2.0 集合
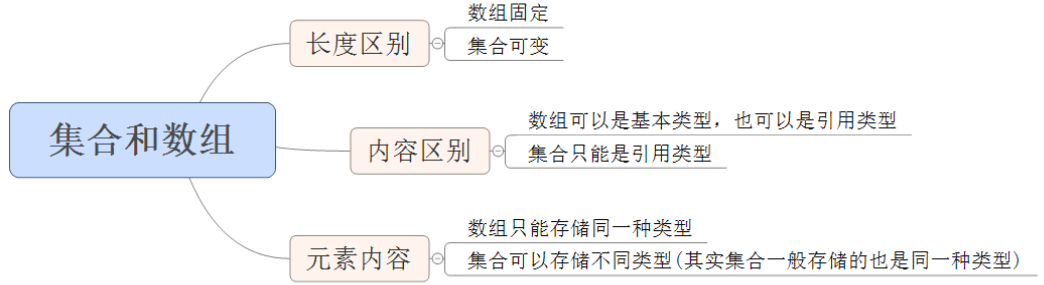
2.0.1 集合和数组的区别
2.0.2 常用集合分类

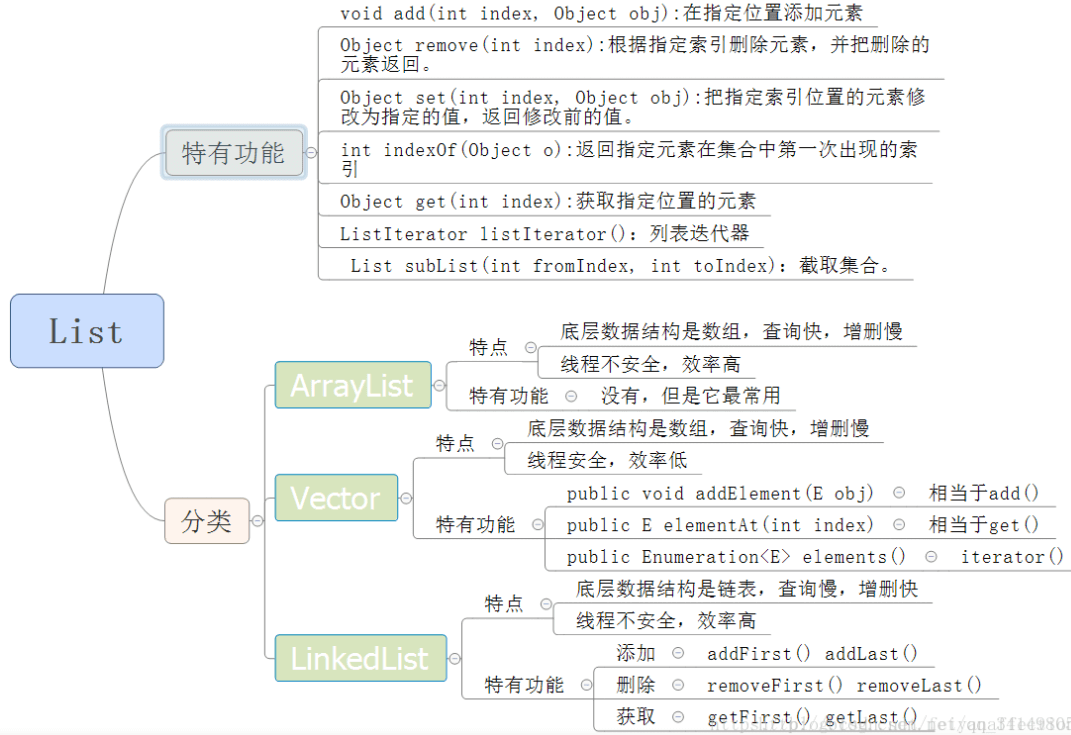
2.0.3 Collection集合的方法
2.0.4 Set
HashSet实现
HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
具体实现唯一性的比较过程:存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
LinkedHashSet
底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
TreeSet
底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。
根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造)
自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;
比较器排序要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
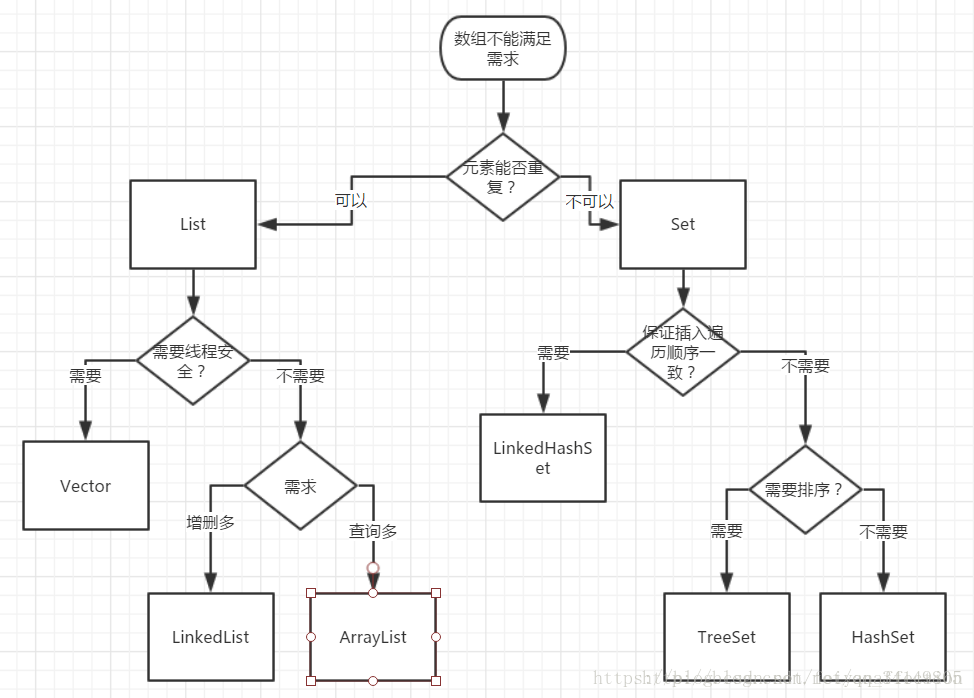
2.0.5 Map中几个接口的比较
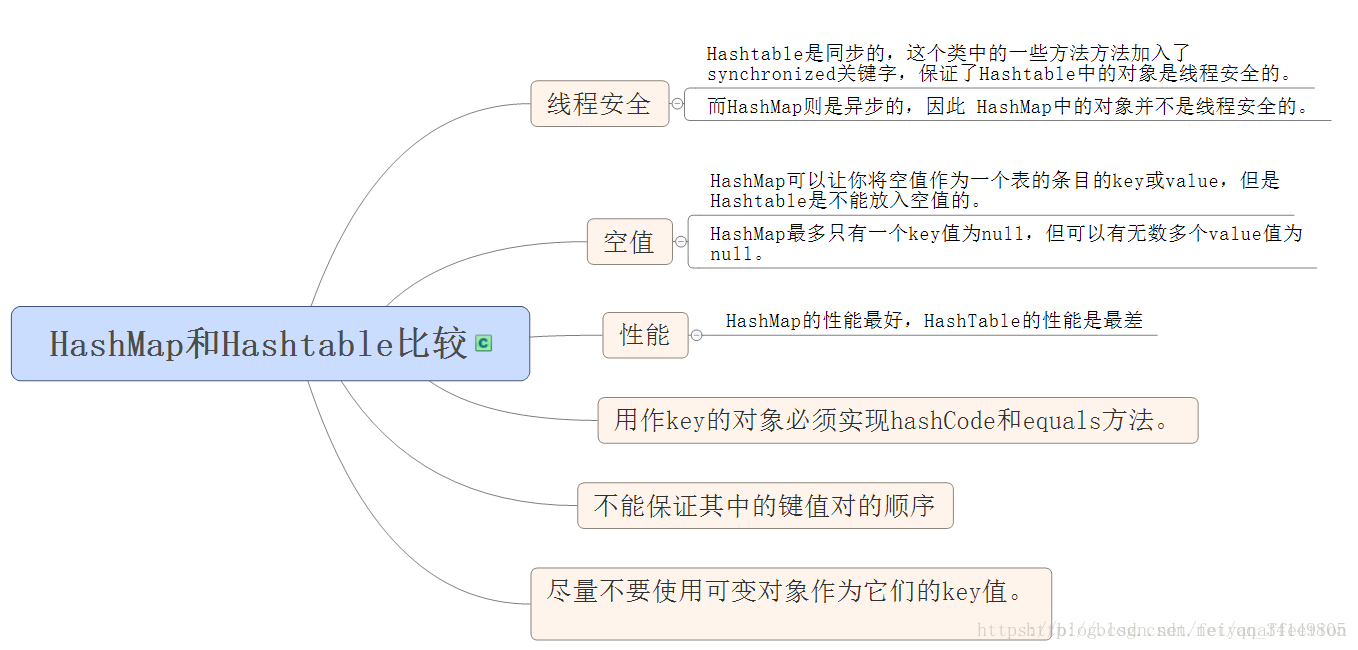


HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
5.线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
2.1 List Set Map的区别
List
有序可重复
有序,按对象进入的顺序保存对象,可重复,允许多个Null元素对象
可以使用Iterator取出所有元素,再逐一遍历
还可以使用get(int index)获取指定下标元素——可以随机访问
Set
无序、不可重复
最多允许一个Null元素对象
取元素时只能用Iterator接口或者foreach取得所有元素,再逐一遍历各个元素
Map
键值对,key无序不可重复,最多映射一个,value无序可重复
