两个等式的平面称为间隔超平面。如图5-13所示,对于每一个训练样本xi,其分类标签yi满足:
因此可以将上述两个公式合并简写为 ,这个公式就是我们即将求解参数w和b时需要满足的约束条件。为简便书写接下来我们将
,这个公式就是我们即将求解参数w和b时需要满足的约束条件。为简便书写接下来我们将 统一记为
统一记为 。
。
5.5.2 分类间隔和最大间隔分类器
一般而言,一个点距离超平面的远近可以表示为分类预测的准确程度。在超平面 wx+b=0 确定的情况下,|wx+b|能够相对的表示点 x 到距离超平面的远近,而 wx+b 的符号与类标记 y 的符号是否一致表示分类是否正确,所以,可以用(y(wx+b))的正负性来判定或表示分类的正确性和确信度。
于此,我们便引出了定义样本到分类间隔距离的函数间隔 functional margin 的概念。
我们定义函数间隔:
只定义函数间隔还不够,如果成比例的改变 w 和 b,如将他们改变为 2w 和 2b,虽然此时超平面没有改变, 但函数间隔的值 f(x)却变成了原来的 2 倍,所以只有函数间隔还远远不够。还必须要给法向量w增加约束条件。这就是点到超平面的距离—几何间隔 geometrical margin 的概念。
介绍分类间隔之前我们先来回顾一下初中时学习的点到平面的距离公式。对于给定的平面 外一点
外一点 到该平面的距离为
到该平面的距离为
我们把超平面外一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w是垂直于超平面的一个法向量,把点x和超平面方程 带入到点到平面的距离公式,就可以得到样本 x 到分类超平面的几何间隔 (geometrical margin )
带入到点到平面的距离公式,就可以得到样本 x 到分类超平面的几何间隔 (geometrical margin )
综上,函数间隔 y(wx+b)=yf(x)实际上就是|f(x)|,只是人为定义的一个间隔度量;而几何间隔|f(x)|/||w||才是直观上的点到超平面距离,即分类间隔(margin)。
SVM的目标是求出最优分类超平面H,找到支持向量,对分类间隔进行最大化,将两类样本点正确分开,几何间隔越大的解,它的误差上界越小,分类的置信度(confidence)越大。因此最大化分类间隔就是我们追求的目标。
根据我们刚刚给出的分类间隔的定义,求最大化分类间隔即变为 ,请注意仅仅给出这个表达式是不够的,我们还必须要加上一个约束条件
,请注意仅仅给出这个表达式是不够的,我们还必须要加上一个约束条件 ,可能你会疑惑为什么要加入一个约束条件来求最大分类间隔呢?我们看看不加任何约束条件会是什么请看:因为
,可能你会疑惑为什么要加入一个约束条件来求最大分类间隔呢?我们看看不加任何约束条件会是什么请看:因为 单调,也就是
单调,也就是 无线趋近于0时,能得到分类间隔的最大值,而我们知道w是超平面H的法向量。模长为0意味着如图5-14所示的蓝色o和黄色+表示的两个支持向量到超平面的距离无限大,这样会导致样本点全部处于灰色区域,导致无法被正确分类,这种情况得到的最大分类距离也因此失去了意义。
无线趋近于0时,能得到分类间隔的最大值,而我们知道w是超平面H的法向量。模长为0意味着如图5-14所示的蓝色o和黄色+表示的两个支持向量到超平面的距离无限大,这样会导致样本点全部处于灰色区域,导致无法被正确分类,这种情况得到的最大分类距离也因此失去了意义。
出于方便推导和优化的目的,我们可以 (对目标函数的优化没有影响) 这样一来,我们的最大间隔分类器(maximum margin classifier)的目标函数可以定义为:
(对目标函数的优化没有影响) 这样一来,我们的最大间隔分类器(maximum margin classifier)的目标函数可以定义为:
这个公式当中的s.t.的意思为需要满足一定的约束条件即 。通过图5-14,我们可以看到两个实线支撑着中间的的超平面,到中间的虚线决策边界也就是分类超平面(separating hyper plane)的距离相等,即我们所能得到的最大的几何间隔(geometrical margin),w则是超平面的法向量方向。而“支撑”这两个超平面的必定会有一些点,而这些“支撑”的点便叫做支持向量( Support Vector)。
。通过图5-14,我们可以看到两个实线支撑着中间的的超平面,到中间的虚线决策边界也就是分类超平面(separating hyper plane)的距离相等,即我们所能得到的最大的几何间隔(geometrical margin),w则是超平面的法向量方向。而“支撑”这两个超平面的必定会有一些点,而这些“支撑”的点便叫做支持向量( Support Vector)。
换言之,Support Vector 便是下图中那些蓝色o和黄色*+在实线上的点:
5.5.3 从原始问题到对偶问题
我们已经有了最大间隔分类器的目标函数接下来,就是如何求 w 和 b 的问题了。根据我们之前得到的目标函数(subject to 导出的则是约束条件):
由于求 相当于求
相当于求 所以上述目标函数等价于:
所以上述目标函数等价于:
这样,我们的问题成为了一个凸优化问题,因为现在的目标函数是二次的,约束条件是线性的,所以它是一个凸二次规划问题。这个问题可以用任何现成的 QP (Quadratic Programming) 的优化包进行求解。一言以蔽之:在一定的约束条件下,目标最优,损失最小。
针对一个给定的约束优化问题,称之为原始问题,我们常常可以用另一个不同的,但是与之密切相关的问题来表达,这个问题我们称之为对偶问题。通常来说,对偶问题的解只能算是原始问题的解的下限,但是在某些情况下,它也可能跟原始问题的解完全相同。
幸运的是,SVM问题刚好就满足这些条件[1],所以你可以选择是解决原始问题还是对偶问题,二者解相同。
但由于这个问题的特殊结构,我们可以过拉格朗日对偶性(Lagrange Duality)变换到对偶变量 (dual variable) 的优化问题,即通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于: 一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
那什么是拉格朗日对偶性(Lagrange Duality)?简单地来说,通过给每一个约束条件加上一个 Lagrange multiplier(拉格朗日乘值),即引入拉格朗日乘子α[2],如此我们便可以通过拉格朗日函数将约束条件融合到目标函数里去。具体函数如下:
拉格朗日乘子法是通过引入拉格朗日乘子α,将原来的有约束条件优化问题,转化为无约束条件的方程组问题。拉格朗日乘子法的求解过程大致分为如下几个步骤: (1)原问题描述:求解函数z=f(x,y)在条件φ(x,y)=0下的极值 (2)构造函数:F(x,y,α)=f(x,y)+α·φ(x,y),其中α为拉格朗日乘子 (3)对构造函数求偏导列出方程组:
(4)求出x,y,α的值,带入即可得到目标函数极值。
接下来然后我们令 容易验证:
容易验证:
- 当某个约束条件不满足时,例如那么我们显然有
 (只要令
(只要令 即可)
即可) - 而当所有约束条件都满足时,则有

具体写出来,我们现在的目标函数变成了:
这里用P表示这个问题的最优值,且和我们最初的问题是等价的。如果直接求解,那么一上来便得面对 w 和 b 两个参数,而αi又是不等式约束,这个求解过程不好做。不妨把最小和最大的位置交换一下, 变成:
交换之后的新问题是交换之前问题的对偶问题,这个新问题的最优值用d表示。而且,我们有 ,在满足某些条件[3]的情况下,这两者等价,这个时候我们就可以通过求解第二个问题来间接地求解第一个问题。
,在满足某些条件[3]的情况下,这两者等价,这个时候我们就可以通过求解第二个问题来间接地求解第一个问题。
也就是说,下面我们可以先求 L 对 w、b 的极小,再求 L对α的极大。而且,之所以从 minmax 的原始问题P,转化为 maxmin 的对偶问题d。一者因为d是P的近似解,二者,转化为对偶问题后, 更容易求解。
[1]目标函数是凸函数,不等式约束是连续可微和凸函数。
[2]拉格朗日乘子法是通过引入拉格朗日乘子α,将原来的有约束条件优化问题,转化为无约束条件的方程组问题。
[3]这所谓的“满足某些条件”就是要满足KKT 条件,即要求 经过论证,我们这里的问题是满足 KKT 条件的,因此现在我们便转化为求解第二个问题。
经过论证,我们这里的问题是满足 KKT 条件的,因此现在我们便转化为求解第二个问题。
一般地,一个最优化数学模型能够表示成下列标准形式:
其中,f(x)是需要最小化的函数,h(x)是等式约束,g(x)是不等式约束,p 和 q 分别为等式约束和不等式约束的数量。同时,我们得明白以下两个定理: (1)凸优化的概念:
为一凸集,
为一凸函数。凸优化就是要找出一 点
使得每一个
满足
(2)KKT 条件的意义:它是一个非线性规划(Nonlinear Programming)问题能有最优化解法的充要条件 而 KKT 条件就是指上面最优化数学模型的标准形式中的最小点 x* 必须满足下面的条件:

5.5.4 对偶问题求解的三个步骤
固定α求L关于w,b的偏导
首先固定α ,要让 L 关于 w 和 b 最小化,分别对 w 和 b 求偏导数,再令偏导数等于0
将结果代入之前的 L,得到:
从而有:
从上面的最后一个式子,我们可以看出,此时的拉格朗日函数只包含了一个变量,那就是αi,然后
下文的第 2 步,求出了αi 便能求出 w 和 b,由此可见:分类函数 也就可以轻而易举的求出来了。
也就可以轻而易举的求出来了。
求对α的极大,即是关于对偶问题的最优化问题
经过上面第一个步骤的求 w 和 b,得到的拉格朗日函数式子已经没有了变量 w 和 b,只有α,从上面的式子得到:
αi与训练样本(xi,yi)相对应,即可利用SMO算法[3]求解对偶因子α。这样求得的α将能导出 w,b 的解,最终得出分离超平面和分类决策函数。
求出w和b
根据下面的式子即可求出w:
再选择一个αj>0对应的(xj,yj),因为 并且yi2=1,可以得到:
并且yi2=1,可以得到:
根据w和b的求解公式可知,w和b的值依赖对应于αi>0,即yif(x)的样本点,这些样本是支持向量。其他对于αi=0的样本点对w和b的值没有影响。
5.5.5 求得最优超平面和分类决策函数
把求得的w和b的最优解w*和b*,带入超平面H 后,即可求出最优分类超平面:
后,即可求出最优分类超平面:
分类决策函数为:
[3] SMO 算法是由 Microsoft Research 的 John C. Platt 在 1998 年发表的一篇论文
《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》中提出,它很快成为最快的二次规划优化算法,特别针对线性 SVM 和数据稀疏时性能更优。SMO 算法的基本思想是将 Vapnik 在 1982 年提出的 Chunking 方法推到极致,SMO 算法每次迭代只选出两个分量 ai和 aj进行调整,其它分量则保持固定不变,在得到解 ai和 aj之后,再用 ai和 aj改进其它分量。与通常的分解算法比较,尽管它可能需要更多的迭代次数,但每次迭代的计算量比较小,所以该算法表现出整理的快速收敛性,且不需要存储核矩阵,也没有矩阵运算。
