python环境配置
安装python3:brew install python3
安装pip:brew install pip,会弹出提示
安装crypto包:sudo pip install pycryptodome
升级pip3:pip3 install —upgrade pip
安装tensorflow sudo pip3 install tensorflow
pip安装包的位置 /usr/local/lib/python3.7/site-packages
/usr/local/lib/python2.7/site-packages
调试 https://www.cnblogs.com/rwxwsblog/p/4605309.html
ERROR: Cannot uninstall xxx. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall问题的解决方法:
sudo pip install xxx —upgrade —ignore-installed six
%08X 格式化输出8位长的数
成员运算符 in/not in
身份运算符is/is not
python and 相当于 C语言 &&
//是向下取整的除法
python and也是逻辑运算符,但是返回值不限于t/f,x and y if x is false, then x, else y。
10 and 20 = 20,10 or 20 = 10
(不要这么用!)
num = raw_input(“Enter a number :”)
逗号表达式的值为第n个子表达 式的值,即表达式n的值。
逗号表达式还可以用于函数调用中的参数。例如:
func(n,(j=1,j+4),k);
C++中,如果逗号表达式的最后一个表达式为左值,则该逗号表达式为左值。例如:
(a=1,b,c+1,d)=5; //ok:即d=5
while/if和C++是一样的,只用把()改成:
python for循环
for index in range(len(fruits)):
range返回一个序列的数 x~y range(x,y-1) 0~x-1 range(x)
del
序列包括字符串、列表、元组
字典——映射
文件操作
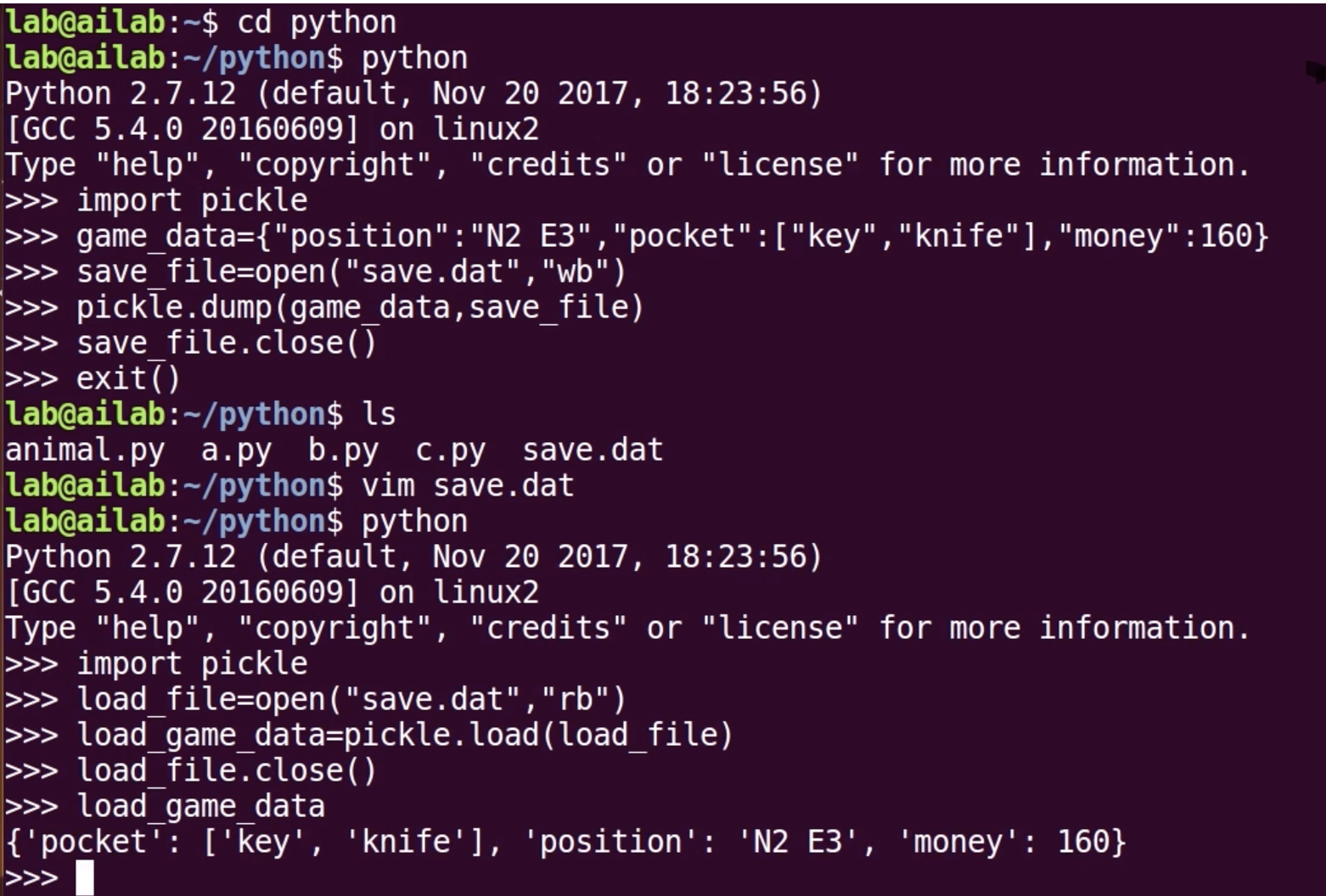
with——异常处理
https://blog.csdn.net/lxy210781/article/details/81176687
chr 返回整数对应的ascii字符
unichr 返回整数对应的unicode字符
ord 返回字符对应的整数
pyo文件,是python编译优化后的字节码文件。pyo文件在大小上,一般小于等于pyc文件。
生成pyo文件 python -O -m py_compile xxxx.py
sudo pip install uncompyle
umcompyle6 xxx.py
类型注解,指定返回值类型,typing包
https://www.cnblogs.com/xxpythonxx/p/12198876.html
def test(a:int, b:str) -> str:
自定义类型
from typing import List
Vector = List[float]
def scale(scalar: float, vector: Vector) -> Vector:
return [scalar * num for num in vector]
# typechecks; a list of floats qualifies as a Vector.
new_vector = scale(2.0, [1.0, -4.2, 5.4])
需要的头文件
from typing import List
from typing import Dict, Tuple, Sequence
泛型指定
from typing import Sequence, TypeVar, Union
T = TypeVar('T') # Declare type variable
def first(l: Sequence[T]) -> T: # Generic function
return l[0]
