2. 分布式缓存问题
问题:一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。重新映射效率低下。
想要的解决结果:在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
一致性哈希算法
1.求出服务器(节点)的哈希值,将其存储空间抽象成一个环,0~2^32-1,按顺时针方向组织
2.将请求使用哈希算法(如MD5)算出对应的hash值,沿圆环顺时针查找,碰到的第一台服务器即处理对应请求的服务器
当增加一台服务器时,仅前一台服务器的数据需重新映射,其他不受影响
优点/性质:平衡性、单调性、分散性、负载、平滑性
问题:1.查询消息要经过O(n)步(n就是节点总数)才能到达节点。节点数量达百万时,查询效率低
2.节点分布不均造成数据倾斜问题(就是没有平均分配)。比如当B宕机了,数据落到C上,C负载变高,可能也会宕机,依次下去,整个集群都挂了。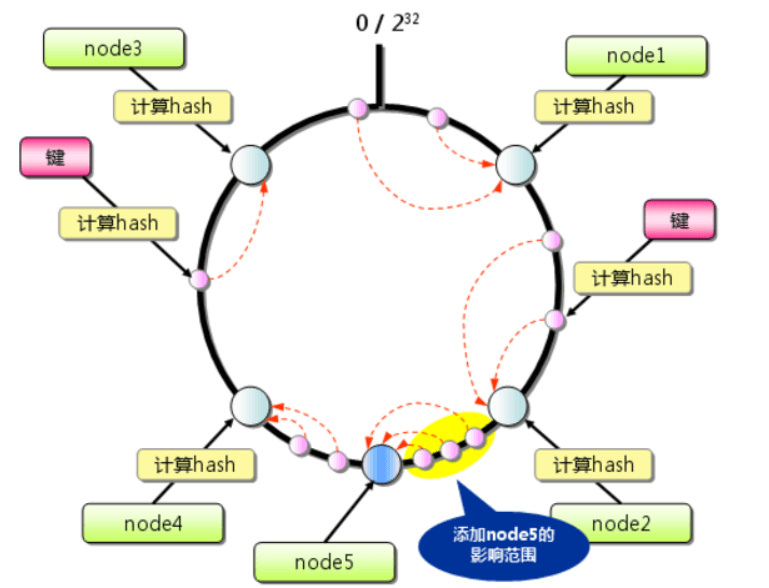
虚拟节点机制
每个服务器节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可在服务器ip或主机名后增加编号实现。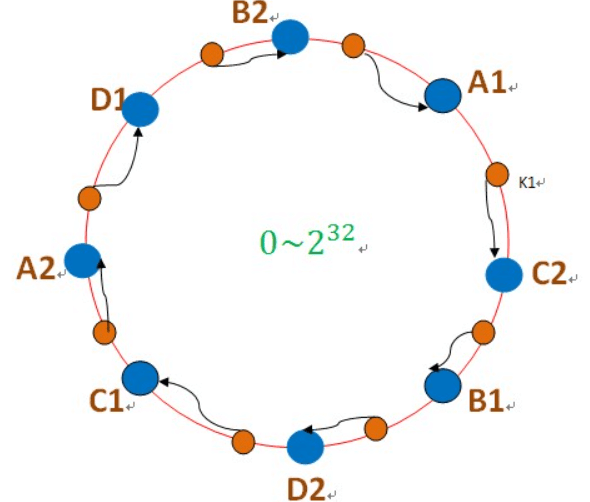
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。

若有收获,就点个赞吧
0 人点赞
