1. 自我介绍
面试官好,我叫陈斌,今年25岁,本硕均就读于浙江工业大学,是控制科学与工程专业的应届毕业生。
在校期间我以较优异的成绩完成了所学课程,获得过优秀学生二等奖学金、研究生一等学业奖学金。参与了导师的自然科学基金项目,并完成论文一篇。
我系统性学习过Java、数据库、数据结构、计算机网络等相关知识,熟悉Spring、SpringBoot、MyBatis等开发框架,并基于此实现了两个Java项目,一个是用于牡丹花种类识别的微信小程序,另一个是具有游客浏览和用户权限管理的个人博客。
我热爱运动,会排球、柔力球等各项球类,当过乒乓球裁判,参加过25公里的毅行并走完全程。
此外,我积极参与志愿者活动,曾作为领队到国家湿地博物馆、太子湾公园等地协助工作。
以上是我的自我介绍,谢谢。
看过的书
看过一些,像阿里的《码出高效:Java开发手册》,《小灰的算法之旅》,还有《Java编程思想》(一本黑皮的大书)。但是我是挑着看里面的一些部分,没有完整的把他看完。
你这个专业和计算机有什么关系
嗯,是这样的。控制科学与工程在本科叫自动化,目的是用计算机编程的方法去操作设备。所以他是对编程思维有要求的,刚开始的两年就学过C、C++、java这些编程语言,后来还学过计算机网络、数据结构这些课程。
到了研究生这个专业就分成了两派,一派还是坚持搞传统控制,直接面对设备调试。另一派就是像我们导师这边,偏向于计算机,针对不同课题去写算法或者根据项目搞软件开发,还有两者结合。
嗯……比如我们有一个项目就是牡丹花卉种类识别系统,前端用的微信小程序,识别算法是另一同学写的C++代码,然后后端用的java和SpringBoot框架。
所以我感觉,我们专业和计算机的关系是非常密切的。于是我投了这个岗位。
职业规划
2. 博客项目
2.1 简历上的描述
个人博客 2021年05月 - 2021年06月
项目概述:基于Spring Boot框架进行后端开发,采用MySQL数据库存储相关表格数据,并利用MyBatis-Plus进行持久层操
作,实现博客文章显示、发布及评论。
功能模块:注册登录、文章列表显示、文章发布、评论、权限管理
具体实现:
- 使用JWT+Redis实现用户登录验证,提高前端数据和后端验证的安全性,Redis缓存已登录的用户信息,减少对数据库
的操作,提高用户访问速度。 - 使用ThreadLocal保存用户信息,使得在使用线程内可随时获取用户信息,实现线程隔离。
- 使用线程池更新阅读次数,避免影响主线程的使用(文章详情即时显示)。
- 使用Spring Security进行权限认证,赋予管理员和普通用户不同的操作权利(删除和浏览)。
- 使用AOP技术实现统一的日志记录、缓存处理。
2.2 全项目描述
博客系统基于SpringBoot+MySQL进行开发,主要功能有注册登录、文章列表分页显示、文章的发布和评论。没登录账号时,可以看到我博客的文章列表,只有在登录后,才能发布文章以及对文章进行评论。此外,还做了一个相应的后台管理模块,来实现不同人员以不同权限操作博客,防止博客被误删。
整个项目的流程就是:(也即文章显示模块的实现)
1.用户在浏览器中输入url,发起请求。
2.服务端根据不同的请求,调用不同的Controller方法。
3.Controller方法调用相关Service接口和它实现类的业务逻辑方法。
4.Service类中的业务方法会调用mapper接口中的方法(复杂的两表联合查询要自己建立xml去写SQL)。
5.我的项目中Mapper继承了MyBatis-Plus的BaseMapper接口,可以使用MyBatis-Plus提供的单表查询、修改等方法,直接对数据库进行操作,并将数据最终返回到Controller,渲染到指定页面。
例如:最新文章显示模块就是:
1.接口为new,调用newArticles这个Controller方法
2.调用ArticleService接口的newArticles实现方法
3.查询条件就是对文章按照创建日期排序,然后给定取5条显示的limit
4.作为条件查询得到5篇文章,包装成显示到浏览器的Vo对象返回。
2.3 重点模块讲解
2.3.1 文章首页、分类、归档分页显示
使用了MyBatis-Plus的分页插件PaginationInnerInterceptor()去实现文章的分页显示
博客的三个地方用到了分页显示
1.文章首页是只需将文章按是否置顶、创建时间先后排序,分页列表显示即可
2.文章分类是按照类别和标签来显示文章,在这基础上,按请求体中传入的 类别 和 标签 参数进行查询再分页显示
3.文章归档则是要按照年月来显示文章,按请求体中传入的 年 和 月 这对参数进行查询再分页显示
我把上述需要的pagesize、类别id、标签id、年、月,都封装成一个参数对象。不同地方调用的时候,传入需要的参数,其他就是null,然后在mapper里,自己写sql语句,用where和if标签去实现按需查询。
2.3.2 登录验证模块
登录
用户申请登录,发起请求,请求体中包括account、password、nickname等信息,封装成登录参数对象LoginParam
LoginController.login() -> LoginService.login() -> LoginServiceImpl 开始业务逻辑:
属性:
查询用户表:sysUserService 对应 user表
整合Redis:redisTemplate
加密盐:slat = “mszlu!@#”
login() : 登录的时候redis存的用户信息就是一个userid,不是整个user信息
1.获取参数账号和密码,判断是否为空,为空直接返回错误码
2.不为空,则对密码加密(采用了md5加密,放了个加密盐增加安全性)
3.拿着账号和密码去用户表中查询,是否存在,不存在的话直接返回错误码
4.存在的话,使用jwt,根据用户id生成token(每次登录都要生成一个不同的token,持续在线的时候token是同一个)
5.将token作为令牌(key),保存用户信息(…),存到Redis中,并设置过期时间
6.返回token给前端(token会被前端存储在本地的storage中)
考虑一下:jwt token 由 A.B.C 三部分组成,过期时间在B部分 是可以解码获得的(不需要密钥),前端可以通过B部分的解码 来指导token是否过期
登录成功
博客中的文章显示、分类这些都不需要登录状态,但是像发布文章、发表评论,是需要用户登录才能进行的。
所以,我利用自定义的登录拦截器,对特定请求的登录状态进行验证。如果没有登录,拦截器就直接拦截,并跳转登陆页面。
验证(一些操作比如发布文章、评论前提都要求是已登录状态,所以需要拦截器在这些操作之前对登录进行判断)
——通过登录拦截器的preHandle方法,统一登录判断(在登录之前调用checkToken验证token)
LoginInterceptor.preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
参数为:请求request、响应response、Controller下的执行方法handler
该方法将在请求处理之前进行调用,该方法返回true,才会继续执行后续的Interceptor和Controller
1.首先要判断请求的接口路径是否是HandlerMethod(Logincontroller方法),不是的话直接放行,避免影响静态资源的访问
2.是的话,从请求(头)中获取(Authorization)token
3.判断是否为空,空的话就是未登录,返回一个JSON信息,给浏览器(写在response里)
4.token不为空,登录验证(调用了Loginservice层的checkToken)
验证过程:
1.使用JWT验证token是否合法
2.从Redis缓存中拿出token对应的用户信息(放在缓存中就不用去数据库里拿了)
3.将json的信息解析成用户对象返回
5.认证通过,放行
JWT验证:
服务端接收到请求之后,从 Token 中拿出 header 和 payload ,然后通过HS256算法将 header 和 payload 和 “盐” 值 再次签名,让计算出的内容与Token中的第三部分,也就是Signature去比较,如果一致则验证通过,反之则失败。
注:HandlerMethod:Spring MVC中的一个类,负责准备数据,蜂虎在那个数据,而不提供具体使用的方法,有两个子类,具有调用能力
2.3.3 ThreadLocal保存信息,实现Control、Service层变量共享(修改下简历)
token会被前端存储在本地的storage中,拿到storage会去获取用户信息,要实现接口 /users/currentUser.
