参考:https://www.bookstack.cn/read/Cpp_Concurrency_In_Action/content-appendix_B-B.0-chinese.md
| 特性 | 启动线程 | 互斥量 | 监视/等待谓词 | 原子操作和并发感知内存模型 | 线程安全容器 | Futures(期望) | 线程池 | 线程中断 |
|---|---|---|---|---|---|---|---|---|
| 章节引用 | 第2章 | 第3章 | 第4章 | 第5章 | 第6章和第7章 | 第4章 | 第9章 | 第9章 |
| C++11 | std::thread和其成员函数 | std::mutex类和其成员函数 | std::condition_variable | std::atomic_xxx类型 | N/A | std::future<> | N/A | N/A |
| std::lock_guard<>模板 | std::condition_variable_any类和其成员函数 | std::atomic<>类模板 | std::shared_future<> | |||||
| std::unique_lock<>模板 | std::atomic_thread_fence()函数 | std::atomic_future<>类模板 | ||||||
| Boost线程库 | boost::thread类和成员函数 | boost::mutex类和其成员函数 | boost::condition_variable类和其成员函数 | N/A | N/A | boost::unique_future<>类模板 | N/A | boost::thread类的interrupt()成员函数 |
| boost::lock_guard<>类模板 | boost::condition_variable_any类和其成员函数 | boost::shared_future<>类模板 | ||||||
| boost::unique_lock<>类模板 | ||||||||
| POSIX C | pthread_t类型相关的API函数 | pthread_mutex_t类型相关的API函数 | pthread_cond_t类型相关的API函数 | N/A | N/A | N/A | N/A | pthread_cancel() |
| pthread_create() | pthread_mutex_lock() | pthread_cond_wait() | ||||||
| pthread_detach() | pthread_mutex_unlock() | pthread_cond_timed_wait() | ||||||
| pthread_join() | 等等 | 等等 | ||||||
| Java | java.lang.thread类 | synchronized块 | java.lang.Object类的wait()和notify()函数,用在内部synchronized块中 | java.util.concurrent.atomic包中的volatile类型变量 | java.util.concurrent包中的容器 | 与java.util.concurrent.future接口相关的类 | java.util.concurrent.ThreadPoolExecutor类 | java.lang.Thread类的interrupt()函数 |
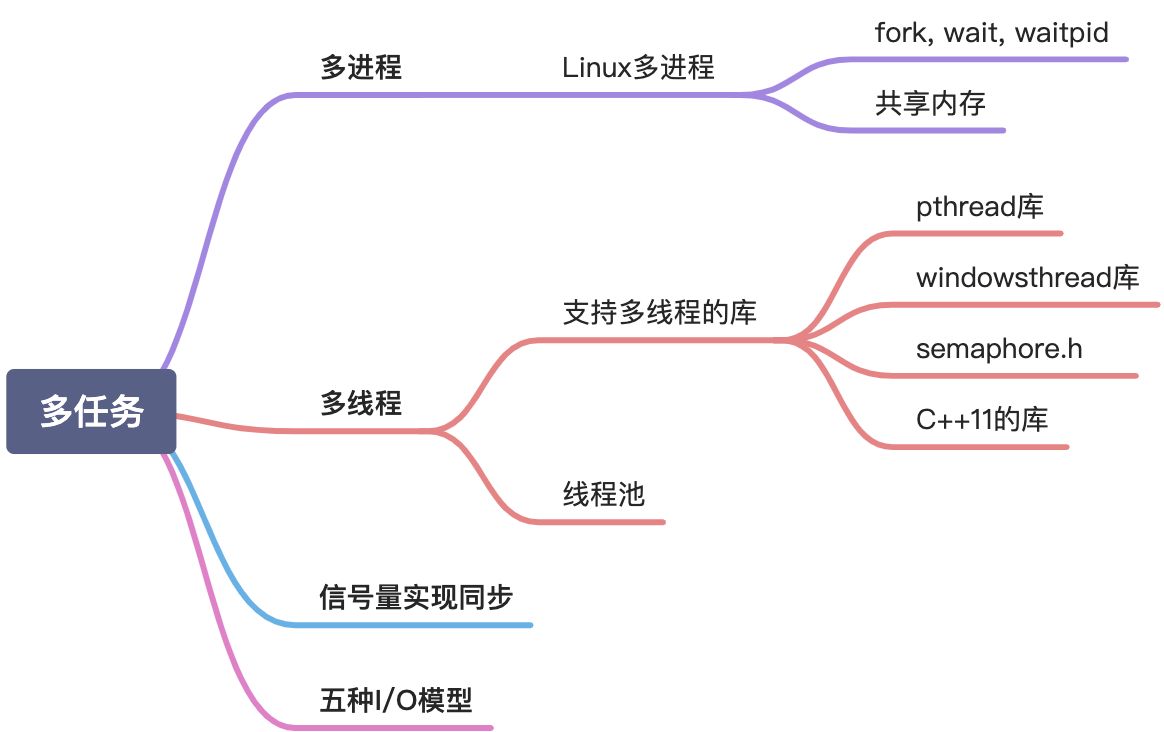
进程,线程,管程
线程间共享堆、全局变量、文件、栈指针?
Linux多进程,fork()
fork, wait,waitpid()
孤儿进程是没有父进程的进程,每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init(CentOS7 中是 systemd 进程,进程号为1),而 init 进程会循环地 wait() 它的已经退出的子进程。
任何一个子进程(init除外)在exit() 之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理,在ps列表里显示为Z。
父进程调用wait()或waitpid()阻塞自己等待子进程结束回收子进程。
如果父类不调用wait,子进程结束后一直是僵尸进程。
杀死父进程后所有子进程交给init保管,僵尸进程也会被init调用wait结束掉。
共享内存
mmap
将文件映射到内存中,多个进程共享文件,需要IO操作,速度慢。
shmget
