- 1. 线程的生命周期及状态
- 2. sleep()、wait()、join()、yield()的区别
- 3. 线程安全的理解
- 4. Thread、Runable的区别(这个问法有误)
- 5. 守护线程的理解
- 6. ThreadLocal 的原理和使用场景(高频)
- 7. ThreadLocal内存泄漏原因,如何避免
- 7. Threadlocal 面试总结
- 8. 并发、并行、串行的区别
- 9. 并发三大特性
- 10. 为什么用线程池?解释下线程池参数?
- 11. 简述线程池处理流程
- 12. 线程池中阻塞队列的作用?为什么是先添加队列而不是先创建最大线程?
- 12. 线程池的四种拒绝策略
- 13. 线程池中线程复用原理
- 14. 线程的四种创建方式,Runnable和Callable的区别
- 15. 线程和进程的区别
- 16. 死锁、并发操作、线程同步、中断睡眠
- 17. JDK1.8 默认的线程池及缺点
- 18. 什么是协程?
- 19. volatile
- 20. 进程间的通信方式、线程间的通信方式
1. 线程的生命周期及状态
Java基础16
2. sleep()、wait()、join()、yield()的区别
2.1 锁池和等待池
锁池:所有竞争同步锁的线程、synchronized
等待池:wait的线程在等待池,不会竞争同步锁,用notify或notifyAll放锁池

2.2 sleep()和wait()
<br />第5点,wait需要其他线程来唤醒当前线程,所以是多线程通信
2.3 join()和yield()
<br />**yield**:立马释放CPU执行权,但是可能刚释放又抢到了CPU的执行权。(通俗:让了一下别的线程,下次谁抢到CPU不一定)。<br />**join**:比如main线程调用了t1线程的join,那么main线程进入阻塞状态(注意不是t1进入阻塞),等t1结束或中断才继续main线程。(通俗:当前线程调用别的线程的join,则一定要把别的线程执行完,再回来执行当前线程)<br />
3. 线程安全的理解
线程安全:多个线程访问堆里的一个对象,如果不用进行额外的同步控制或者协调操作,调用这个对象的行为都可以得到正确的结果,即线程安全。 ——多线程和单线程结果一样就是正确的
造成线程不安全的潜在原因:进程内所有线程都能访问一块公共的区域(堆)
4. Thread、Runable的区别(这个问法有误)
其实不能对比,Thread是类,Runable是接口,Thread实现了Runable。Thread具有更多的功能。区别是使用上的区别。
5. 守护线程的理解

理解简记
Java中两种线程:用户线程、守护线程
守护线程依赖于进程而运行,它的终止是自身无法控制的
作用举例:GC垃圾回收线程
应用场景:
1.如GC线程,为其他线程提供服务支持
2.在任何情况,程序结束时线程就要立刻关闭的话,可以设为守护线程
反之,若必须正确关闭不然结果出问题的话,如进行事务,就必须用户线程
守护线程的设置在start()之前
守护线程的子线程也是守护线程
守护线程不能访问固有资源
Java自带的多线程框架,会将守护线程转为用户线程,所以要使用后台线程就不能用Java的线程池
6. ThreadLocal 的原理和使用场景(高频)

ThreadLocalMap是Thread的内部类,存储本线程中所有ThreadLocal对象和对应值
ThreadLocalMap是容器,ThreadLocal是Key,存的内容是value。这里的key(ThreadLocal对象本身)是弱引用