2.2 ArrayList和LinkedList的区别
都不同步,线程不安全
ArrayList:
基于动态数组,连续内存存储,适合下标访问(随机访问)
扩容机制:数组长度固定,超出长度存数据就要新建数组,然后将老数组的数据拷贝到新数组
使用尾插法并指定初始容量可以极大提升性能,甚至超过LinkedList(需要创建大量的node对象)
LinkedList:
基于双向链表(6.0之前为循环链表,7.0取消循环),分散存储,适合数据插入和删除,不适合查询
遍历必须使用iterator不能用for循环,因为for体内每次都get(i)取得某一元素时都要重新对list遍历,性能消耗极大
remove 快速失败机制
另外,也不要试图使用IndexOf返回元素索引再利用其遍历。因为使用IndexOf对list遍历,当结果为空时会遍历整个列表,性能太低
插入、删除的时间复杂度:O(N) vs O(1)
快速随机访问(元素序号获取) RandomAccess接口(标识) vs 遍历
内存空间占用:结尾预留 vs 每个元素消耗更多空间(node对象保存直接前驱、后驱、数据)
ArrayList和Vector的区别
ArrayList:List的主要实现类,适用于频繁查找,线程不安全
Vector:List的古老实现类,线程安全
2.3 ArrayList的扩容机制 重要
ArrayList实现了List接口,它是一个可调整大小的数组可以用来存放各种形式的数据。并提供了包括CRUD在内的多种方法,可以对数据进行操作。但是它不是线程安全的,此外ArrayList按照插入的顺序来存放数据。
主要成员变量:
//数组默认初始容量private static final int DEFAULT_CAPACITY = 10;//空数组 以供其他需要用到空数组的地方调用private static final Object[] EMPTY_ELEMENTDATA = {};//空数组 这个空数组是用来判断ArrayList第一添加数据的时候要扩容多少。默认构造器返回这个空数组private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};//数据存的地方 它的容量就是这个数组的长度 同时只要是使用默认构造器(DEFAULTCAPACITY_EMPTY_ELEMENTDATA )第一次添加数据的时候容量扩容为DEFAULT_CAPACITY = 10transient Object[] elementData;//当前数组的长度private int size;