多个进程共享一块物理内存。
- 创建/获取共享内存(shmget)
- 把共享内存连接到当前进程的地址空间(shmat)
- 通过指针访问共享内存。
- 将共享内存从当前进程中分离(shmdt)
- 删除共享内存(shmct)
IO密集型、计算密集型
线程任务可以分为CPU密集型和IO密集型。(平时开发基本上都是IO密集型任务)
CPU密集型任务的特点是进行大量的计算,消耗CPU资源,比如计算圆周率、视频高清解码等。这种任务操作都是比较耗时间的操作,任务越多花在任务切换的时间就越多,CPU执行任务效率就越低。所以,应当减少线程的数量,CPU密集型任务同时进行的数量应当等于CPU的核心数,上述我的电脑为8。
IO密集型的任务的特点是涉及到网络(调用三方接口)、磁盘IO(文件操作)等。这类任务操作是CPU消耗很少,任务大部分时间都在等待IO操作完成(IO的速度远低于CPU和内存的速度)。对于这种任务,任务越多,CPU效率越高,但是也有限度。我们开发接口时,像调别的应用接口,基本逻辑处理等,基本上都是属于IO密集型任务。C++11并发库
std::async与std::future
优先考虑基于任务的编程而非基于线程的编程。
std::thread API不能直接访问异步执行的结果,如果执行函数有异常抛出,程序会直接终止(通过调用std::terminate)。
基于线程的编程方式需要手动的线程耗尽、资源超额、负责均衡、平台适配性管理。
通过带有默认启动策略的std::async进行基于任务的编程方式会解决大部分问题。基于线程与基于任务最根本的区别在于,基于任务的抽象层次更高。
std::async返回一个std::future对象,future的get方法可以获取执行任务(函数)的返回值、获取执行中发生的异常。auto fut = std::async(doAsyncWork); //“fut”表示“future”

有了std::async,GUI线程中响应变慢仍然是个问题,因为调度器并不知道你的哪个线程有高响应要求。这种情况下,你会想通过向std::async传递std::launch::async启动策略来保证想运行函数在不同的线程上执行。
让人惊奇的是,std::async的默认启动策略——你不显式指定一个策略时它使用的那个——不是上面中任意一个。相反,是求或在一起的。下面的两种调用含义相同:
auto fut1 = std::async(f); //使用默认启动策略运行fauto fut2 = std::async(std::launch::async | std::launch::deferred, f); //使用async或者deferred运行f
默认策略允许f异步或者同步执行。如同Item35中指出,这种灵活性允许std::async和标准库的线程管理组件承担线程创建和销毁的责任,避免资源超额,以及平衡负载。但是,使用默认启动策略的std::async也有一些问题:
using namespace std::literals; //为了使用C++14中的时间段后缀;参见条款34void f() //f休眠1秒,然后返回{std::this_thread::sleep_for(1s);}auto fut = std::async(f); //异步运行f(理论上)while (fut.wait_for(100ms) != //循环,直到f完成运行时停止...std::future_status::ready) //但是有可能永远不会发生!{…}
如果f是延迟执行,fut.wait_for将总是返回std::future_status::deferred。这永远不等于std::future_status::ready,循环会永远执行下去。这种错误很容易在开发和单元测试中忽略,因为它可能在负载过高时才能显现出来。那些是使机器资源超额或者线程耗尽的条件,此时任务推迟执行才最有可能发生。毕竟,如果硬件没有资源耗尽,没有理由不安排任务并发执行。
封装一个真正的异步执行
C++11版本
template<typename F, typename... Ts>
inline
std::future<typename std::result_of<F(Ts...)>::type>
reallyAsync(F&& f, Ts&&... params) //返回异步调用f(params...)得来的future
{
return std::async(std::launch::async,
std::forward<F>(f),
std::forward<Ts>(params)...);
}
C++14版本,利用返回类型推断简化函数声明