set:即给ThreadLocal这个变量设置值-> 当前线程对象. 当前线程的ThreadLocalMap.ThreadLocal.set( value)
class Thread {ThreadLocalMap<ThreadLocal, xxx> threadLocals; // 每条线程私有threadLocals存储本线程中所有的ThreadLocal对象(即线程里一个个变量)和对应值}
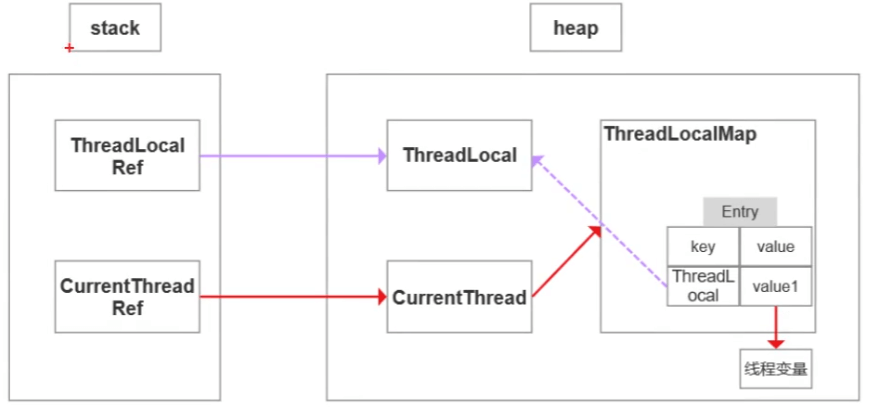
解释:栈中存放当前线程的引用,引用指向堆中当前线程对象,当前线程对象维护了一个ThreadLocalMap,Map里保存的是一个个键值对,键是ThreadLocal对象,值是线程变量的副本。
使用场景
1.controller层、service层、dao层如果都想用某一变量,设为ThreadLocal可以方便传递,不用每个地方都定义一遍
7. ThreadLocal内存泄漏原因,如何避免
内存泄漏
ThreadLocal存在内存泄漏的表面原因——key是弱引用(根源在后面)

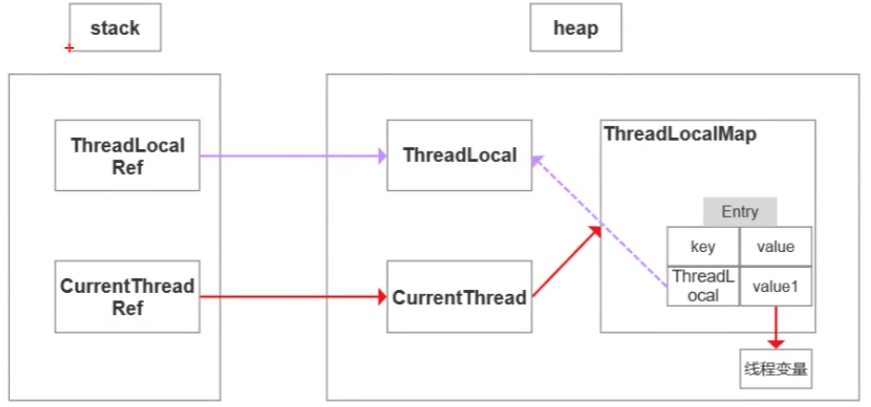
解释:栈中ThreadLocal引用指向null,则指向堆中ThreadLocal的紫色线断开,因此这个ThreadLocal对象不存在外部强引用,会被GC回收。导致Map中的key为null,value还存在强引用,线程结束才会断开。若红色链条的线程一直不结束,value就一直不能被回收,发生内存泄漏。
为什么key不用强引用——
不可的原因:这样没有外部ThreadLocalRef指向ThreadLocal对象时,它还被Map拿着,不能被回收,解决不了。
ThreadLocal存在内存泄漏的根源——由于ThreadLocalMap的生命周期和Thread一样长,如果没有手动删除对应Key就会导致内存泄漏,而不是因为弱引用。
ThreadLocal正确使用的方法:
理解简记
内存泄漏原因:由于ThreadLocalMap的生命周期和Thread一样长,如果没有手动删除对应Key就会导致内存泄漏,而不是因为弱引用
如何避免:正确使用API
7. Threadlocal 面试总结
7.1 Threadlocal 干什么的?
1.主要用作线程变量的隔离。举例:后端通常使用线程池,来一个请求就交给一个线程处理,为了防止多线程并发处理请求的时候发生串数据,就需要Threadlocal实现线程变量隔离。如:A、B两个用户的请求分别用A、B线程处理,可以把A用户的数据和A线程绑定,线程处理完后解绑。
2.保存线程上下文信息,在任意需要的地方(control层、service层、…)可获取。举例1:要使一个请求把后续关联起来,就可以用Threadlocal进行set,在后续任何需要使用的地方get获取请求id,实现整个请求串起来。举例2:Spring的事务管理,用Threadlocal存储Connection,从而各个Dao都可获取同一Connection,可以进行事务回滚、提交操作。
7.2 Threadlocal如何实现线程变量隔离及使用步骤
使用步骤:
new一个存放用户信息的Threadlocal对象
Threadlocal.set,将用户信息set到线程局部变量中
实际使用的时候用get取出来用
使用完remove掉Threadlocal
线程隔离的实现:
栈中Thread引用指向堆中Thread对象,Thread对象有一个ThreadlocalMap的成员变量,Map在中保存Entry键值对。
栈中Threadlocal引用指向堆中Threadlocal对象,Map的key是指向Threadlocal对象的弱引用,value是存储对象。
7.3 为什么要弱引用?