请求参数是authorization,是在请求头中。
为了让controller直接获取用户信息,并使用。
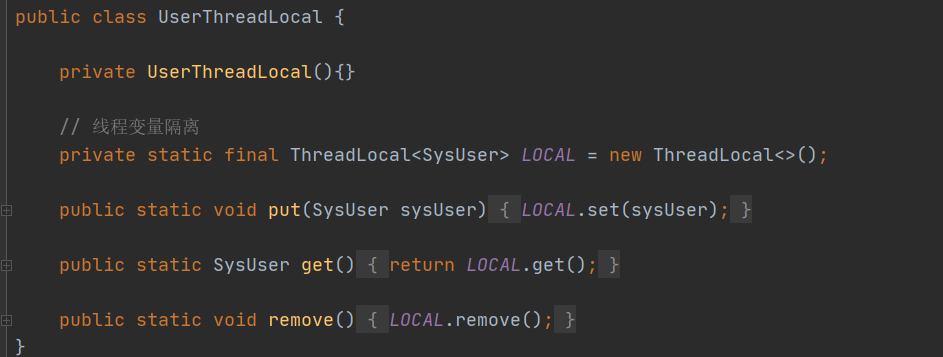
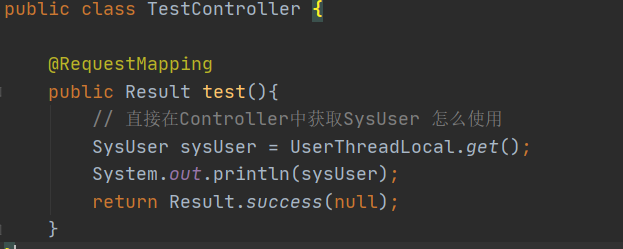
拦截器的preHandle中put
用完要删除,在拦截器后删除
2.3.4 线程池更新阅读数
需求:查看完文章后需要新增阅读数
问题:
1.查看完文章后本该直接返回数据,这时候做了一个更新操作,而更新时会加写锁,阻塞其他的读操作,性能会降低(无法解决和优化)。
2.更新增加了此次接口的耗时(可以优化)。 ——一旦更新出问题,不能影响 查看文章 的操作
优化:采用线程池,把更新操作扔到线程池中操作,与主线程不相关。
ThreadService updateArticleViewCount
配置一个线程池的类:ThreadPoolConfig,设置7个线程池属性
使用线程池:在业务逻辑(更新阅读数)的方法上加上一个异步执行的注解@Async(“taskExecutor”),把线程池的名字填入
更新阅读数的主要操作就是
1.查询当前阅读数
2.然后把文章id作为条件查询
3.更新阅读数为+1
注意的点是:但是其中,为了在多线程的环境下,保证线程安全:用一个类似CAS机制的操作去保证:
在最后更新前将刚查到的当前阅读数和文章id一起作为条件查询,这样确保没有其他线程在操作,再执行+1。
当多用户同时点击这篇文章时,为了保证线程安全,使用类似CAS机制的操作去保证。
为了避免更新文章次数的失败或者时间太长,把更新操作扔到线程池中操作。
使得主线程的文章显示不受影响。
2.3.5 Spring Security进行权限认证
权限认证就是:
我登录后,想点击删除一个文章,我点下去的时候就发送了一条删除请求,然后服务器就要通过授权认证判断我是否具有权限,如果有权,则删除成功。
使用了Security安全框架
https://blog.csdn.net/u012702547/article/details/89629415
https://blog.csdn.net/wu2374633583/article/details/108199205?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.no_search_link&spm=1001.2101.3001.4242
集成Security,先添加依赖
配置SecurityConfig类,继承WebSecurityConfigurerAdapter类
实现AuthService中的方法
登录认证:
User类实现UserDetails接口,用户名就是客户端传递过来的username, 密码则是从数据库中查询出来的密码。
Spring Security会根据用户名从数据库查询的密码和客户端传递过来的password进行比较。
如果相同,则表示认证通过,如果不相同则认证失败。
实现UserDetailsService接口,重写加载用户名称方法。实现登录成功后,返回用户信息。
授权认证:(查是否有相关删除权限)
通过Authentication类的对象的getPrincipal可以获得当前的登录用户,进行授权。
在权限和用户的关联表中,通过对应admin_id,找到对应的permission_id。
根据permission_id在permission表中查询path属性,与请求路径相比较,如果一致,则有权限操作。
2.3.6 AOP实现日志打印和统一缓存
打印日志:
自定义log注解和log切面,采用环绕通知的方式,在ProceedingJoinPoint对象的proceed()方法执行前后进行打印。
打印内容:请求的方法名、请求参数、ip地址、执行时间
自定义cache注解和cache切面,获取key,根据key查询redis中是否有值(文章列表、最新文章、最热文章等信息),没有的话,存入缓存并设置过期时间。 将各种文章信息统一存储,设置为5分钟,这样来回切换将直接走redis缓存,避免了查询数据库。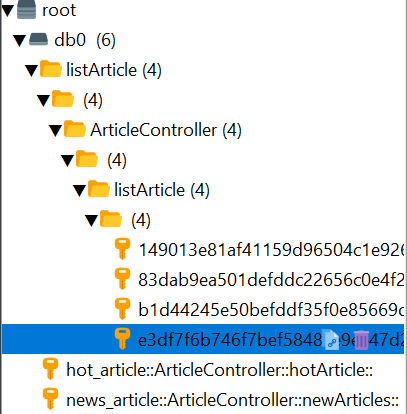
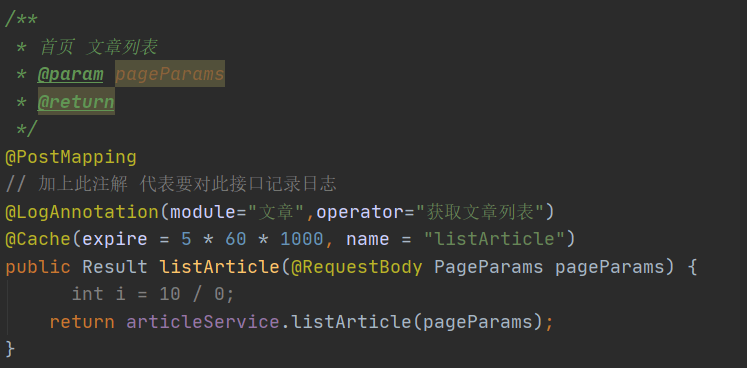
存了文章列表:listArticle请求 -> ArticleController -> listArticle方法下的文章信息
存了最热文章:hot_article请求 ->ArticleController -> hotArticles下的文章信息
存了最新文章:news_article请求 ->ArticleController -> newArticles下的文章信息 是list
2.3.7 其他模块
上传图片
2.4 遇到的问题
缓存出现了精度损失问题:因为文章id采用分布式id(便于以后扩展操作),从redis中获取id解析成long后,返回前端的时候出现精度损失,匹配不上。所以把ArticleVo中的id从long改成了String类型。
在sevice层的实现方法中,把关于setid()里的参数,都String.valueOf(toString可能会出现空指针异常)转成String类型。
更新阅读数,考虑到之后可能出现并发问题,使用了类似版本号实现乐观锁。
2.4.1 Redis断电后,数据丢失怎么解决的——Redis持久化机制
Redis虽然是定义为一个内存数据库,但是其也支持数据的持久化,在Redis中提供了两种持久化机制:RDB持久化和AOF持久化。
2.4.2 Redis如何保证和MySQL的缓存一致性
2.5 相关技术栈和问题
2.5.1 JWT
Token的生成(通过传入的用户id)
1.用户id 包装成一个HashMap key-value形式 —— 作为JWT中的B