template<typename F, typename... Ts>
inline auto reallyAsync(F&& f, Ts&&... params) // C++14
{
return std::async(std::launch::async,
std::forward<F>(f),
std::forward<Ts>(params)...);
}
std::future和std::shared_future
std::thread
std::thread不可以复制,只能通过std::move传递。
三种线程
- 硬件线程(hardware threads)是真实执行计算的线程。现代计算机体系结构为每个CPU核心提供一个或者多个硬件线程。
- 软件线程(software threads)(也被称为系统线程(OS threads、system threads))是操作系统(假设有一个操作系统。有些嵌入式系统没有。)管理的在硬件线程上执行的线程。通常可以存在比硬件线程更多数量的软件线程,因为当软件线程被阻塞的时候(比如 I/O、同步锁或者条件变量),操作系统可以调度其他未阻塞的软件线程执行提供吞吐量。软件线程的上下文切换会增加系统的软件线程管理开销,当软件线程安排到与上次时间片运行时不同的硬件线程上,这个开销会更高,因为cache的命中率会降低。
- std::thread 是C++执行过程的对象,并作为软件线程的句柄(handle),可以视作保存状态的对象,保存的状态可能也包括可调用对象,有没有具体的线程承载就是有没有连接。有些std::thread对象代表“空”句柄,即没有对应软件线程,因为它们处在默认构造状态(即没有函数要执行);有些被移动走(移动到的std::thread就作为这个软件线程的句柄);有些被join(它们要运行的函数已经运行完);有些被detach(它们和对应的软件线程之间的连接关系被打断)。
为了提供对底层系统级线程API的访问,std::thread对象提供了native_handle的成员函数。
创建线程
注意:如果调用类的成员函数,要传this指针(即实例的地址)
std::thread t1(function1, param1, param2, ...);
// 如果调用类的成员函数,要传this指针
class Foo{
void fist(...);
};
Foo foo;
std::thread t1(&Foo::first, &foo, ...);
join
thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。
join是阻塞当前线程,并等待object对应线程结束,该线程继续执行搜索
detach是将线程从当前线程分离出去,即不受阻塞,操作系统会将其独立对待。
在不可结合的std::thread上调用join或detach会导致未定义行为,join和detach之前必须检查joinable。
// 等待线程执行完毕,清除对象内部与具体线程相关的内存
// 当前对象将不再和任何线程相关联,只能调用一次.join()
if (t.joinable()) {
t.join();
}
detach
// 把线程放在后台运行,线程的所有权和控制权交给 C++ Runtime Library
// 该线程将与thread handle相互独立地执行
t1.detach();
joinable线程和unjoinable线程
每个std::thread对象处于两个状态之一:可结合的(joinable)或者不可结合的(unjoinable)。
可结合状态的std::thread对应于正在运行或者可能要运行的异步执行线程。比如,对应于一个阻塞的(blocked)或者等待调度的线程的std::thread是可结合的,对应于运行结束的线程的std::thread也可以认为是可结合的。C++禁止销毁一个可结合的线程,主线程退出前必须join或者detach子线程使它变成不可结合线程。为了安全起见,C++规定如果可结合的线程的析构函数被调用,整个程序执行都会终止。
不可结合的std::thread正如所期待:一个不是可结合状态的std::thread。不可结合的std::thread对象包括:
- 默认构造的std::threads。这种std::thread没有函数执行,因此没有对应到底层执行线程上。
- 已经被移动走的std::thread对象。移动的结果就是一个std::thread原来对应的执行线程现在对应于另一个std::thread。
- 已经被join的std::thread 。在join之后,std::thread不再对应于已经运行完了的执行线程。