弱引用:ThreadlocalMap中的key指向Threadlocal对象是个弱引用
解决问题:
当gc线程扫描内存区域时,一旦发现只有弱引用对象就回收。
为了在Threadlocal所在作用域结束后,回收Threadlocal对象,使key为null,而ThreadlocalMap会根据key是否为null来判断是否清理Entry。以此尽力解决内存泄漏。
因为:线程往往声明周期很长,比如经常使用线程池,线程会一直存活着,根据JVM的可达性分析算法,一直存在Thread——ThreadlocalMap——Entry的引用链路,如果key不是弱引用的话,Threadlocal对象就一直不会被GC回收,key就一直不会是null。
7.4 为什么有内存泄露风险?
(首先如果key是强引用,强引用链导致Threadlocal对象没法被回收,出现内存泄漏问题。为了回收Threadlocal对象,key设为弱引用,导致key为null时,Entry的值还在,没法回收,又出现内存泄露风险)
当Threadlocal被回收后,key为null,但Entry中值没办法回收,因此可能发生内存泄露。
因此ThreadlocalMap会额外做些回收工作,但还是会存在风险。
所以最佳实践还是remove。
7.5 Value为什么不用弱引用?
不设置为弱引用,是因为不清楚这个Value除了map的引用还是否还存在其他引用,如果不存在其他引用,当GC的时候就会直接将这个Value干掉了,
而此时我们的ThreadLocal还处于使用期间,就会造成Value为null的错误,所以将其设置为强引用。
而为了解决这个强引用的问题,它提供了一种机制就是上面我们说的将Key为Null的Entity直接清除。
7.6 Threadlocal对象一直有强引用时,避免OOM的最佳实践
用完手动调用remove函数,回收Threadlocal,Threadlocal作为键就可以定位到Entry,把值也回收。
7.7 如果有多个变量要塞到ThreadlocalMap中,要申明多个Threadlocal对象,除此还有什么好办法?
可以再搞个封装,把ThreadlocalMap的value弄成map,这样只要一个Threadlocal对象就好了。
8. 并发、并行、串行的区别

理解简记
并行通常是需要多核CPU,并发是一个时间点只有一个在操作,但是可以不断交替执行
9. 并发三大特性
原子性、可见性、有序性
保证了三大特性才能保证线程安全
原子性:一个操作中cpu不可以中途暂停然后再调度,即不被中断操作,要不全部执行完成,要不都不执行。
如下图,123可能发生cpu调度,如果不保证原子性,i=0时发生cpu调度,两个线程都对i进行+1操作,线程各自的工作内存中都存在i=1,但是当4刷回主存时,i=1,这结果不对,会有线程安全问题。
原子操作:123三步期间,cpu不调度,第一个线程做完i=0,0+1,i=1,然后才会切换到第二个线程。但还是会发生问题,因为没发生4,线程都是从主存中获取值的。
关键字:synchronized
可见性:当多个线程访问一个变量时,一个线程修改了这个变量的值,其他线程能够立即看到修改的值。
使用总线lock、MESI(缓存一致性)两个协议保证变量可见性。
T1对0+1后,T2的0会变成失效状态,但是T2的+1还是会操作的
同时保证原子性和可见性,才能解决。
关键字:volatile、synchronized、final
有序性:虚拟机对代码重排序,而不会改变最终影响。
关键字:volatile(防止指令重排)、synchronized
volatile使用通常在new 一个对象时(三个步骤申请内存、属性赋值、赋值给栈中变量,正常情况下可能是乱的)
10. 为什么用线程池?解释下线程池参数?