2.JwtBuilder:signWith():签发算法——选择HS256, 密钥为jwtToken (服务端设置的一个字符串,保密) ——作为JWT的A
setClaims():body数据 ——用户id ——作为JWT的B
setIssuedAt():设置签发时间
setExpiration():设置有效时间 ——我设了一天
3.把2中的各部分连起来,生成一个字符串token
Token的验证(传入token)
即检验C是否合法
使用密钥jwtToken解析token
解析成功,得到body数据——即用户id信息(解析成功表示存在,直接返回)
JWT鉴权机制
https://www.jianshu.com/p/576dbf44b2ae
JWT(token)三部分:头部header、载荷(payload)、签证(signature)
头部:声明——类型(jwt)和加密算法(哈希SHA256) -> base64编码 明文
载荷:存放有效信息——用户id、签发时间、过期时间… -> base64编码 明文
签名:对摘要加密——对头部和载荷(都经过base64加密)使用哈希算法(SHA256)生成摘要,对摘要用密钥和加密盐组合加密
三部分连接成一个字符串即jwt
其中加密的密钥存于服务器端,jwt的签发生成也在服务端。
应用:浏览器的请求头中加入Authorization,加上Bearer标注token。服务端会验证token,通过的话返回相应资源。
验证:
服务端接收到请求之后,从 Token 中拿出 header 和 payload ,然后通过HS256算法将 header 和 payload 和 “盐” 值 再次签名,让计算出的内容与Token中的第三部分,也就是Signature去比较,如果一致则验证通过,反之则失败。
从头部取出exp对存活期进行判断,如果超过了存活期就返回空字符串,如果在存活期内返回userid的值。
优点:jwt构成简单,字节占用小,便于传输。不需服务端保存会话信息。
2.5.2 如何在SpringBoot中自定义一个拦截器(针对特定请求:比如发布文章publish、评论comment)
1.创建自己的拦截器:实现HandlerInterceptor接口,然后按需要重写接口中三个方法:preHandle()、postHandle()、afterCompletion()。
preHandle(),预处理回调方法,实现处理器的预处理,如:登录检查,都是在请求controller层之前执行,postHandle(),后处理回调方法,实现处理器的后处理,但是要在渲染视图之前afterCompletion(),整个请求处理完毕回调方法,要在整个视图渲染完毕后回调
2.注册自己创建的拦截器:写个配置类实现WebConfigurer接口,重写接口中的addInterceptors()方法将拦截器添加进去。
3.通过addPathPatterns添加拦截路径(只在这两个请求的时候发起拦截,对登录状态进行判断)
@Configurationpublic class WebMVCConfig implements WebMvcConfigurer {@Autowiredprivate LoginInterceptor loginInterceptor;@Overridepublic void addInterceptors(InterceptorRegistry registry) {// 添加拦截器registry.addInterceptor(loginInterceptor).addPathPatterns("/comments/create/change") // 添加具体拦截路径请求.addPathPatterns("/articles/publish");}}
2.5.3 如何实现AOP打印日志、统一缓存(自定义注解的方式)
https://blog.csdn.net/mu_wind/article/details/102758005
2.5.3.1 相关概念:AOP的图解、AOP概念详解、AOP相关注解
2.5.3.2 本项目中AOP的实现
2.5.3.1 AOP的相关概念(图解、概念详解、@Around)
AOP是OOP的强大补充,它可以通过横切面注入的方式引入其他的额外功能,我的项目中就将打印日志还有信息统一缓存,这些非业务逻辑功能,用AOP的方式实现。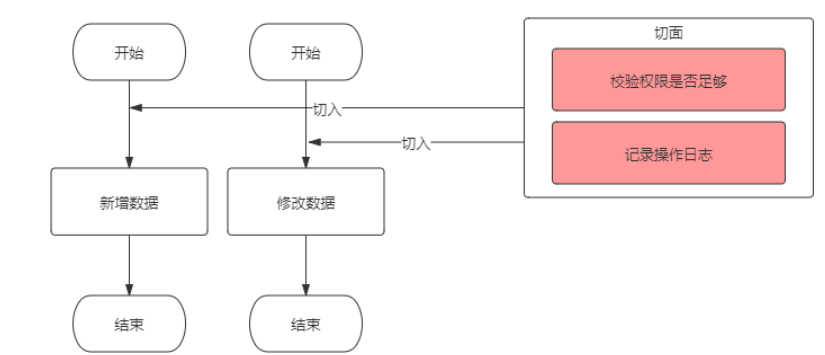
AOP体系
概念详解
注意:
连接点:连接切点与索要切入的(业务程序)方法
示意图(重点看 连接点和切点的关系)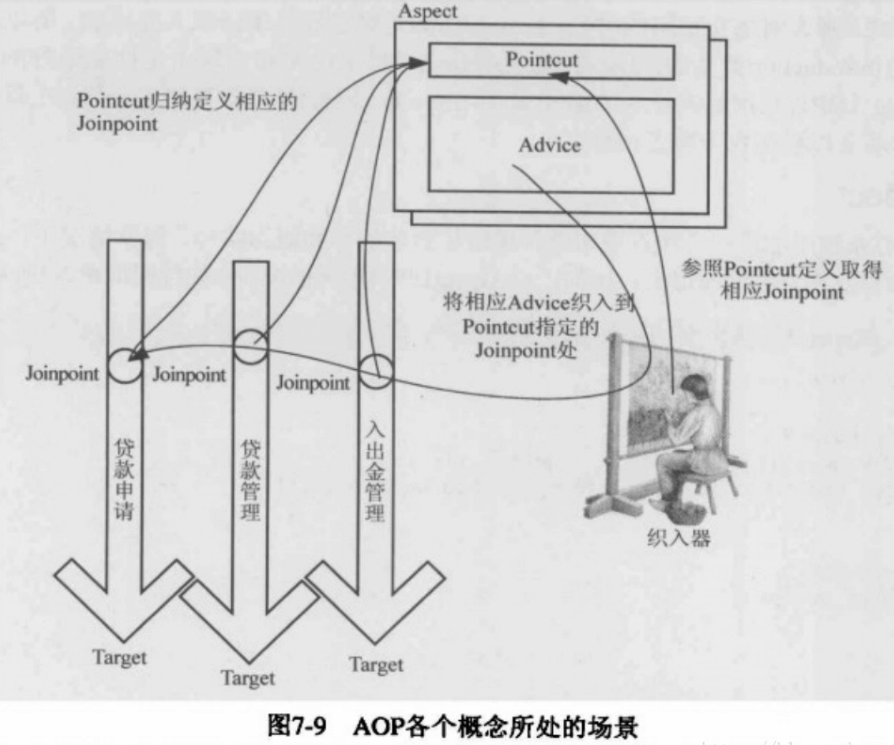
注解一:@Pointcut
用来定义一个切点,即上文中所关注的某件事情的入口,切入点定义了事件触发时机。@Pointcut 注解指定一个切点,定义需要拦截的东西,这里介绍两个常用的表达式:一个是使用 execution(),另一个是使用 **annotation()**。
注解二:@Around
2.5.3.2 实现一个AOP实例
1.使用三个元注解:@Target、@Retention、@Documented自定义一个注解@LogAnnontation。
// Type 代表可以放在类上面// METHOD 代表可以放在方法上@Target(ElementType.METHOD) // 定义注解的使用位置@Retention(RetentionPolicy.RUNTIME) // 定义注解的生存周期(源码级别保留、编译级别保留、运行级别保留)@Documented // 指明修饰的注解可以被javadoc此类的工具文档化,只负责标记public @interface LogAnnotation {String module() default ""; // 设定模块名String operator() default ""; // 设定操作}