- 已经被detach的std::thread 。detach断开了std::thread对象与执行线程之间的连接。
native_handle
获取原始handlestd::thread::get_id
获取线程std::thread对象控制的线程的线程号this_thread name space(当前线程)
std::this_thread::get_id
得到线程号
std::this_thread::get_id()
(std::thrad)t.get_id()std::this_thread::yield()
当前线程线程放弃执行,回到准备状态,重新分配cpu资源。所以调用该方法后,可能执行其他线程,也可能还是执行该线程std::this_thread::sleep_for()
当前线程睡眠一段时间std::this_thread::sleep_until
阻塞当前线程,一直到指定事件std::mutex
参考:https://leetcode-cn.com/problems/print-in-order/solution/c-hu-chi-suo-tiao-jian-bian-liang-xin-hao-liang-yi/
std::mutex对象不可复制,不可移动。
一个线程执行临界区代码时,另一个线程不能进入临界区(它们需要使用同一把锁)。
问题:一旦线程抛出异常,mu将会永远被锁住,改进:std::mutex mu; mu.lock(); // 临界区 mu.unlock();
std::lock_guard属于RAII对象,std::lock_guard对象的构造函数执行mu.lock(),被析构时自动执行mu.unlock()std::mutex mu; { std::lock_guard<std::mutex> guard(mu); // 临界区 }std::lock_guard, std::unique_lock, std::scoped_lock
lock_guard只有构造函数和析构函数,只提供最小程序的RAII
unique_lock封装了所有mutex的函数。并且允许延迟加锁、递归加锁、转移锁的所有权、与条件变量一起用。std::recursive_ mutex
若同一线程对非递归的互斥量多次加锁,可能会造成死锁。递归互斥量则无此风险。C++11中有递归互斥量的APl: std::recursive mutex。 对于pthread则可以通过给mutex添加PTHREAD MUTEX_ RECURSIVE 属性的方式来使用递归互斥量。
对递归锁的使用需要非常克制,仅当没有其他解决方案时才使用。std::shared_mutex
C++17引入了shared_mutex,可以实现读写锁std::condition_variable
参考:https://leetcode-cn.com/problems/print-in-order/solution/c-hu-chi-suo-tiao-jian-bian-liang-xin-hao-liang-yi/
使用条件变量(condition variable,简称condvar)。如果我们将检测条件的任务称为检测任务(detecting task),对条件作出反应的任务称为反应任务(reacting task),策略很简单:反应任务等待一个条件变量,检测任务在事件发生时改变条件变量。
与unique_lock一起使用
notify_all()方法尝试唤醒等待队列中的所有线程,notify_one()方法随机从等待队列中唤醒一个线程
wait()方法会检查是否满足唤醒条件,如果满足条件会执行unlock操作
class Foo {
std::condition_variable cv;
std::mutex mu;
int k = 0;
public:
Foo() {}
void first(std::function<void()> printFirst) {
printFirst();
k = 1;
cv.notify_all();
}
void second(std::function<void()> printSecond) {
std::unique_lock<std::mutex> guard(mu); // mu.lock()
cv.wait(guard, [this]() { return k == 1; }); // 阻塞当前线程,满足条件时会唤醒线程
printSecond();
k = 2;
cv.notify_one();
}
void third(std::function<void()> printThird) {