注意核心线程用完,不是立马建新线程。例如
核心线程数5,最大线程数10,队列10
则第6个任务来的时候,5个核心线程满了,第六个任务存放在workQueue,第…15个任务也存在workQueue,
这时候第16个任务来了,创建第6个线程……到第20个任务时,创建了10个线程了已经,都满了,
来了第21个任务,执行Handler拒绝策略,第一种情况(不用做满20个任务)直接用shutdown关闭线程池,再向线程池提交任务就拒绝
第二种达到了最大线程数,没能力继续处理了,也拒绝,比如上面第21个任务来了就拒绝。
线程工厂创建线程,可以自定义
10.2 核心线程数的设置
提高运行速度要充分使用CPU和I/O的利用率。所以核心线程数的设置要考虑是CPU密集型还是IO密集型。
CPU密集型:核心线程数 = CPU核数 + 1
IO密集型:核心线程数 = CPU核数 * 2
CPU密集型:系统运行时,CPU占用率高,CPU有许多运算要处理,比如1+2+…+1亿,计算圆周率后几十位、数据分析
最好多核CPU处理CPU密集型,而且中间会没有线程上下文切换
IO密集型:系统运行时,大部分时间都是CPU在等I/O的读写操作,CPU使用率不高。比如大量输入输出、读文件、写文件、传输文件、网络请求。
+1是当CPU密集型线程恰好发生错误或其他原因暂停,所以需要一个额外的线程,确保这种情况下CPU周期不会中断工作。
注:IO密集型(某大厂实践经验)
核心线程数 = CPU核数 / (1-阻塞系数) 例如阻塞系数 0.8,CPU核数为4
阻塞系数=阻塞时间/(阻塞时间+计算时间)
则核心线程数为20
11. 简述线程池处理流程
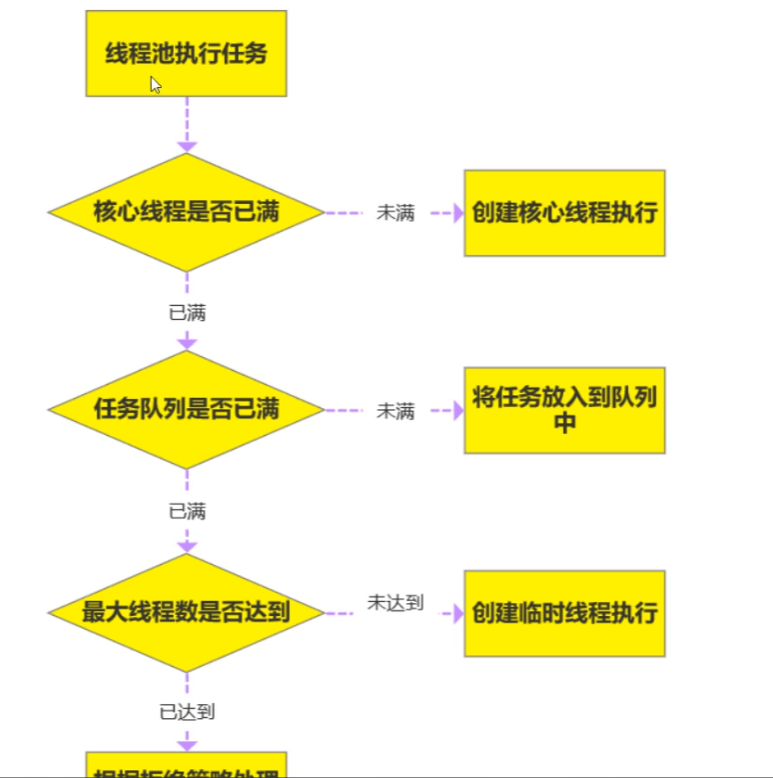
等临时线程没有任务了,空闲下来了,当临时线程超出了keepalive时间,就被回收
12. 线程池中阻塞队列的作用?为什么是先添加队列而不是先创建最大线程?