三种构造方法:
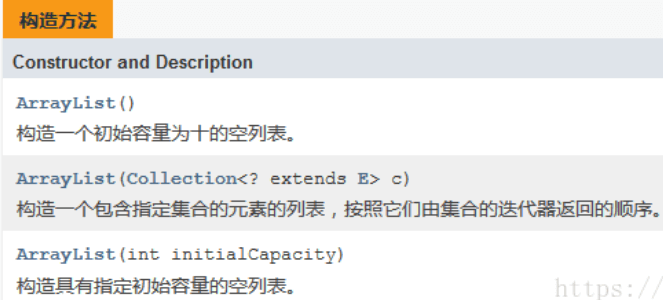
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}public ArrayList(Collection<? extends E> c) {elementData = c.toArray();if ((size = elementData.length) != 0) {// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);} else {// replace with empty array.this.elementData = EMPTY_ELEMENTDATA;}}public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}
扩容机制
核心方法:
ensureCapacityInternal(确认内部容量)
ensureExplicitCapacity(判断是否扩容)
grow(扩容)
int newCapacity = oldCapacity + (oldCapacity >> 1); // jdk1.7及以后 旧+旧右移1位(右移=/2) 得到1.5倍扩容int newCapacity = (oldCapacity * 3)/2 + 1; // jdk1.6及以前 乘1.5+1
三种情况:
1. 当前数组由默认构造方法生成的空数组,初始容量为0
第一次调用add/addAll方法添加数据后才真正分配容量为10
此时,minCapacity=默认容量(10)
添加数据,判断数组长度是否已达最大容量,若达到,则扩容
数组容量 0->10->1.5倍扩容
2. 由自定义初始容量构造方法创建且指定初始容量不为0。
此时,minCapacity=自定义初始容量
0->自定义初始容量->1.5倍
注意:若指定初始容量为0,则minCapacity=1,
其数组容量0->1->2->3->4->1.5倍扩容,即前4次添加数据都只+1。
3. 扩容量(newCapacity)大于ArrayList定义的最大值后(2^31-9),会调用hugeCapacity进行判断。
选择题:
ArrayList list = new ArrayList(20);中的list扩充几次?
答:
指定数组大小的创建,直接分配其大小,扩容0次。
2.4 HashMap和HashTable的区别
| HashMap | HashTable | |
|---|---|---|
| 线程安全 | 非 | 是,每个方法都加synchronized修饰 |
| 效率 | 高一点,但是被淘汰了 | |
| 对Null Key和Null Value的支持 | 可以有一个Null Key, 多个Null Value |
不允许Null Key和Value 会抛出NullPointException |
| 初始容量、每次扩容的大小 | 1.默认16,每次扩容成2倍 2.给定初始值,扩充为2的幂次方(通过tableSizeFor()方法) |
默认11,每次扩容为2n+1 |
| 底层数据结构 | 数组+链表+红黑树 | |
| 父类 | AbstractMap | Dictionary(淘汰了) |
| 接口 | containsValue判断是否包含传入的value值 | 多了elements返回hashtable中的value枚举、contains与 containsValue功能一样,花销更大 |
| 迭代方式不同 | Iterator(多了删除) | Enumeration |
| hash值计算方法不同 | 固定哈希表大小为2的幂次 | 直接使用对象的hashCode |
都实现了map、Cloneable、Serializable接口
hashCode是JDK根据对象地址或字符串或数字算出的int类型数值,然后使用除留余数法获得位置。
hashMap使用位运算代替了除法,提高了效率但是hash冲突增加(hash值的低位相同概率比较高),为了解决这个问题,HashMap重新计算hash值,使取得的位置更分散(还是简单的位运算)
2.5 HashMap的底层实现 重要
拉链法
将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
链表高度到8,数组长度超过64,转红黑树,元素以内部类Node节点存在。
扰动函数
HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 目的:减少哈希碰撞。
2.5.0 hashmap为什么用红黑二叉树,而不用B+树?