std::unique_lock<std::mutex> guard(mu); // mu.lock()
cv.wait(guard, [this]() { return k == 2; }); // 阻塞当前线程,满足条件时会唤醒线程
printThird();
k = 3;
}
};
Atomic operations library
std::atomic
std::atomic<int> ai(0); //初始化ai为0
ai = 10; //原子性地设置ai为10
std::cout << ai; //原子性地读取ai的值
++ai; //原子性地递增ai到11
--ai; //原子性地递减ai到10
对ai变量的读写是原子性的(汇编代码不会被打断),且不会发生C++代码行与行之间的reorder。
std::atomic类型没有拷贝操作,std::atomic不支持移动构造和移动赋值。
可以将x的值传递给y,但是需要使用std::atomic的load和store成员函数。load函数原子性地读取,store原子性地写入。要使用x初始化y,然后将x的值放入y,代码应该这样写:
std::atomic<int> y(x.load()); //读x
y.store(x.load()); //再次读x
std::atomic与volatile的比较:
std::atomic用在并发编程中,对访问特殊内存没用。
volatile用于访问特殊内存,对并发编程没用。
因为std::atomic和volatile用于不同的目的,所以可以结合起来使用。
std::memory_order
std::atomic_thread_fence
std::atomic_signal_fence
信号量(semaphore)
信号量(semaphore):表示系统中某种资源的数量
wait,signal(PV原语)
P0进程:
...
wait (S); // 进入区,申请资源
使用资源... // 临界区,使用资源
signal (S); // 退出区,释放资源
...
整形信号量:用一个整数表示资源数量,无法实现让权等待
记录型:结构体,整数表示资源数量,同时还有一个进程等待队列
信号量实现互斥
/*记录型信号的定义*/
typedef struct {
int value;
//剩余资源数
struct process *L; // 等待队列
} semaphore;
void wait(semaphore S){
S.value--;
if (S.value < 0){
block(S.L); // 阻塞进程,并且把进程加入等待队列
}
}
void signal(semaphore S){
S.value++;
if (S.value <= 0){
// S.value < 0 代表还有其他进程在等待资源,从队列中唤醒进程
wakeup(S.L);
}
}
信号量实现同步(前驱关系)


综合同步问题
生产者-消费者模型
读者写者问题

哲学家进餐问题
防止死锁的方案:
1. 限制只有n-1个哲学家同时进餐
2. 奇数号这哲学家先拿左边筷子,偶数号哲学家先拿右边筷子,保证相邻的两个哲学家先抢同一支筷子
3. 所有哲学家互斥地拿两支筷子(并发性能差)
管程(monitr)
管理一块内存区域使其他进程互斥访问此块区域的一个类。
semaphore.h
Pthread库
参考:
如何理解互斥锁、条件锁、读写锁以及自旋锁? - 果冻虾仁的回答 - 知乎
https://www.zhihu.com/question/66733477/answer/1267625567
https://zhuanlan.zhihu.com/p/58860015
https://www.jianshu.com/p/01ad36b91d39
mutex
//声明一个互斥量
pthread_mutex_t mtx;
//初始化
pthread_mutex_init(&mtx,NULL);
//加锁
pthread_mutex_lock(&mtx);
//解锁
pthread_mutex_unlock(&mtx);
//销毁
pthread_mutex_destroy(&mtx);
mutex是睡眠等待(sleep waiting)类型的锁,当线程抢互斥锁失败的时候,线程会陷入休眠。优点就是节省CPU资源,缺点就是休眠唤醒会消耗一点时间。另外自从Linux2.6版以后,mutex完全用futex的API实现了,内部系统调用的开销大大减小。值得一提的是,pthread的锁一般都有一个trylock的函数,比如对于互斥量:
ret=pthread_mutex_trylock(&mtx);
if(0==ret){//加锁成功
...
