
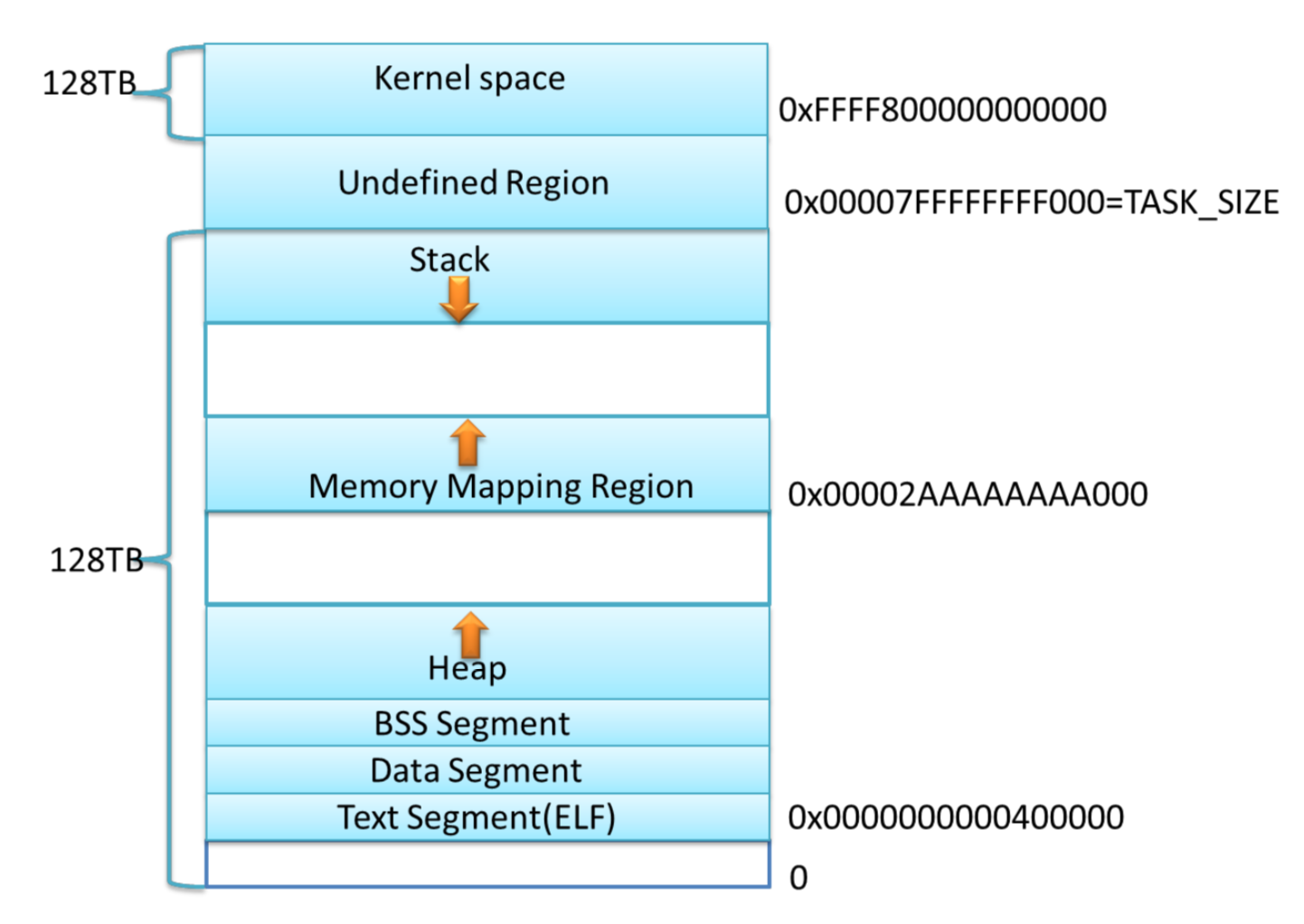
内存布局
参考:https://www.zhihu.com/question/36103513
这两张图看看就好,现在的实现情况已经不一样了。
Stack
如果被调用函数的栈帧比调用函数的在更低的地址,那么栈就是向下增长;反之则是向上增长。
x86硬件直接支持的栈确实是“向下增长”的:push指令导致sp自减一个slot,pop指令导致sp自增一个slot。其它硬件有其它硬件的情况。
Heap
Data段(只需要存全局、静态变量和常量,普通局部变量在堆栈上)
GOT表
BSS (Block Started by Symbol) (未初始化全局变量、静态变量)
存储未初始化或初始化为0的全局变量、静态变量,具体体现为一个占位符,并不给该段的数据分配空间,只是记录数据所需空间的大小
rodata段 (已初始化的常量段,禁止写入)
只存放常量数据。Linux/Unix的虚函数表存在这里。
例外:
- 有些立即数与指令编译在一起直接放在代码段
- 对于字符串常量,编译器会去掉重复的常量,让程序的每个字符串常量只有一份
- rodata是在多个进程间是共享的,这可以提高空间利用率。
- 用const修饰的全局变量是放入常量区的,但是使用const修饰的局部变量只是设置为只读起到防止修改的效果,没有放入常量区
- 用数组初始化的字符串常量是没有放入常量区的
data段 (已初始化的可读写全局变量、静态变量)
Windows的虚函数表存在这里。Text段
代码段动态装载库的运行时重定位机制
动态装载库 (so, dll) 装载到内存中的代码映射段,不可写入。程序调用动态链接库中的代码需要知道位置,动态库加载地址不确定。所以需要运行时重定位机制。
Windows:
IAT,导入地址表(Import Address Table)
IMAGE_DIRECTORY_ENTRY_IAT
Linux:
PLT(Procedure Linkage Table)程序链接表:获取函数实际地址的代码片段。
GOT(Global Offset Table)全局偏移表:存放实际函数地址,初始化为0。
Linux寻找动态库函数地址过程:代码段->PLT表->GOT表。
函数第一次调用时,才通过链接器动态解析并加载到.got.plt中,而这个过程称之为延时加载或者惰性加载。(elf对got做了细分:got存放全局变量引用的地址,got.plt存放函数引用的地址)C++对象的内存布局
见上一个文档“面向对象”智能指针
参考:https://blog.csdn.net/qq_28114615/article/details/101166744
https://blog.csdn.net/weixin_49199646/article/details/110004839
头文件
std::shared_ptr, std::unique_ptr, std::weak_ptr本身就是指针对象,声明时不用加。
std::shared_ptr可以用操作符和->操作符取指向的内容,C++17开始支持下标操作[]。
std::unique_ptr也可以用* 和 -> 操作,且支持下标操作[]。
std::weak_ptr不支持任何操作,只能返回shared_ptr再操作。#include <memory>shared_ptr<string> p1 = make_shared<string>("hello");p1.reset(new Person(3));
std::shared_ptr
https://www.cnblogs.com/jiayayao/p/6128877.html