2.创建一个AOP切面类,只要在类上加个@Aspect注解即可。切面类中定义了切点(@Pointcut)和通知(@Advice)。
切点设置为拦截所有标注@LogAnnontation的方法,通知定义了处理内容(打印日志)和处理时机(@Around,表示在业务前后)。
使用@Component注解加入Spring容器。
@Component@Aspect // 切面 定义了通知和切点public class LogAspect {// 定义一个切点:所有被@LogAnnotation注解修饰的方法会织入advice@Pointcut("@annotation(com.mszlu.blog.common.aop.LogAnnotation)") // 自定义注解路径public void logAdvicePointcut() {}// 环绕通知 表示logAdvice将在目标方法执行前后执行// 打印执行时间:ProceedingJoinPoint@Around("logAdvicePointcut()")// ProceedingJoinPointpublic Object logAdvice(ProceedingJoinPoint joinPoint) throws Throwable {long beginTime = System.currentTimeMillis();//执行方法Object result = joinPoint.proceed();//执行时长(毫秒)long time = System.currentTimeMillis() - beginTime;//保存日志recordLog(joinPoint, time);return result;}
ProceedingJoinPoint的相关方法
//拦截的实体类Object target = point.getTarget();//拦截的方法名称String methodName = point.getSignature().getName();//拦截的方法参数Object[] args = point.getArgs();//拦截的参数类型Class[] parameterTypes = ((MethodSignature)point.getSignature()).getMethod().getParameterTypes();Method m = null;try {//通过反射获得拦截的methodm = target.getClass().getMethod(methodName, parameterTypes);//如果是桥则要获得实际拦截的methodif(m.isBridge()){for(int i = 0; i < args.length; i++){//获得泛型类型Class genClazz = GenericsUtils.getSuperClassGenricType(target.getClass());//根据实际参数类型替换parameterType中的类型if(args[i].getClass().isAssignableFrom(genClazz)){parameterTypes[i] = genClazz;}}//获得parameterType参数类型的方法m = target.getClass().getMethod(methodName, parameterTypes);}} catch (SecurityException e) {e.printStackTrace();} catch (NoSuchMethodException e) {e.printStackTrace();}
2.5.3.3 AOP是什么时候失效
1.不能切入private方法
2.无法切入方法内部调用
比方说service中有个方法A,controller中调用的是service.A(),而方法A()中内部调用了方法B和方法C。此时注解打在A()上面是没有问题的,打在B()或C()上是没有效果的,原因和上面类似,都是由于代理类的问题,见下图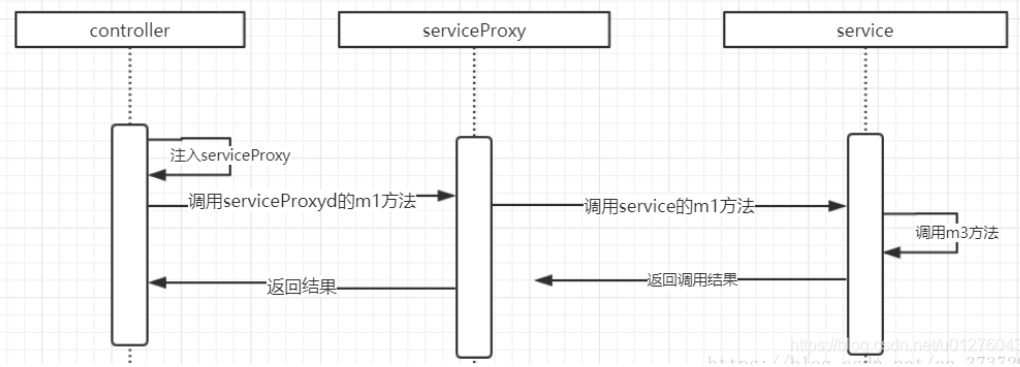
2.5.4 线程池创建和使用
注解:@EnableAsync // 开启多线程
1.配置ThreadPoolConfig配置类 设置7个线程池属性
@Configuration@EnableAsync // 开启多线程 进程一启动就创建好了public class ThreadPoolConfig {@Bean("taskExecutor")public Executor asyncServiceExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); // 使用带任务的线程池// 设置核心线程数executor.setCorePoolSize(5);// 设置最大线程数executor.setMaxPoolSize(20);//配置队列大小executor.setQueueCapacity(Integer.MAX_VALUE);// 设置线程活跃时间(秒)executor.setKeepAliveSeconds(60);// 设置默认线程名称executor.setThreadNamePrefix("码神之路博客项目");// 等待所有任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown(true);//执行初始化executor.initialize();return executor;}}
2.在方法上修饰 使用线程池 @Async(“taskExecutor”) 异步执行
@Async("taskExecutor")public void updateArticleViewCount(ArticleMapper articleMapper, Article article) {...}
