1. 哈希表
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
使用哈希查找有两个步骤:
1.使用哈希函数将被查找的键映射成数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况会发生哈希冲突:不同的键产生了相同的哈希值(被哈希到同一个索引值)。所以哈希查找的第二个步骤就是处理冲突
(由于键不一定是数字,还有可能是字符串或值的组合,通常需要自己实现(重写)哈希函数)
2.处理哈希碰撞冲突。有很多处理哈希碰撞冲突的方法,如拉链法和线性探测法
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
拉链法:通过哈希函数,我们可以将键转换为数组的索引,数组的每个元素指向一条链表,链表中的每个节点存储索引的键值对。
线性探测法:开放寻址法的一种,要求数组容量大于键值对,当发生哈希碰撞时,检查散列表的下一个位置是否被占用,没得话填入。
哈希退化:哈希函数选择不当,使得大量的键都映射到相同的索引,使哈希表的查找效率退化。
哈希碰撞攻击:HashTable在所有的Web应用框架上都有应用,我们对Web应用每次发起请求所提交的参数,服务器端都会将其存储在HashTable中供后台代码调用。 哈希表攻击就是通过精心构造哈希函数,使得所有的键经过哈希函数后都映射到同一个或者几个索引上,将哈希表退化为了一个单链表,这样哈希表的各种操作,比如插入,查找都从O(1)退化到了链表的查找操作,这样就会消耗大量的CPU资源,导致系统无法响应,从而达到拒绝服务供给(Denial of Service, Dos)的目的。
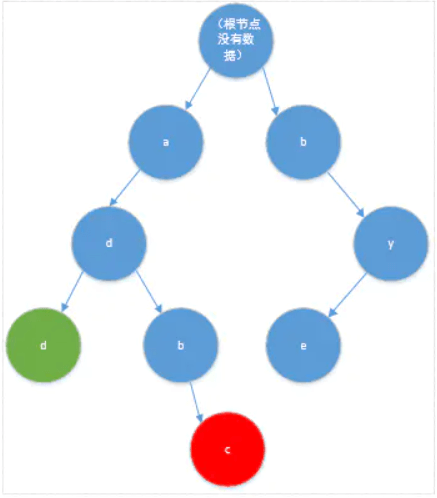
2. Trie树
addadbcbye
3. 红黑树
4. 平衡二叉树
5. 二分查找树

若有收获,就点个赞吧
0 人点赞