不能用同一个指针来初始化多个std::shared_ptr,否则会造成重复释放(double free)。自定义释放规则
//指定 default_delete 作为释放规则 std::shared_ptr<int> p6(new int[10], std::default_delete<int[]>()); //自定义释放规则 void deleteInt(int*p) { delete []p; } //初始化智能指针,并自定义释放规则 std::shared_ptr<int> p7(new int[10], deleteInt);std::unique_ptr
unique_ptr 的基本特征:可移动,但不可复制。 “移动”将所有权转移到新 unique_ptr 并重置旧 unique_ptr。
注意:遍历unique_ptr的容器时通过引用来传参,否则将会由于尝试复制unique_ptr而报错// Create a new unique_ptr with a new object. auto song = make_unique<Song>(L"Mr. Children", L"Namonaki Uta"); // Use the unique_ptr. vector<wstring> titles = { song->title }; // Move raw pointer from one unique_ptr to another. unique_ptr<Song> song2 = std::move(song);// Create a unique_ptr to an array of 5 integers. auto p = make_unique<int[]>(5); // Initialize the array. for (int i = 0; i < 5; ++i) { p[i] = i; wcout << p[i] << endl; }std::weak_ptr
将一个weak_ptr绑定到一个shared_ptr不会改变shared_ptr的引用计数。不论是否有weak_ptr指向它,一旦最后一个指向对象的shared_ptr被销毁,对象就会被释放。从这个角度看,weak_ptr更像是shared_ptr的一个助手而不是智能指针。借助 weak_ptr 类型指针, 我们可以获取 shared_ptr 指针的一些状态信息,比如有多少指向相同的 shared_ptr 指针、shared_ptr 指针指向的堆内存是否已经被释放等等。
https://blog.csdn.net/Xiejingfa/article/details/50772571expired方法
判断所指对象是否已经被销毁。lock方法
如果对象存在,lock()函数返回一个指向共享对象的shared_ptr,否则返回一个空shared_ptr。智能指针指向数组
https://www.cnblogs.com/xiaojianliu/p/12704192.html
shared_ptr的数组智能指针,必须要自定义deleter。
智能指针源代码分析
_Ref_Count_base:计数器基类,直接管理资源
_Atomic_counter_t _Uses,引用计数
_Atomic_counter_t _Weaks,弱引用计数
virtual void _Destroy(),释放资源
virtual void _Delete_this(),销毁当前计数器对象
_Decref()函数,如果引用计数为0,释放资源,并调用_Decwref(),如果弱引用技术不为0,计数器仍然存在,可供weak_ptr查询是否过期