B+树查询效率好于红黑二叉树,但是B+树比B树更加“矮胖”,非叶子节点不存储数据,所以每个节点能存储的关键字更多。所以B+树能应对大量数据的情况。
如果用B+树,数据量不多的情况下,数据会都挤在一个节点里。这时候遍历效率就退化成了链表。
2.5.1 底层put方法的流程
1. 先判断散列表是否没有初始化或者为空,如果是就扩容2. 根据键值 key 的hashCode 计算 经过扰动函数处理过的 hash 值,通过 (length-1) & hash 得到要插入的数组索引3. 判断要插入的那个数组是否为空:1. 如果为空直接插入。2. 如果不为空,判断 key 的值是否是重复(用 equals 方法):1. 如果是就直接覆盖2. 如果不重复就再判断此节点是否已经是红黑树节点:1. 如果是红黑树节点就把新增节点放入树中2. 如果不是,就开始遍历链表:1. 到底部之前发现有重复的值,覆盖2. 循环判断直到链表最底部,到达底部就插入节点,然后判断是否链表长度是否大于8:1. 如果大于8 且 当前数组长度大于等于64 就转换为红黑树2. 如果大于8 但 当前数组长度小于64 先数组扩容3. 如果不大于8就继续下一步4. 判断是否需要扩容,如果需要就扩容。(不重要:数组长度低于6则将红黑树转会链表)
注意:JDK1.7之前的put是采用头插法插入元素,导致在并发下rehash会形成循环链表。JDK尾插法解决了这一问题。
put示意图:
2.5.2 底层扩容流程
最初未给定初始值,默认16,每次扩容成2倍。
给定初始值,扩充为2的幂次方(通过tableSizeFor()方法)。
默认负载因子0.75,扩容机制的阈值,当达到容量的0.75倍时就扩容。
扩容会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。
// 原索引,给低位链表赋值if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}// 原索引+oldCap,给高位链表赋值else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}
扩容后元素移动(索引变化):在扩容时看原hash值新增的那个bit位是1还是0就好了,是0的话索引没有变,是1的话索引变成“原索引+oldCap(旧数组大小)”。
扩容示意图: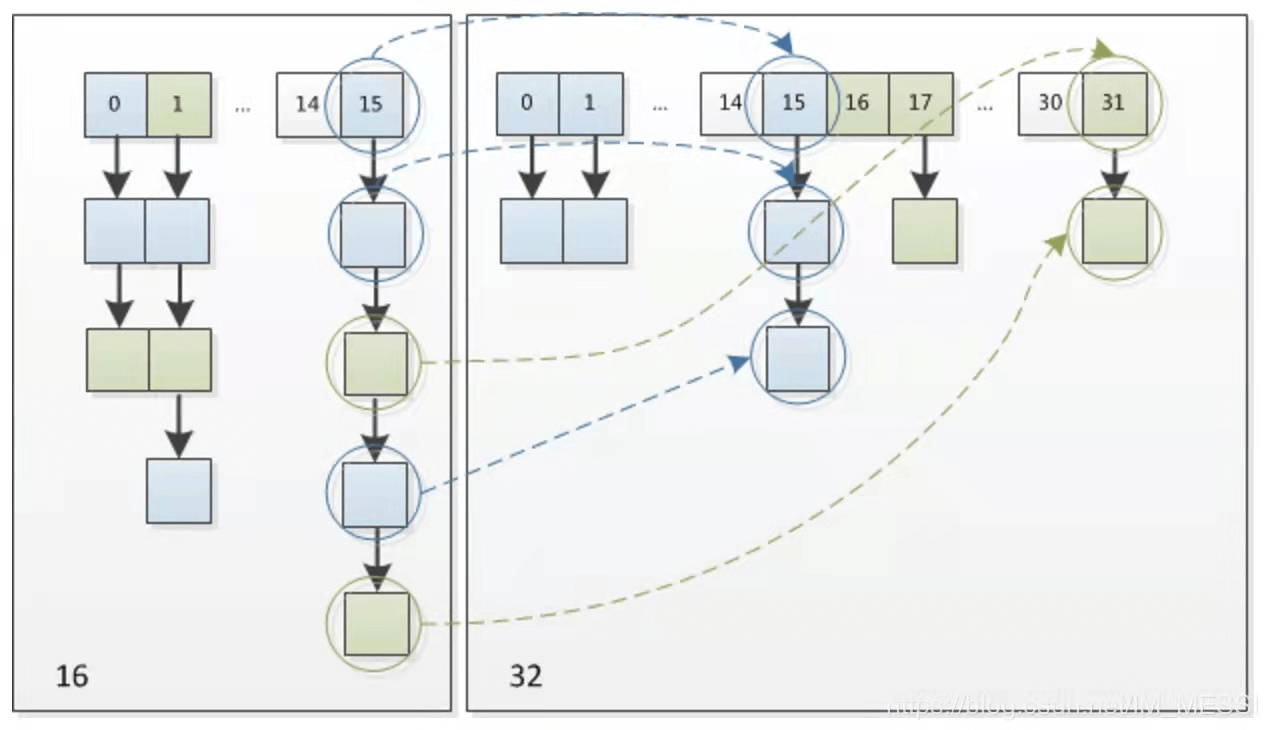
TreeMap、TreeSet及HashMap都使用红黑树,解决二叉查找树的缺陷——某些情况下会退化成线性结构
2.5.3 HashMap长度为什么是2的幂次方
为了减少哈希碰撞,要尽量把数据分配均匀。
虽然Hash值范围很大,但是直接把40亿长度的数组存在内存中存不下,所以需要对数组长度取模运算,得到的余数作为对应下标。即:hash % length。
而采用二进制位操作 & 比 % 提高运算效率,所以实际使用的取余计算方法是 (length-1) & hash 。
hash % length == (length-1) & hash 成立的前提就是 length是2的n次方。