阻塞队列可以在没有任务的时候阻塞获取任务的线程,使线程进入wait状态,自动唤醒
阻塞队列两个作用
1.保存任务
2.自动阻塞和唤醒线程
先添加队列的原因:
创建线程要获取全局锁,阻塞其他的,影响效率
(如果来了任务就创建线程、回收线程,就会频繁的创建回收线程,这不是线程池的初衷)
12. 线程池的四种拒绝策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务。ThreadPoolExecutor.CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务。
丢弃任务并抛出异常
丢弃任务不抛出异常
丢弃队列最前面的任务,重新提交任务
由提交任务的线程处理该任务
13. 线程池中线程复用原理

线程和任务解耦 -> 核心原理是:
线程池对Thread封装,不是每次执行任务都调用start(),而是让线程执行“循环任务”,串联起所有任务的run()——检查、调用run()、执行(直接调任务的run方法)
14. 线程的四种创建方式,Runnable和Callable的区别
14.1 四种创建方式
1.继承Thread类
2.实现Runnable接口
3.实现Callable接口
4.使用Executor框架创建线程池
1——继承Thread类步骤1:定义一个继承Thread类的子类:class SomeThead extends Thread{public void run(){//do something here}}步骤2:构造子类的一个对象:SomeThread oneThread = new SomeThread();步骤3:启动线程:oneThread.start();
2——实现Runnable接口步骤1:创建实现Runnable接口的类:class SomeRunnable implements Runnable{public void run(){//do something here}}步骤2:创建一个类对象:Runnable oneRunnable = new SomeRunnable();步骤3:由Runnable创建一个Thread对象:Thread oneThread = new Thread(oneRunnable);步骤4:启动线程:oneThread.start();
3——实现Callable接口// Callable接口定义如下:public interface Callable<V> {V call() throws Exception;}步骤1:创建实现Callable接口的类:class SomeCallable<Integer> implements Callable<>{public void call(){//do something here}}步骤2:创建一个类对象:Callable<Integer> oneCallable = new SomeCallable<>();步骤3:由Callable<Integer>创建一个FutureTask<Integer>对象:FutureTask<Integer> oneTask = new FutureTask<Integer>(oneCallable);// 注意:FutureTask<Integer>是一个包装器,它通过接受Callable<Integer>来创建,它同时实现了Future和Runnable接口。步骤4:由FutureTask<Integer>创建一个Thread对象:Thread oneThread = new Thread(oneTask);步骤5:启动线程:oneThread.start();
4——使用Executor框架来创建线程池Executors中的ThreadFactory建立线程池,4种:缓存型池(首选) 先查看池中有没有以前建立的线程,如果有,就 reuse.如果没有,就建一个新的线程加入池中newCachedThreadPool()固定池 也是能reuse就用,但不能随时建新的线程。任意时间点,最多只能有固定数目的活动线程存在,此时如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池子newFixedThreadPool(int)调度型线程池 线程按schedule依次delay执行,或周期执行newScheduledThreadPool(int)单例线程 任意时间池中只能有一个线程SingleThreadExecutor()
自定义线程池 用ThreadPoolExecutor类创建,它有多个构造方法来创建线程池public class ThreadPoolTest{public static void main(String[] args){//创建等待队列BlockingQueue<Runnable> bqueue = new ArrayBlockingQueue<Runnable>(20);//创建线程池,池中保存的线程数为3,允许的最大线程数为5ThreadPoolExecutor pool = new ThreadPoolExecutor(3,5,50,TimeUnit.MILLISECONDS,bqueue);//创建七个任务Runnable t1 = new MyThread();Runnable t2 = new MyThread();Runnable t3 = new MyThread();Runnable t4 = new MyThread();Runnable t5 = new MyThread();Runnable t6 = new MyThread();Runnable t7 = new MyThread();//每个任务会在一个线程上执行pool.execute(t1);pool.execute(t2);pool.execute(t3);pool.execute(t4);pool.execute(t5);pool.execute(t6);pool.execute(t7);//关闭线程池pool.shutdown();}}class MyThread implements Runnable{@Overridepublic void run(){System.out.println(Thread.currentThread().getName() + "正在执行。。。");try{Thread.sleep(100);}catch(InterruptedException e){e.printStackTrace();}}}
参数:
corePoolSize:线程池中所保存的线程数,包括空闲线程。maximumPoolSize:池中允许的最大线程数。keepAliveTime:当线程数大于核心数时,该参数为所有的任务终止前,多余的空闲线程等待新任务的最长时间。unit:等待时间的单位。workQueue:任务执行前保存任务的队列,仅保存由execute方法提交的Runnable任务。
14.2 Runnable和Callable区别
1.Callable规定的方法是call(),Runnable规定的方法是run().