拒绝策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务 。ThreadPoolExecutor.CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务。
2.5.5 MyBatis-Plus分页插件怎么做
1.定义一个配置类扫描mapper,里面new一个PaginationInnerInterceptor()
@Configuration@MapperScan("com.mszlu.blog.dao.mapper")public class MybatisPlusConfig {// 分页插件@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}}
2.ArticleMapper接口定义方法返回IPage,并在xml中写好SQL查询语句
IPage<Article> listArticle(Page<Article> page, // IPage是plus的一个分页的,会自动帮忙加入一个分页的拦截器// 注意是plus的Page Page是IPage的实现类Long categoryId,Long tagId,String year,String month);
<select id="listArticle" resultMap="articleMap">select * from ms_article<where>1 = 1<if test="categoryId != null">and category_id=#{categoryId}</if><if test="tagId != null">and id in (select article_id from ms_article_tag where tag_id=#{tagId})</if><if test="year != null and year.length>0 and month != null and month.length>0">and(from_unixtime(create_date/1000,'%Y') =#{year} and from_unixtime(create_date/1000,'%m') =#{month})</if></where>order by weight,create_date desc</select>
3.service层输入封装好的请求参数,调用方法实现
@Overridepublic Result listArticle(PageParams pageParams) {Page<Article> page = new Page<>(pageParams.getPage(), pageParams.getPageSize());IPage<Article> articleIPage = articleMapper.listArticle(page, // 注意是plus类的pagepageParams.getCategoryId(),pageParams.getTagId(),pageParams.getYear(),pageParams.getMonth());List<Article> records = articleIPage.getRecords();return Result.success(copyList(records, true, true));}
2.5.6 Spring Security权限认证
https://blog.csdn.net/weixin_44283682/article/details/114832599?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control
Spring Security提供了以下几个接口:
1.UserDetails接口,用于保存用户账号信息,我们使用时选择一个实现类User,传入用户账号和密码
2.UserDetailsService接口,实现了加载用户名称的方法(登录后会把username传到这,在这里调用自己写的查找用户的方法,找到对应username的密码),目的时为了获取用户信息,以便接下来的认证
3.Authentication类,可通过这个类的对象.getPrincipal得到当前的登录用户
1.导入相关依赖
2.创建一个SecurityConfig类,继承WebSecurityConfigurerAdapter,进行相关权限认证的配置,告诉Security哪些路径要拦截、哪些路径放行,其中.access自定义的service去实现权限认证
@Configuration // 要继承WebSecurityConfigurerAdapterpublic class SecurityConfig extends WebSecurityConfigurerAdapter {@Bean // 密码策略 用的是BCrypt加密策略 比MD5安全public BCryptPasswordEncoder bCryptPasswordEncoder(){return new BCryptPasswordEncoder();}// 使用public static void main(String[] args) {//加密策略 MD5 不安全 彩虹表 MD5 加盐String mszlu = new BCryptPasswordEncoder().encode("mszlu"); // 生成一个密码存到数据库中System.out.println(mszlu);}// 这个配置暂时忽略@Overridepublic void configure(WebSecurity web) throws Exception {super.configure(web);}// 在springboot里继承security 