length是2的n次方,则length-1是111111…111的形式,这样可以分散,减少哈希碰撞。
2.5.4 HashMap负载因子为什么是0.75
负载因子是扩容机制的阈值。HashMap作为一种数据结构,需要节省空间和时间,考虑两种极端情况:
1.负载因子是1.0
即数组全部填充满了才扩容,这样哈希冲突避免不了。大量的哈希冲突使底层的红黑树变得复杂,查询效率大大降低。
这种情况牺牲了时间换取了空间的利用率。
1.负载因子是0.5
数组元素达到一半就扩容,填充少了哈希冲突也少了,底层链表长度和红黑树高度也减少,查询效率提高。
但是空间利用率大大降低,内存翻倍。
所以权衡时间和空间,取中间数0.75。
同时,这也是泊松分布计算的结果,当用0.75作为加载因子时,桶中元素达到8的概率非常小,因此每个位置的链表长度超过8几乎不可能,所以在链表节点达到8时才转为红黑树。
注意:负载因子=0.75决定了链表长度到8转为红黑树
2.5.5 HashMap为什么是线程不安全的?
https://mp.weixin.qq.com/s/P_KTvzZohFG4DwUVl7nQ7A
HashMap线程不安全体现在会造成死循环、数据丢失、数据覆盖等问题。
其中,JDK1.8解决了死循环和数据丢失问题,仍存在数据覆盖问题。
HashMap的线程不安全发生在扩容函数中,根源在transfer函数(rehash过程)中,JDK1.7及之前,扩容操作重新定位每个桶的下标,并采用头插法将元素迁移到新数组。头插法会将链表顺序翻转,形成死循环和数据丢失。
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length; // 新数组容量for (Entry<K,V> e : table) { // 老的数组元素获取while(null != e) {Entry<K,V> next = e.next; // 把下一节点暂时存为 nextif (rehash) { //是否rehashe.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity); // 新的数组下标e.next = newTable[i]; // e的next指向数组的新下标内的节点// A挂起newTable[i] = e; // 数组新下标位置存入ee = next;}}}
JDK1.7 HashMap扩容造成死循环和数据丢失的分析过程
1.假设两个线程A、B对以下hashmap扩容(左),正常扩容应该得到右 ,
,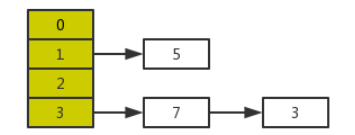
假设原先数组同一位置处的链表是3->7->5
jdk1.7采用头插法,扩容重新计算数组坐标进行数据迁移:
e指向3,e.next用一个指针next指着,即next指向7
计算3的新坐标,3的next指向数组新坐标中的节点,即3.next=null
将3这个节点存入新坐标位置处
e指向next所指的数7,对7进行重新计算数组坐标
…
7算出来的坐标如果也是3一样的坐标,则7.next指向3(即 头插法)
…
5算出来的新坐标是另一个坐标,则得到结果 5, 7 -> 3
多线程时出现循环问题:
当A线程在做完3的next指向新坐标中的节点后,CPU时间片耗尽,挂起。
此时 e = 3, next = 7,e.next = null
另一个线程B执行,并转移了两个节点,即同一位置7->3
此时,主内存中7.next = 3,3.next = null
A又重新开始执行,将3存入新坐标的位置,e指向7,进入新循环
然后从主存中读取发现7.next指向3,于是next指向3
在下一轮循环后,next为空,3又指向7
跳出循环
发现:死循环,数据5丢失
JDK1.8弃用了transfer函数,直接在resize中完成数据迁移,且采用的尾插法,避免了上述两个问题
但是JDK1.8仍会出现数据覆盖问题
假设A、B两个线程都在进行put操作,在hash函数计算完下标是相同后,A判断完下标处为空后,时间片耗尽,挂起。
B得到时间片,在此处插了元素。此时A继续执行,由于此前已经判断过,此处不再判断,直接插入,导致数据覆盖了B插入的数据。
2.5.6 HashMap 尾插法怎么解决的死循环?
2.5.7 HashMap为什么小于6转链表,大于8转红黑树?
红黑树的平均查找时间复杂度为logN
链表的平均查找时间复杂度是N/2 ((1+N)/ 2 )
长度为8时红黑树平均查找时间复杂度时3,而链表是4,有转成树的必要
长度小于6时,链表速度快,且红黑树转化还需时间
中间有个差值7,防止链表和树之间频繁转换
2.6 ConcurrentHashMap底层实现线程安全的方式
https://zhuanlan.zhihu.com/p/31614308
JDK1.7:ReentrantLock+Segment+HashEntry。 分段锁 一个Segment包含一个HashEntry数组,一个HashEntry又是一个链表结构(就是跟HashMap底层一样的)
锁:Segment分段锁,继承了ReentrantLock,锁定操作的Segment,其他不受影响,并发度 = Segment的个数,可用构造函数指定,扩容不影响其他Segment
(分段锁对桶数组进行分割分段(segment),每把锁只锁容器中的一部分数据,多线策访问不同数据段的数据,不会存在锁竞争,提高并发访问率。)
元素查询:二次hash,第一次定位到Segment,第二次定位到元素所在链表头部
get方法无需加锁,volatile保证
JDK1.8:synchronized+CAS+数组+链表/红黑树。Node中val、next都使用了volatile修饰,保证了可见性。
(CAS是乐观锁,查找、替换、赋值操作都使用CAS,效率更高)
链表超过一定阈值的时候(8)转为红黑树(时间复杂度从ON变成OlogN)。
锁:synchronized只锁定当前链表或红黑二叉树的head节点,不影响其他元素读写,锁粒度更细,效率更高,扩容时阻塞所有的独写操作、并发扩容。
读操作无锁:
Node中val、next都使用了volatile修饰,读写线程对改变量互相可见 这样保证不会读到脏数据
数组用volatile修饰,保证扩容时被读线程感知
HashTable是全表锁,一个线程访问同步方法,其他方法也要访问同步方法时,会进入阻塞或轮询,竞争激烈效率低下。
JDK1.7的方法解决了并发问题,但是查询遍历链表效率太低。
1.8的ConcurrentHashMap示意图: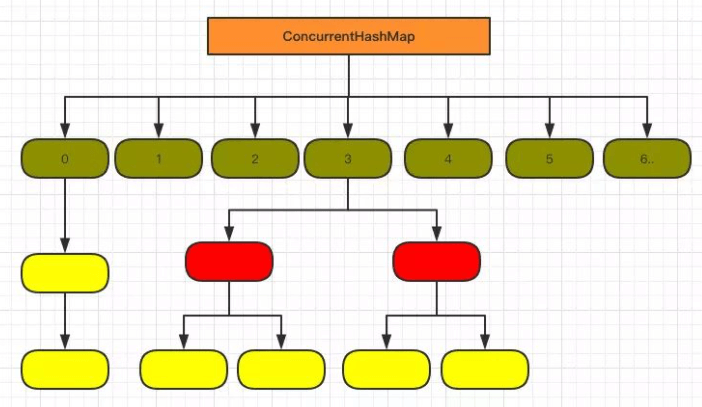
存放数据的HashEntry变成了Node,作用相同。
put方法的流程
1.根据 key 计算出 hashcode 。
2.判断是否需要进行初始化。
3.当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
自旋:不断获取当前位置的值替换自己的期望值,直到期望值和当前位置值相同,则表明其他线程都已操作完成,然后写入自己的值。
如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
采用红黑树之后可以保证查询效率(OlogN)
CAS(Compare And Swap) 比较和替换:并发算法中的一种技术,简单说就是使用一个期望值和一个变量的当前值进行比较,如果当前变量的值与我们期望的值相等,就使用一个新值替换当前变量的值。
CAS可能存在ABA问题。
2.7 集合中哪些是线程安全的?