2.Callable的任务执行后可返回值,而Runnable的任务是不能返回值的
3.call方法可以抛出异常,run方法不可以
4.运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检索计算的结果。通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。
14.3 FutureTask的用法及使用场景
FutureTask可用于异步获取执行结果或取消执行任务的场景。经过传入Runnable或者Callable的任务给FutureTask,直接调用其run方法或者放入线程池执行,以后能够在外部经过FutureTask的get方法异步获取执行结果,所以,FutureTask很是适合用于耗时的计算,主线程能够在完成本身的任务后,再去获取结果。另外,FutureTask还能够确保即便调用了屡次run方法,它都只会执行一次Runnable或者Callable任务,或者经过cancel取消FutureTask的执行等。
1.执行多任务计算
FutureTask执行多任务计算的使用场景
利用FutureTask和ExecutorService,能够用多线程的方式提交计算任务,主线程继续执行其余任务,当主线程须要子线程的计算结果时,在异步获取子线程的执行结果。
2.高并发环境下
FutureTask在高并发环境下确保任务只执行一次
在不少高并发的环境下,每每咱们只须要某些任务只执行一次。这种使用情景FutureTask的特性恰能胜任。举一个例子,假设有一个带key的链接池,当key存在时,即直接返回key对应的对象;当key不存在时,则建立链接。对于这样的应用场景,一般采用的方法为使用一个Map对象来存储key和链接池对应的对应关系。
为了确保任务只执行一次,其他两种方式的缺点:
1.加锁确保高并发下的线程安全,确保了connection只建立了一次,但牺牲了性能
2.使用ConcurrentHashMap的状况下,几乎能够避免加锁的操做,性能大大提升,可是在高并发的状况下有可能出现Connection被建立屡次的现象
为解决重复建立连接,加入FutureTask后,解决了当key不存在时,建立Connection的动作能放在connectionPool以后执行。避免因为并发带来的屡次建立链接及锁的出现。
实现一个简单的FutureTask
1、范型2、构造函数,传入Callable3、实现Runnable4、有返回值
15. 线程和进程的区别
进程(Process):
一个程序运行起来时在内存中开辟一段空间用来运行程序,这段空间包括heap、stack、data segment和code segment。例如,开一个QQ就表明开了一个QQ进程。
线程(Thread):
每个进程中都至少有一个线程。线程是指程序中代码运行时的运行路径,一个线程表示一条路径。例如QQ进程中,发送消息、接收消息、接收文件、发送文件等各种独立的功能都需要一个线程来执行。
进程和线程的区别:
从资源的角度来考虑,进程主要考虑的是CPU和内存,而线程主要考虑的是CPU的调度,某进程中的各个线程之间可以共享这个进程的很多资源。
从粒度粗细来考虑,进程的粒度较粗,进程上下文切换时消耗的CPU资源较多。线程的粒度要小的多,虽然线程也会切换,但因为共享进程的上下文,相比进程上下文切换而言,同进程内的线程切换时消耗的资源要小的多的多。在JAVA中,除了java运行时启动的JVM是一个进程,其他所有任务都以线程的方式执行,也就是说java应用程序是单进程的,甚至可以说没有进程的概念。
16. 死锁、并发操作、线程同步、中断睡眠
死锁:
线程全睡眠了无法被唤醒,导致程序卡死在某一处无法再执行下去。典型的是两个同步线程,线程1持有A锁,且等待B锁,但线程2持有B锁且等待A锁,这样的僵局会造成死锁。但需要注意的是,死锁并非都是因为僵局,只要两边的线程都无法继续向下执行代码(或者两边的线程池都无法被唤醒,这是等价的概念,因为锁等待也会让进程进入睡眠态),则都是死锁。
并发操作:
多个线程同时操作一个资源。这会带来多线程安全问题,解决方法是使用线程同步。
线程同步:
让线程中的某些任务原子化,即要么全部执行完毕,要么不开始执行。通过互斥锁来实现同步,通过监视这个互斥锁是否被谁持有来决定是否从睡眠态转为就绪态(即从线程池中出去),也就是是否有资格去获取cpu的执行权。线程同步解决了线程安全的问题,但降低了程序的效率。
中断睡眠(interrupt):
将线程从睡眠态强制唤醒,唤醒后线程将进入就绪队列等待cpu调度。
17. JDK1.8 默认的线程池及缺点
默认的即java.util.concurrent.Executors类下的六种方法(前四种问的概率大)。
实际应用中,不使用默认的,而是使用自定义线程池ThreadPoolExecutor。以上几种默认的底层也是调用自定义线程池的构造方法实现,只不过参数都已经定义好了。
17.1 默认线程池介绍
- newFixedThreadPool
定长线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程数量不再变化,当线程发生错误结束时,线程池会补充一个新的线程。
// 定长线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,// 这时线程数量不再变化,当线程发生错误结束时,线程池会补充一个新的线程static ExecutorService fixedExecutor = Executors.newFixedThreadPool(3);...fixedExecutor.execute(new Runnable() {...});
- newCachedThreadPool