讲过这个配置文件@Overrideprotected void configure(HttpSecurity http) throws Exception {http.authorizeRequests() //开启登录认证// .antMatchers("/user/findAll").hasRole("admin") //访问接口需要admin的角色.antMatchers("/css/**").permitAll() // 放行各个目录,使得不需要登录有也可以访问.antMatchers("/img/**").permitAll().antMatchers("/js/**").permitAll().antMatchers("/plugins/**").permitAll().antMatchers("/admin/**").access("@authService.auth(request,authentication)") //自定义service 来去实现实时的权限认证// 注意这个/admin很关键,特地加的。这样以admin开头的路径才进行认证,就不会影响下面这些自定义登录的配置.antMatchers("/pages/**").authenticated() // authenticated()表示pages页面下的只要登录成功就可以正常访问.and().formLogin().loginPage("/login.html") //自定义的登录页面.loginProcessingUrl("/login") //登录处理接口 spring security提供的登陆页面,不用自己写,如果自己实现了这个接口就会换成对应的.usernameParameter("username") //定义登录时的用户名的key 默认为username.passwordParameter("password") //定义登录时的密码key,默认是password.defaultSuccessUrl("/pages/main.html") // 成功 跳转到main.html.failureUrl("/login.html").permitAll() //所有路径都通过、不拦截,更加前面配的路径决定,这是指和登录表单相关的接口 都通过 //实际了我前面配了access 这些都生效不了 所以加了一个admin 使他可以生效.and().logout() //退出登录配置.logoutUrl("/admin/logout") //退出登录接口 // 我修改了这里,本来是 /logout,但是通常登录了才会退出,所以有前面的admin.logoutSuccessUrl("/login.html").permitAll() //退出登录的接口放行 实际了我前面配了access 这些都生效不了 所以加了一个admin 使他可以生效.and().httpBasic() // 可以用postman访问.and().csrf().disable() //csrf关闭 如果自定义登录 需要关闭.headers().frameOptions().sameOrigin(); //支持iframe页面嵌套}}
3.实现authService的权限认证方法auth(HttpServletRequest request, Authentication authentication)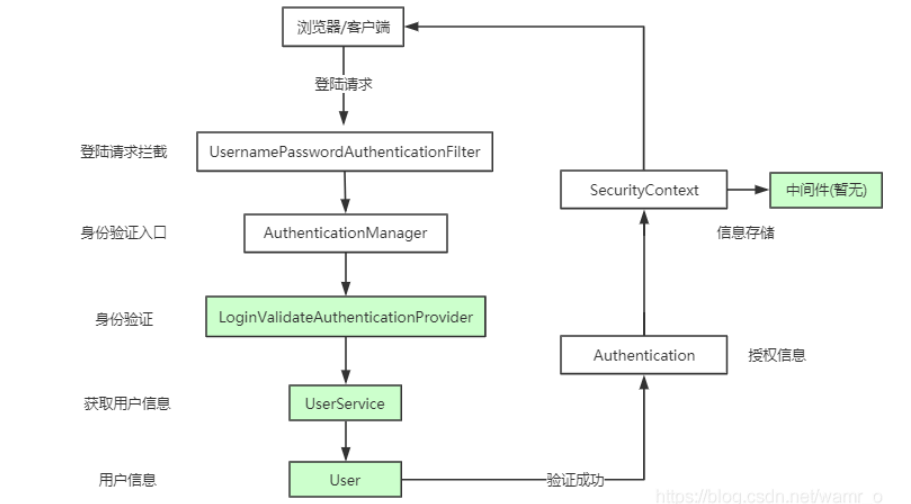
2.5.6 SpringSecurity的工作原理
Spring Securitry是用来实现安全访问控制的工具,通过一系列的过滤器,对所有请求进行拦截,完成配置的身份认证、权限认证。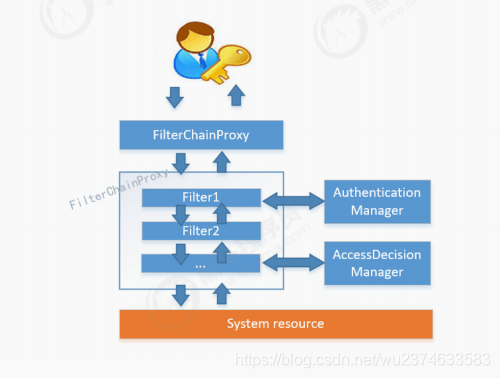
各个Filter作为Bean被Spring管理,它们是Spring Security核心,各有各的职责,但他们并不直接处理用户的认证,也不直接处理用户的授权,而是把它们交给了认证管理器(Authentication Manager)和决策管理器 (AccessDecision Manager)进行处理。
认证流程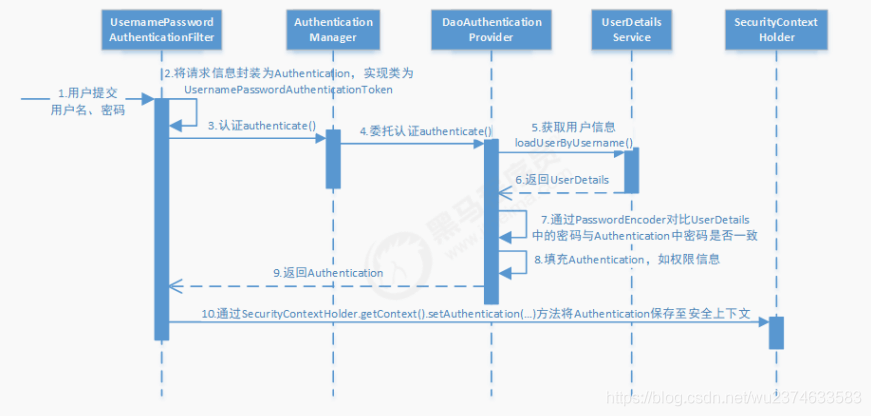
1.用户名密码认证过滤器 将表单提交的用户名密码等 封装(保存)成Authentication,然后交给 认证管理器 进行认证。
2.我们通过重写UserDetailsService接口中的通过用户名加载用户的方法,根据用户名去数据库中的表查询对应的密码,然后保存在Security提供的UserDteails 接口和实现类User中。
3.交给Security,根据对比UserDetails中的密码与Authentication中的密码是否一致,来判断登录认证是否成功。
4.成功的话,把数据库中的用户的权限信息填充到authentication中,为权限验证做准备。
授权过程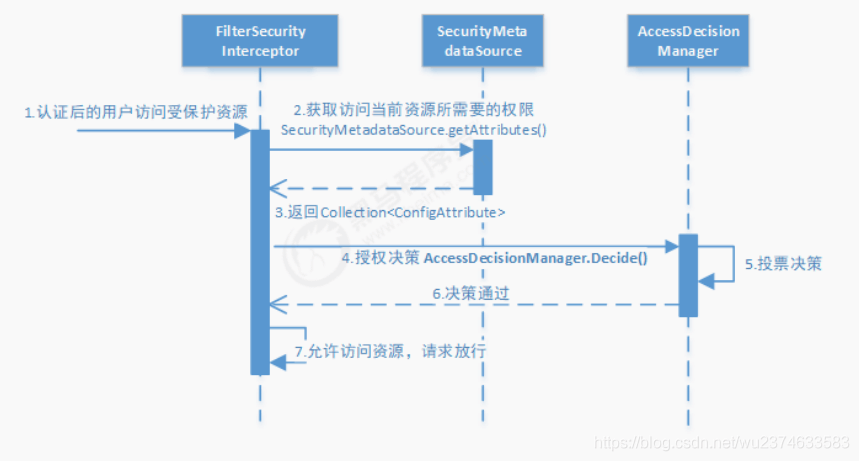
Spring Security可以通过 http.authorizeRequests() 对web请求进行授权保护。
通过对web请求进行拦截,获取访问当前资源所需权限。我是自定义了一个权限认证方法,通过比较数据表中路径和请求路径是否一致,并将方法添加到Security的配置中,交给Security中的 决策管理器 来授权,通过的话则允许访问。
通过Authentication类的对象的getPrincipal可以获得当前的登录用户,进行授权。
在权限和用户的关联表中,通过对应admin_id,找到对应的permission_id。
根据permission_id在permission表中查询path属性,与请求路径相比较,如果一致,则有权限操作。
3. 轮廓检测项目
这个轮廓检测项目是国家自然科学基金项目里的一个内容,做的是
4. Java集合