Vector、HashTable、ConcurrentHashMap
Vector的方法都是同步的(Synchronized)
HashTable和HashMap采用相同的存储机制,二者的实现基本一致,不同的是
1)、HashMap是非线程安全的,HashTable是线程安全的,内部的方法基本都是synchronized。
2)、HashTable不允许有null值的存在。
HashSet:1、HashSet基于HashMap实现,无容量限制。2、HashSet是非线程安全的。3、HashSet不保证有序。HashMap:1、HashMap采用数组方式存储key,value构成的Entry对象,无容量限制。2、HashMap基于Key hash查找Entry对象存放到数组的位置,对于hash冲突采用链表的方式来解决。3、HashMap在插入元素时可能会要扩大数组的容量,在扩大容量时须要重新计算hash,并复制对象到新的数组中。4、HashMap是非线程安全的。5、HashMap遍历使用的是IteratorHashTable1、HashTable是线程安全的。2、HashTable中无论是Key,还是Value都不允许为null。3、HashTable遍历使用的是Enumeration。
TreeSet:1、TreeSet基于TreeMap实现,支持排序。2、TreeSet是非线程安全的。从对HashSet和TreeSet的描述来看,TreeSet和HashSet一样,也是完全基于Map来实现的,并且都不支持get(int)来获取指定位置的元素(需要遍历获取),另外TreeSet还提供了一些排序方面的支持。例如传入Comparator实现、descendingSet以及descendingIterator等。TreeMap:1、TreeMap是一个典型的基于红黑树的Map实现,因此它要求一定要有Key比较的方法,要么传入Comparator实现,要么key对象实现Comparable接口。2、TreeMap是非线程安全的。
2.8 Comparable和Comparator
Comparable 自然排序的接口,类实现了这个接口,需重写接口中的compareTo方法。意味着该类支持排序,修改类中源代码,可视为内部比较器。实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
Comparator 定制排序的接口,类本身不支持自然排序的话,建立该类的比较器来比较,这个比较器需实现Comparator接口。即:通过Comparator新建一个比较器,然后通过对这个比较器来对类排序,需重写int compare(T o1, T o2)方法,可以不重写equals方法。 返回负数,o1比o2小。Comparator相当于外部比较器,使用时不用修改类的源代码,自定义对象要比较时,只要把比较器和对象一起传过去就可以了。而且可以在比较器中实现通用的比较逻辑,使它可以对多个简单对象进行比较,节省重复劳动。
-------Comparable---------public interface Comparable<T> {public int compareTo(T o);}public class Person implements Comparable<Person>{...@Overridepublic int compareTo(Person p){return this.age-p.getAge();}}// 使用:Arrays.sort(people); // people是个对象集合
-------Comparator---------public interface Comparator<T>{int compare(T o1, T o2);boolean equals(Object obj);}// 比较器public class PersonCompartor implements Comparator<Person>{@Overridepublic int compare(Person o1, Person o2){return o1.getAge()-o2.getAge();}}// 使用Arrays.sort(people,new PersonCompartor()); // 传入对象集合和比较器
2.9 JUC下的各种集合
CountDownLatch 闭锁
CyclicBarrier 循环栅栏
Exchanger 交换器
Semaphore 信号量

若有收获,就点个赞吧
0 人点赞