可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程,任务增加时可以自动添加新线程,线程池的容量不限制。
//可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程,任务增加时可以自动添加新线程,线程池的容量不限制static ExecutorService cachedExecutor = Executors.newCachedThreadPool();...cachedExecutor.execute(new Runnable() {...});
- newScheduledThreadPool
调度线程池,可执行周期性的任务。
// 定时线程池,可执行周期性的任务static ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(3);...// scheduleWithFixedDelay 固定的延迟时间执行任务;// scheduleAtFixedRate 固定的频率执行任务scheduledExecutor.scheduleWithFixedDelay(new Runnable() {...},0 ,3, TimeUnit.SECONDS);
- newSingleThreadExecutor
单线程的线程池,线程异常结束,会创建一个新的线程,能确保任务按提交顺序执行。
- newSingleThreadScheduledExecutor
单线程可执行周期性任务的线程池。
- newWorkStealingPool
任务窃取线程池,不保证执行顺序,适合任务耗时差异较大。
线程池中有多个线程队列,有的线程队列中有大量的比较耗时的任务堆积,而有的线程队列却是空的,就存在有的线程处于饥饿状态,当一个线程处于饥饿状态时,它就会去其它的线程队列中窃取任务。解决饥饿导致的效率问题。
默认创建的并行 level 是 CPU 的核数。主线程结束,即使线程池有任务也会立即停止。
//任务窃取线程池static ExecutorService workStealingExecutor = Executors.newWorkStealingPool();...//测试任务窃取线程池private static void testWorkStealingExecutor() {for (int i = 0; i < 10; i++) {//本机 CPU 8核,这里创建10个任务进行测试final int index = i;workStealingExecutor.execute(new Runnable() {public void run() {try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + " index:" + index);}});}try {Thread.sleep(4000);//这里主线程不休眠,不会有打印输出} catch (InterruptedException e) {e.printStackTrace();}System.out.println("4秒后...");// workStealingExecutor.shutdown();}
打印结果如下,index:8,index:9并未打印出:
ForkJoinPool-1-worker-1 index:0ForkJoinPool-1-worker-7 index:6ForkJoinPool-1-worker-5 index:4ForkJoinPool-1-worker-3 index:2ForkJoinPool-1-worker-4 index:3ForkJoinPool-1-worker-2 index:1ForkJoinPool-1-worker-0 index:7ForkJoinPool-1-worker-6 index:54秒后...
17.2 默认线程池底层源码解读
java.util.concurrent.Executors的底层源码
public class Executors {public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory);}public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory));}public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),threadFactory);}public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);}public ScheduledThreadPoolExecutor(int corePoolSize,ThreadFactory threadFactory) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue(), threadFactory);}
从这几个线程池中可以看到,他们的底层都是调用自定义线程池ThreadPoolExecutor的构造方法实现的,只不过一些参数都已经自定义好了。
从源码中可以看到FixedThreadPool 和 SingleThreadPool,允许的缓存队列的长度都是Integer.MAX_VALUE,所以他就是存在队列无限长的问题,最终会导致OOM的异常,甚至导致资源耗尽。
而CachedThreadPool和newScheduledThreadPool允许的最大线程数是Integer.MAX_VALUE,也就是他能无限的创建线程,这样也会导致资源耗尽或者出现OOM异常。
而使用ThreadPoolExecutor自定义线程池,可以更加明确线程池的运行规则,避免资源耗尽的风险。
18. 什么是协程?