4.1 HashMap
4.1.1 HashMap中的put方法
1. 先判断散列表是否没有初始化或者为空,如果是就扩容2. 根据键值 key 的hashCode 计算 经过扰动函数处理过的 hash 值,通过 (n-1) & hash 得到要插入的数组索引3. 判断要插入的那个数组是否为空:1. 如果为空直接插入。2. 如果不为空,判断 key 的值是否是重复(用 equals 方法):1. 如果是就直接覆盖2. 如果不重复就再判断此节点是否已经是红黑树节点:1. 如果是红黑树节点就把新增节点放入树中2. 如果不是,就开始遍历链表:1. 发现有重复的值,覆盖2. 循环判断直到链表最底部,到达底部就插入节点,然后判断链表长度是否大于8:1. 如果大于8 且 当前数组长度大于等于64 就转换为红黑树2. 如果大于8 但 当前数组长度小于64 先数组扩容3. 如果不大于8就继续下一步4. 判断是否需要扩容,如果需要就扩容。(不重要:数组长度低于6则将红黑树转会链表)
4.1.2 HashMap中的get方法
// 判空情况1. 对输入的key值计算hash值2. 判断hashmap中的数组是否为空,数组的长度是否为0,如果为空和为0,则直接返回null// 判1个的情况3. 如果不为空和0,通过计算(n-1) & hash 得到对应的数组下标,判断对应位置上的第一个node是否满足条件,如果满足条件,直接返回4. 如果不满足条件,判断当前node是否是最后一个,如果是,说明不存在key,则返回null// 多个,需先判断红黑树在判断链表5. 如果不是最后一个,首先判断是否是红黑树,如果是红黑树,获取对应key的节点6. 如果不是红黑树,遍历链表,是否有满足条件的,如果有,直接返回,否则返回null
4.1.3 HashMap和HashTable
| HashMap | HashTable | |
|---|---|---|
| 线程安全 | 非 | 是,synchronized修饰 |
| 效率 | 高一点,但是被淘汰了 | |
| 对Null Key和Null Value的支持 | 可以有一个Null Key, 多个Null Value |
不允许Null Key和Value 会抛出NullPointException |
| 初始容量、每次扩容的大小 | 1.默认16,每次扩容成2倍 2.给定初始值,扩充为2的幂次方(通过tableSizeFor()方法) |
默认11,每次扩容为2n+1 |
| 底层数据结构 | 数组+链表+红黑树 |
4.1.4 红黑树
4.2 ArrayList和LinkedList
4.2.1 ArrayList和LinkedList的区别
都不同步,线程不安全
| ArrayList | LinkedList | |
|---|---|---|
| 内存 | 动态数组,连续内存 | 双向链表,分散存储 |
| 适合操作 | 查询:下标(随机)访问 | 插入和删除 |
| 插入时间复杂度 | 插入时间复杂度O(N) | 插入时间复杂度O(1) |
| 遍历 | 遍历for | 遍历使用功能iterator |
| 内存空间占用 | 结尾预留 | 每个元素消耗更多(前驱、后驱、数据) |
| 其他 | 尾插法+指定初始容量,可以提高性能 扩容机制:数组长度固定,超出就新建数组,然后拷贝数据 |
jdk1.6及之前双向循环链表,之后取消循环 |
ArrayList和Vector的区别
ArrayList:List的主要实现类,适用于频繁查找,线程不安全
Vector:List的古老实现类,线程安全
4.2.2 ArrayList的扩容机制
ensureCapacityInternal(确认内部容量)
ensureExplicitCapacity(判断是否扩容)
grow(扩容)
int newCapacity = oldCapacity + (oldCapacity >> 1); // jdk1.7及以后 旧+旧右移1位(右移=/2) 得到1.5倍扩容int newCapacity = (oldCapacity * 3)/2 + 1; // jdk1.6及以前 乘1.5+1
三种情况:
1. 当前数组由默认构造方法生成的空数组,初始容量为0
第一次调用add/addAll方法添加数据后才真正分配容量为10
此时,minCapacity=默认容量(10)
添加数据,判断数组长度是否已达最大容量,若达到,则扩容
数组容量 0->10->1.5倍扩容
2. 由自定义初始容量构造方法创建且指定初始容量不为0。
此时,minCapacity=自定义初始容量
0->自定义初始容量->1.5倍
注意:若指定初始容量为0,则minCapacity=1,
其数组容量0->1->2->3->4->1.5倍扩容,即前4次添加数据都只+1。
3. 扩容量(newCapacity)大于ArrayList定义的最大值后(2^31-9),会调用hugeCapacity进行判断。
选择题:
ArrayList list = new ArrayList(20);中的list扩充几次?
答:
指定数组大小的创建,直接分配其大小,扩容0次。
4.3 ConcurrentHashMap
5. JVM
5.1 运行时区域
6. 数据结构和算法
6.1 排序
6.1.1 快速排序
6.1.2 插入排序
6.1.3 堆排序
6.1.4 桶排序
6.2 动态规划
6.3 分治
7. 主流框架
7.1 Spring
7.11 AOP
7.12 IOC
7.13 循环依赖问题及解决
7.2 Spring MVC
7.2.1 Spring MVC 工作流程
7.2.2 Spring MVC 九大组件
7.3 Spring Boot
7.3.1 Spring Boot 自动装配原理
7.4 MyBatis-Plus
8. MySQL
8.1 事务
8.2 隔离级别
8.3 索引
8.4 锁
9. 计算机网络