SMO 序列最小优化算法是一种启发式的算法。它每次只优化两个变量,其他变量都视为常数。由于
,假设
固定,那么
的关系也就确定了。重复这个过程,直到达到某个终止条件程序退出并得到我们需要的最优解,这样SMO就将一个复杂的优化算法转化为一个两变量优化问题了。 SMO 的主要步骤如下: (1)选取一对 ai和 aj,选取方法使用启发式方法; (2)固定除 ai和 aj之外的其他参数,确定 W 极值条件下的 ai,由 aj表示 ai; (3)假定在某一次迭代中,需要更新对应的拉格朗日乘子; (4)先“扫描”所有乘子,把第一个违反 KKT 条件的作为更新对象,令为 a2; (5)在所有不违反 KKT 条件的乘子中,选择使|E1 −E2|最大的 a1(其中Ei=ui-yi而u=w·x-b。求出来的 E 代表函数 ui对输入 xi的预测值与真实输出类标记 yi之差); (6)每次更新完两个乘子的优化后,都需要再重新计算 b,及对应的 Ei值; 与此同时,乘子的选择务必遵循两个原则:
- 使乘子能满足 KKT 条件
- 对一个满足 KKT 条件的乘子进行更新,应能最大限度增大目标函数的值(类似于梯度下降)
至此,SVM的数学推导过程已经全部结束了,我相信到了这里再提到SVM 之后脑海里闪出的应该是一系列的相关公式的,最初分类函数,最大化分类间隔,max1/||w||,min(1/2||w||)2,凸二次规划,拉格朗日函数,转化为对偶问题,SMO 算法,都为寻找一个最优解,一个最优分类平面。一步步梳理下来,为什么要这样那样,太多东西 可以追究,最后实现。
之所以画大篇幅在SVM的数学推导过程当中,是因为SVM对于机器学习而言极为重要。在深度学习(2012年)出现之前,SVM 被认为机器学习中近十几年来最成功,表现最好的算法。
最后我们来通过以下代码看看SVM如何在三维空间中对鸢尾花数据集进行分类来结束本章的学习内容。
from sklearn import datasetsfrom sklearn.svm import LinearSVCsvm_clf2 = LinearSVC(C=100, loss="hinge", random_state=42)iris = datasets.load_iris()X = iris["data"][:, (2, 3)] # petal length, petal widthy = (iris["target"] == 2).astype(np.float64) # Iris virginica
from mpl_toolkits.mplot3d import Axes3Ddef plot_3D_decision_function(ax, w, b, x1_lim=[4, 6], x2_lim=[0.8, 2.8]):x1_in_bounds = (X[:, 0] > x1_lim[0]) & (X[:, 0] < x1_lim[1])X_crop = X[x1_in_bounds]y_crop = y[x1_in_bounds]x1s = np.linspace(x1_lim[0], x1_lim[1], 20)x2s = np.linspace(x2_lim[0], x2_lim[1], 20)x1, x2 = np.meshgrid(x1s, x2s)xs = np.c_[x1.ravel(), x2.ravel()]df = (xs.dot(w) + b).reshape(x1.shape)m = 1 / np.linalg.norm(w)boundary_x2s = -x1s*(w[0]/w[1])-b/w[1]margin_x2s_1 = -x1s*(w[0]/w[1])-(b-1)/w[1]margin_x2s_2 = -x1s*(w[0]/w[1])-(b+1)/w[1]ax.plot_surface(x1s, x2, np.zeros_like(x1),color="b", alpha=0.2, cstride=100, rstride=100)ax.plot(x1s, boundary_x2s, 0, "k-", linewidth=2, label=r"$\mathbf{w}^{T}x+b=0 $")ax.plot(x1s, margin_x2s_1, 0, "k--", linewidth=2, label=r"$\mathbf{w}^{T}x+b=\pm 1$")ax.plot(x1s, margin_x2s_2, 0, "k--", linewidth=2)ax.plot(X_crop[:, 0][y_crop==1], X_crop[:, 1][y_crop==1], 0, "g^")ax.plot_wireframe(x1, x2, df, alpha=0.3, color="k")ax.plot(X_crop[:, 0][y_crop==0], X_crop[:, 1][y_crop==0], 0, "bs")ax.axis(x1_lim + x2_lim)ax.text(4.5, 2.5, 3.8, "分类超平面h", fontsize=16)ax.set_xlabel(r"花瓣长度", fontsize=12, labelpad=10)ax.set_ylabel(r"花瓣宽度", fontsize=12, labelpad=10)ax.set_zlabel(r"$h = \mathbf{w}^T \mathbf{x} + b$", fontsize=16, labelpad=5)ax.legend(loc="upper left", fontsize=8)fig = plt.figure(dpi=600)ax1 = fig.add_subplot(111, projection='3d')plot_3D_decision_function(ax1, w=svm_clf2.coef_[0], b=svm_clf2.intercept_[0])plt.show()
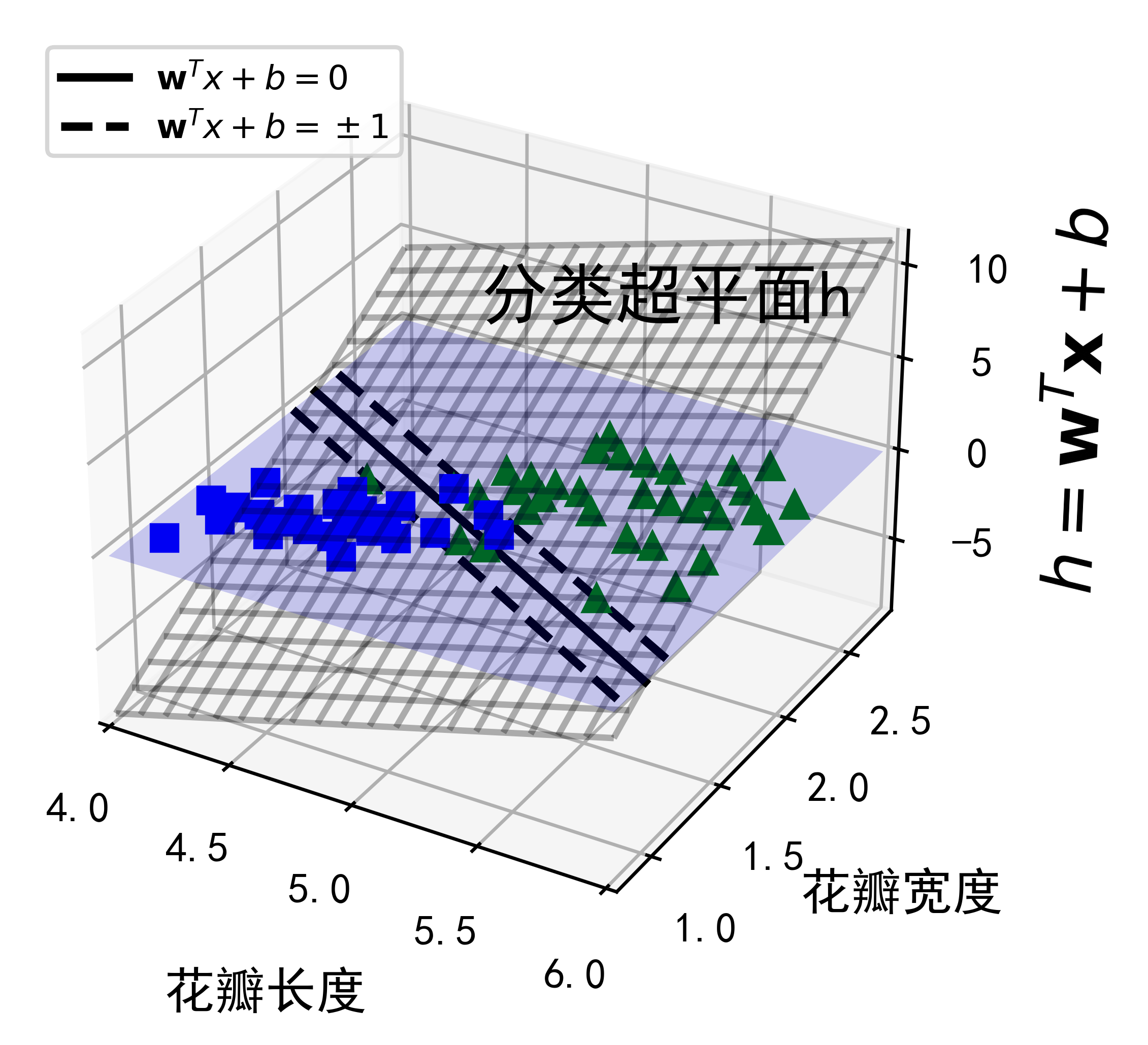
5.6 练习题
1.支持向量机的基本思想是什么?
2.什么是支持向量?
3.使用SVM时,对输入值进行缩放为什么重要?
4.SVM分类器在对实例进行分类时,会输出信心分数吗?概率呢?
5.如果训练集有成百万个实例和几百个特征,你应该使用SVM原始问题还是对偶问题来训练模型?
6.假设你用RBF核训练了一个SVM分类器,看起来似乎对训练集欠拟合,你应该提升还是降低γ(gamma)?C呢?
7.如果使用现成二次规划求解器,你应该如何设置QP参数(H、f、A和b)来解决软间隔线性SVM分类器问题?
8.在一个线性可分离数据集上训练LinearSVC。然后在同一数据集上训练SVC和SGDClassifier。看看你是否可以用它们产生大致相同的模型。
9.在MNIST数据集上训练SVM分类器。由于SVM分类器是个二元分类器,所以你需要使用一对多来为10个数字进行分类。你可能还需要使用小型验证集来调整超参数以加快进度。最后看看达到的准确率是多少?
10.在加州住房数据集上训练一个SVM回归模型。

若有收获,就点个赞吧
0 人点赞