多线程的问题:10000个任务,采用多线程需要创建10000个线程。操作系统在线程等待IO的时候,会阻塞当前线程,切换到其它线程,这样在当前线程等待IO的过程中,其它线程可以继续执行。当系统线程较少的时候没有什么问题,但是当线程数量非常多的时候,却产生了问题。一是系统线程会占用非常多的内存空间,二是过多的线程切换会占用大量的系统时间。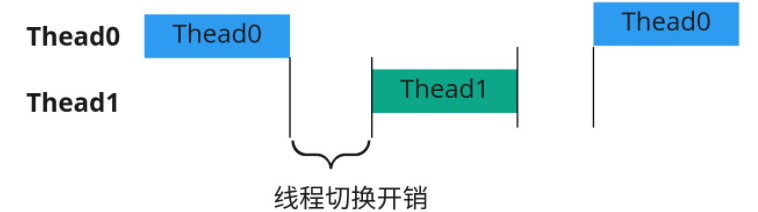
问题的解决:使用协程,启动100个线程,每个线程上运行100个协程,减小线程切换开销。协程运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。
分时复用:采用同一物理连接的不同时段来传输不同的信号,能达到多路传输的目的。在网络中应用于用一条线路传输多路数据。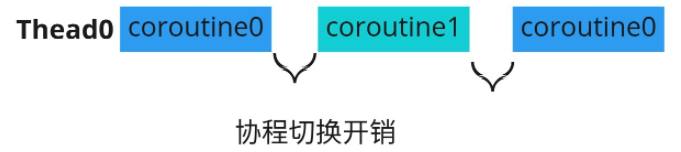
但是:操作系统不知道协程的存在,一旦协程调用一个阻塞IO操作,操作系统会让线程进入阻塞状态,该线程上的所有协程都陷入阻塞,得不到调度。所以要注意:协程中不能调用导致线程阻塞的操作,协程应该和异步IO结合起来。
协程中调用阻塞IO操作的处理方式:
1.在调用阻塞IO操作的时候,重新启动一个线程去执行这个操作,等执行完成后,协程再去读取结果。这其实和多线程没有太大区别。
2.对系统的IO进行封装,改成异步调用的方式,这需要大量的工作,最好寄希望于编程语言原生支持。
总结:
协程减少线程切换,所以速度快。
在有大量IO操作业务的情况下,我们采用协程替换线程,可以到达很好的效果,一是降低了系统内存,二是减少了系统切换开销,因此系统的性能也会提升。
在协程中尽量不要调用阻塞IO的方法,比如打印,读取文件,Socket接口等,除非改为异步调用的方式,并且协程只有在IO密集型的任务中才会发挥作用。
19. volatile
相对同步锁更为轻量,它修饰的变量对所有线程具有可见性。
可见性:当一个线程修改了变量的值,新的值会立刻同步到主内存当中。而其他线程读取这个变量的时候,也会从主内存中拉取最新的变量值。
但是volatile不保证变量的原子性。——例如:并发自增 count++问题
count++不是原子性操作,而是由多个原子操作的组合,它可以分为:
getstatic //读取静态变量(count)
iconst_1 //定义常量1
iadd //count增加1
putstatic //把count结果同步到主内存
volatile可以保证的是getstatic(读取变量)这一步的可见性,但是在进行iadd(增加1)这步时,可能其他线程已经让count加了很多次,这样当前线程计算更新的就是个陈旧的count值,导致写入主内存的是个错误值,线程不安全。
volatile适用场合:
1.运行结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
2.变量不需要与其他的状态变量共同参与不变约束。
在字节码上没有区别,但是在汇编层,程序在那行加了lock。
20. 进程间的通信方式、线程间的通信方式
20.1 进程间8种通信方式
1.匿名管道通信:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2.高级管道通信:将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程,这种方式我们成为高级管道方式。
3.有名管道通信:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
4.消息队列通信:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5.信号量通信:信号量(semophore)是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
6.信号:信号(signal)是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
7.共享内存通信:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
8.套接字通信:套接字(socket)也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
8的通信过程:命名socket——绑定——监听——连接服务器——相互发送接收数据——断开连接
20.2 线程间

若有收获,就点个赞吧
0 人点赞