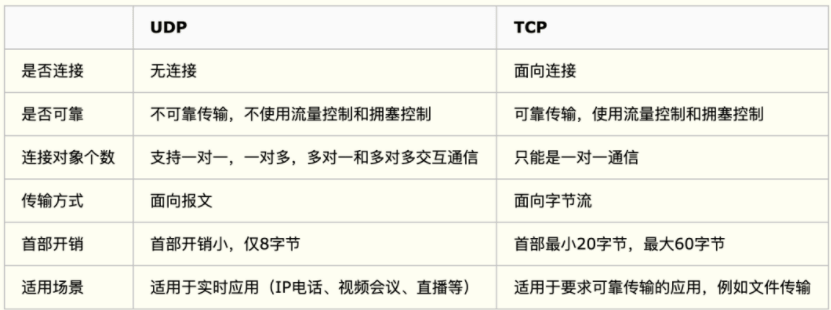
9.1 TCP和UDP
TCP:传输控制协议,提供面向连接的,可靠的数据传输服务
UDP:用户数据协议,提供无连接的,尽最大努力的数据传输服务(不保证可靠性)
总结:
TCP 向上层提供面向连接的可靠服务 ,UDP 向上层提供无连接不可靠服务。
UDP 没有 TCP 传输可靠,但是可以在实时性要求高的地方有所作为。
对数据准确性要求高,速度可以相对较慢的,可以选用TCP。
9.2 TCP的三次握手和四次挥手
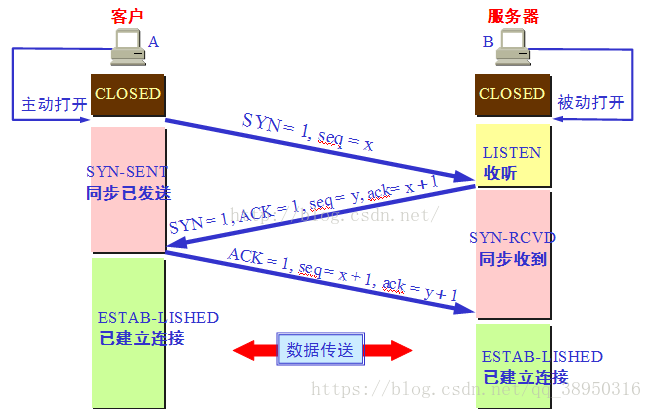
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
三次握手理解简记
客户端–发送带有 SYN 标志的数据包–⼀次握手–服务端
服务端–发送带有 SYN/ACK 标志的数据包–⼆次握手–客户端
客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
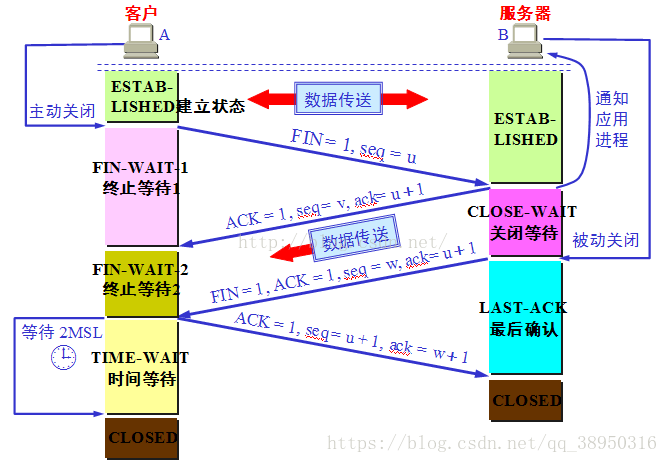
ack = 对面发来的seq序列号+1
seq = 自己发出的seq序列号+1
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
四次挥手理解简记
客户端-发送⼀个 FIN,⽤来关闭客户端到服务器的数据传送
服务器-收到这个 FIN,它发回⼀ 个 ACK,确认序号为收到的序号加1 。和 SYN ⼀样,⼀个 FIN 将占⽤⼀个序号
服务器-关闭与客户端的连接,发送⼀个FIN-ACK给客户端
客户端-发回 ACK 报⽂确认,并将确认序号设置为收到序号加1
9.3 Cookie和Session的区别
都是用来跟踪浏览器用户身份的会话方式,但应用场景不同
- 保存:session 保存在服务器端(默认被存储在服务器的一个文件里(不是内存)),cookie 在客户端(浏览器)
- session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
- session 可以放在 文件、数据库、或内存中都可以。
- 用户验证这种场合一般会用 session,安全性高(Cookie中不要存敏感信息,最好将Cookie信息加密然后使用的时候去服务端解密)
- Cookie一般用来保存用户信息,Session作用是通过服务端记录用户的状态
9.4 HTTP和HTTPS的区别
(1)HTTPS 协议需要到 CA 申请证书,一般免费证书较少,因而需要一定费用。
(2)安全性:HTTP 是超文本传输协议,信息是明文传输(客户端和服务端都无法验证对方身份),HTTPS 则是具有安全性的 SSL 加密传输协议。
(3)端口:HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
(4)加密:HTTP 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。(HTTPS传输内容采用对称加密,对称加密的密钥是非对称加密)
9.5 HTTPS的原理
https原理
https://zhuanlan.zhihu.com/p/43789231
对称加密的问题:服务端需要将公钥明文传送给客户端,会被中间人获取。
非对称加密(用两组公钥私钥保证两个传输方向上的安全性)的问题:速度慢。
HTTPS采用 非对称加密+对称加密:
1.服务端明文发送公钥A给客户端
2.客户端用公钥加密密钥X,发给服务端
3.服务端用私钥A’解密得到密钥X
4.之后用密钥X加解密信息通信
中间人攻击:如果中间人劫持了数据得到公钥A,然后用自己伪造的公钥B发送给客户端,客户端并不知道公钥被换了,就还是把密钥X用公钥B加密,发送给服务端,这样中间人就拿到了密钥X
所以关键在于:客户端要验证公钥是不是服务端发来的公钥 -> CA证书
为了避免明文传输服务端公钥被中间人掉包的情况,采用CA证书对公钥加密传输。中间人即使截获证书,得到里面的公钥,因为不能没有CA私钥不能再对其加密,所以无法掉包。同时,中间人也即是知道服务端公钥,也不能解密客户端用公钥加密的密钥X。
相关概念
签名:把原本的数据经 hash 得到 散列值,用CA私钥加密,得到签名,附加到数据后得到数字签名的数据的过程
验证:得到数字签名的数据后,对数据用 hash 得到散列值, 对签名用CA公钥解密, 比较二者是否一致,一致则数字签名有效
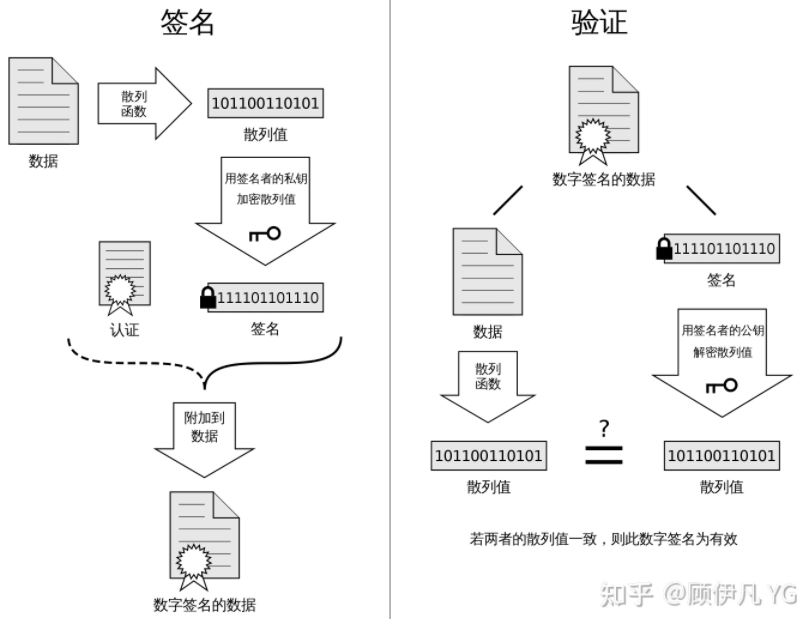
HTTPS原理简记
HTTPS采用了非对称加密+对称加密+CA证书的方式。
它使用非对称加密传输密钥,使用对称加密进行通信,通过CA证书的签名与验证来确保客户端收到的公钥来自于服务端。
其具体流程如下:
1.服务端申请证书:服务端向第三方公认机构CA提交申请,提供域名、申请者等信息,生成服务端的公钥和私钥(服务端的公钥作为明文传给客户端)
2.CA审核信息:CA通过线上线下多种手段验证信息真实性
3.签发证书(签名):信息审核通过,签发证书,证书包括:明文数据+签名。(明文包括:服务端公钥、签发机构CA的信息、有效时间、证书序列号等)
签名:明文数据 -> hash -> 信息摘要 -> CA私钥加密
4.发送证书:服务端将证书发送给客户端进行验证
5.客户端验证证书(验证):目的是为了保证公钥合法。
验证:1.明文数据 -> hash -> 信息摘要
2.签名 -> CA公钥解密(客户端预装了CA机构的公钥)
若 1 和 2得到的信息摘要一致,则证书合法,则可以放心使用明文中的服务端公钥
6.密钥协商:客户端随机生成密钥X,使用服务端公钥加密发给服务端,服务端使用私钥解密,得到密钥X,此后双方均使用密钥X对信息加解密,实现双方通信

若有收获,就点个赞吧
0 人点赞