pthread_mutex_unlock(&mtx);
}else if(EBUSY==ret){//锁正在被使用;
pthread_mutex_trylock用于以非阻塞的模式来请求互斥量。就好比各种IO函数都有一个noblock的模式一样,对于加锁这件事也有类似的非阻塞模式。
conditional variable
解决问题:线程1对一个共享变量进行修改,当共享变量的值满足一定条件时线程2执行某种操作,如果单单用mutex对共享变量加锁,线程2需要不断地对变量加锁、解锁来检查变量是否满足条件,极大增加了操作系统的开销。
使用条件变量后,线程2在条件不满足时被阻塞,直到条件满足才被唤醒。
条件变量和互斥量必须一一对应。
//thread1 :
while(true)
{
pthread_mutex_lock(&mutex);
iCount++;
pthread_mutex_unlock(&mutex);
pthread_mutex_lock(&mutex);
if(iCount >= 100)
{
pthread_cond_signal(&cond);
}
pthread_mutex_unlock(&mutex);
}
//thread2:
while(1)
{
pthread_mutex_lock(&mutex);
while(iCount < 100)
{
pthread_cond_wait(&cond, &mutex);
}
printf("iCount >= 100\r\n");
iCount = 0;
pthread_mutex_unlock(&mutex);
}
Linux信号量函数
semget函数
semctl函数
semop函数
协程(coroutine)
在一个线程中并发执行多个任务,访问资源不需要互斥锁。
Python中用yield实现协程。
线程池
参考:https://zhuanlan.zhihu.com/p/73990200
核心线程:核心线程会一直存活
非核心线程:核心线程全部有事干且阻塞队列也满了,创建非核心线程,非核心线程干完活后如果没有新活干,经过keepAliveTime被销毁。
拒绝策略
AbortPolicy(抛出一个异常,默认的)
DiscardPolicy(直接丢弃任务)
DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
CallerRunsPolicy(交给线程池调用所在的线程进行处理)
线程池的工作队列
ArrayBlockingQueue
ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。
LinkedBlockingQueue
LinkedBlockingQueue(可设置容量队列)基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列
DelayQueue
DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue
PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列;
SynchronousQueue
SynchronousQueue(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,CachedThreadPool线程池使用了这个队列。
四种常见的线程池
SingleThreadPool
只有一条线程来执行任务,适用于有顺序的任务的应用场景。
ScheduleThreadPool
周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务,需要限制线程数量的场景。
CachedThreadPool
可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程。
适用于耗时少,任务量大的情况。用于并发执行大量短期的小任务。
FixedThreadPool
定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程。
FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
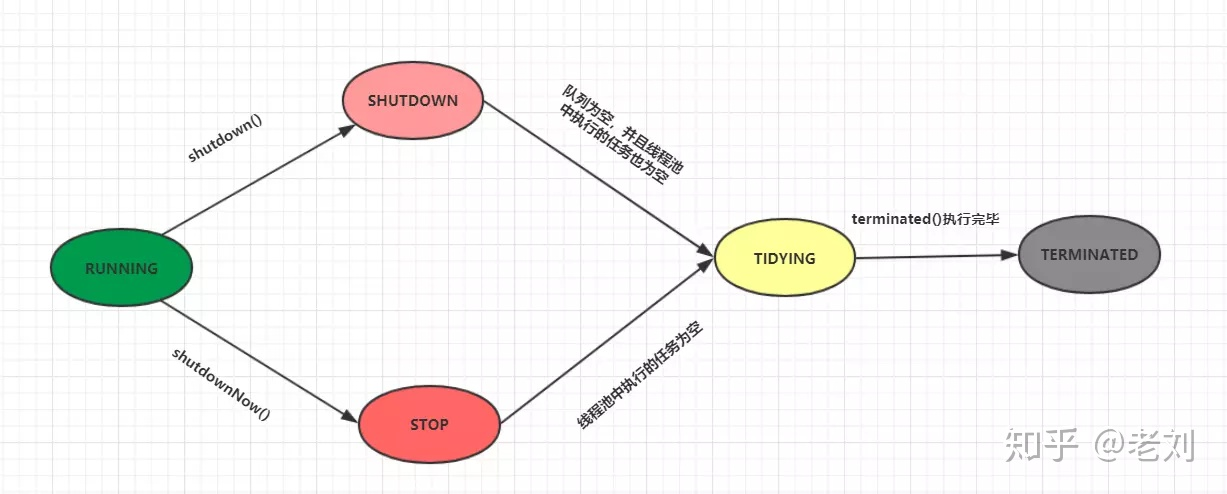
线程池的状态
RUNNING
- 该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- 调用线程池的shutdown()方法,可以切换到SHUTDOWN状态;
- 调用线程池的shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