_Decwref()函数,如果弱引用计数为0,释放当前计数器
_Expired函数,检查强引用计数是否为0
_Ref_count:继承_Ref_Count_base
_Ptr:原生指针
_Ptr_base:智能指针基类
_Ptr:原生指针
_Ref_Count_base _Rep:计数器指针
_Reset函数:当前对象持有资源的引用计数减1,然后将传入对象的两个指针赋值给当前对象
_Resetw函数:对当前对象的弱引用计数减一,然后对传入对象的弱引用计数加1
shared_ptr
析构函数:减少持有资源的引用计数
reset函数:
*weak_ptr
析构函数:减少资源的弱引用次数
reset函数:
expired函数:检查强引用计数是否为0
内存分配与释放语法

new && delete
new会调用operator new,operator new调用malloc申请空间(不执行构造函数)
调用malloc和free,参数传sizeof(class_name)
会自动执行构造函数和析构函数
array new && array delete
new Class_A[10]在堆上申请10个Class_A大小的空间,调用10次构造函数,返回第一个对象的地址。
delete[]会依次调用每一个对象的析构函数,并释放10个Class_A大小的空间。
array new申请的空间,首部之前的内存空间会额外记录有多少个对象(下图中的3)。
// 不会出现内存泄露,因为int的析构函数本来就没有意义
int* p = new int[3];
delete[] p;
// 可能有内存泄露,只会调用其中一个A对象的析构函数
// 如果A的构造函数申请了其他空间,析构时需要释放,就存在内存泄露
class A {
int m_int;
public:
A(){}
};
int* p = new A[3];
delete[] p;
数组语法-内存分配在栈上
参考:原文链接:https://blog.csdn.net/qq_39383995/article/details/79763652
int p[3]
定义了一个名为p的数组,数组有三个整形元素,p指向第一个元素,是一个常量,不可以更改再赋值;
example:
int a[3]={1,2,3},p[3];
p=a;
编译会报错,因为p是一个指向一个数组的常量指针,不能再赋值
int (*p)[3]:
定义了一个名为p的指针变量,该指针指向一个三元素数组,p是一个指针变量,可以重新赋值;
example:
int a[3]={1,2,3},(*p)[3];
p=&a;
编译会通过,因为p是一个指针变量,可以再赋值
int *p[3]:
定义了一个名为p的数组,该数组有三个元素,每个元素都是一个指针,指针指向整形变量;
其他内存语法
placement new
operator new的一个重载
不会申请新的内存,用于在已经申请的空间上执行构造函数。
它的意义在于我们可以利用placement new将内存分配和构造这两个模块分离(后续的allocator更好地践行了这一概念),这对于编写内存管理的代码非常重要,比如当我们想要编写内存池的代码时,可以预申请一块内存,然后通过placement new申请对象,一方面可以避免频繁调用系统new/delete带来的开销,另一方面可以自己控制内存的分配和释放。
#include new>
char* buf = new char[sizeof (Complex) * 3];
Complex* pc = new (buf) Complex(1,2);
...