- 该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
- 该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- 线程池中执行的任务为空,进入TIDYING状态;
TIDYING
- 该状态表明所有的任务已经运行终止,记录的任务数量为0。
- terminated()执行完毕,进入TERMINATED状态
TERMINATED
- 该状态表示线程池彻底终止
线程池核心线程数的选择
参考:https://blog.csdn.net/qq_41055045/article/details/115031661
线程任务可以分为CPU密集型和IO密集型。(平时开发基本上都是IO密集型任务)
CPU密集型任务的特点是进行大量的计算,消耗CPU资源,比如计算圆周率、视频高清解码等。这种任务操作都是比较耗时间的操作,任务越多花在任务切换的时间就越多,CPU执行任务效率就越低。所以,应当减少线程的数量,CPU密集型任务同时进行的数量应当等于CPU的核心数,上述我的电脑为8。
IO密集型的任务的特点是涉及到网络(调用三方接口)、磁盘IO(文件操作)等。这类任务操作是CPU消耗很少,任务大部分时间都在等待IO操作完成(IO的速度远低于CPU和内存的速度)。对于这种任务,任务越多,CPU效率越高,但是也有限度。我们开发接口时,像调别的应用接口,基本逻辑处理等,基本上都是属于IO密集型任务。
刚才提到了,CPU密集型尽量配置少的线程,核心线程配置:CPU核数。而IO线程池应配置多的线程,核心线程配置:CPU核数*2。这里IO密集型还有一种情况是线程易阻塞型的,需要计算阻塞系数,他是这么配置线程核心线程数的:CPU核数 / 1 – 阻塞系数(0.8~0.9之间)。
IO模型
参考:https://www.cyc2018.xyz/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80/Socket/Socket.html
阻塞式IO
应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
CPU利用率高,但是一个进程只能等待一个IO事件。
IO复用
仍然是阻塞式IO,但是一个进程可以等待很多个IO事件。
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
非阻塞式IO(轮询)
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
CPU利用率低。
信号驱动IO
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
异步IO
应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
select / poll / epoll
select
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
poll
select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
- select 会修改描述符,而 poll 不会;
- select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
select 和 poll 速度都比较慢,每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区。
epoll
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_ctl() 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件完成的描述符。
从上面的描述可以看出,epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
epoll 仅适用于 Linux OS。
epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
应用场景
- select 应用场景
select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select 可移植性更好,几乎被所有主流平台所支持。
poll 应用场景
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。epoll 应用场景
只需要运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。

若有收获,就点个赞吧
0 人点赞