delete[] buf;
memset
memset(a, 0, 10 sizeof(int))
malloc 分配内存
calloc 分配内存,会将分配的内存清零
realloc 重新分配,如果新的大小比原来更大,会新申请一块空间并且将原空间的内存拷贝过去
char fgetc getc(FILE stream)
char fputc putc(int char, FILE stream)
int fseek(FILE stream, long offset, int fromwhere);
SEEK_SET:从距文件开头 offset 位移量为新的读写位置;
SEEK_CUR:以目前的读写位置往后增加 offset 个位移量;
SEEK_END:将读写位置指向文件尾后再增加 offset 个位移量。
内存管理模型
参考:https://blog.csdn.net/zju_fish1996/article/details/108858577
含freelist的分配器
空闲块形成链表。
隐式空闲链表
将空闲链表信息与内存块存储在一起。主要记录大小,已分配位等信息。
显式空闲链表
单独维护一块空间来记录所有空闲块信息。
池分配器模型
池分配器可以分配大量同尺寸的小块内存。它的空闲块也是由freelist管理的,但由于每个块的尺寸一致,它的操作复杂度更低,且也不存在内存碎片的问题。
buddy分配器
按照一分为二,二分为四的原则,直到分裂出一个满足大小的内存块;合并的时候看buddy是否空闲,如果是就合并。
可以通过位运算直接算出buddy,buddy的buddy,速度较快。但内存碎片较多。
含对齐的分配器
一般而言,对于通用分配器来说,都应当传回对齐的内存块,即根据对齐量,分配比请求多的对齐的内存。
堆栈分配器模型
双端堆栈分配器模型
可以从两端开始分配内存,分别用于处理不同的事务,能够更充分地利用内存。
碎片整理机制
当一个程序运行一定时间后,将会出现越来越多的内存碎片。一个优化的思路就是在引擎底层支持定期地整理内存碎片。
单帧分配器模型
双帧分配器模型
tcmalloc的内存分配
小于页的内存块分配
使用多个内存块定长的freelist进行内存分配,如:8,16,32……,对实际申请的内存向上“取整”。
freelist采用隐式存储的方式。
大于页的内存块分配
可以一次申请多个page,多个page构成一个span。同样的,我们使用多个定长的span链表来管理不同大小的span。
初始时只有 128 Page 的 Span,如果要分配 1 个 Page 的 Span,就把这个 Span 分裂成两个,1 + 127,把127再记录下来。对于 Span 的回收,需要考虑Span的合并问题,否则在分配回收多次之后,就只剩下很小的 Span 了,也就是带来了外部碎片 问题。
如何确定一个page属于哪个span
最简单的一种方式,用一个数组记录每个Page所属的 Span,而数组索引就是 Page ID。这种方式虽然简洁明了,但是在 Page 比较少的时候会有很大的空间浪费。
为此,我们可以使用 RadixTree 这种数据结构,用较少的空间开销,和不错的速度来完成这件事:
多线程环境的层级结构
每个线程都一个线程局部的 ThreadCache,按照不同的规格,维护了对象的链表;如果ThreadCache 的对象不够了,就从 CentralCache 进行批量分配;如果 CentralCache 依然没有,就从PageHeap申请Span;如果 PageHeap没有合适的 Page,就只能从操作系统申请了。
容器的访问局部性

若有收获,就点个赞吧
0 人点赞