T = TypeVar('T') # Can be anything
A = TypeVar('A', str, bytes) # Must be str or bytes
A = Union[str, None] # Must be str or None
生成器
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator。
第二种方法,如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
面向对象

琐碎的常用操作
float(‘inf’)
float(‘-inf’)
flora(‘NaN’)
用format函数格式化输出
https://www.runoob.com/python/att-string-format.html
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss))
整数补0
print("%04d" % x) # 不够4位在前面补0
浮点数右对齐
print("{:>10.3f}\n{:>10.3f} ".format(x, y)) # 右对齐,占10位
<是左对齐,在右边补;>是右对齐,在左边补。
>10.3f代表右对齐,保留3位小数,小数点和数字一共占10位,不够在左边补”“,但是多了的话不会删除多余字符,而是全部显示出来
浮点数去除多余的0
print(('%f' % x).rstrip('0').rstrip('.'))
print("%.g" % 3.140)
输出时间
https://www.runoob.com/python/python-date-time.html
import time
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
time.localtime()返回一个元组:time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=3, tm_sec=27, tm_wday=3, tm_yday=98, tm_isdst=0)
strftime将元组转换成指定格式的字符串
#获取时间戳
ticks = time.time()
字典dict
初始化
dic = {'a':0, 5: "5", 1: 'b'}
list1 = ['a', 10, 'c']
dic = {element: i for i, element in enumerate(list1)}
dic = dict(zip(list1, range(len(list1))))
list1 = list(zip(list1, range(len(list1))))
# list1 = [('a', 0), (10, 1), ('c', 2)]
dic = zip(list1)
方法
dic.get('a',-1) # 取key 'a'对应的value,如果没有key 'a'则返回-1
dic.pop('a') # 删除key 'a'的那一项
遍历字典
for key in dic: # 遍历keys
for key in dic.keys(): # 和上面是一样的
for value in dic.values():
for item in dic.items():
for key, value in dic.items():
列表list
快速建立长度为n的列表
list1 = [None]*n
list2 = [[None] * n for _ in range(n)]
错误做法:list3 = [[None]_m]_n
因为列表*n生成的是对列表的n次引用,这n个列表实质是一个列表
遍历列表
for ele in list1:
用bool列表取列表值
l = [1,2,3,4]
index = [True, False, True, False]
[l[indexi] for indexi in index]
列表常用函数
list.append(obj)
list.count(obj)#统计某个元素在列表中出现的次数
list.extend(seq)#在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.index(obj)#从列表中找出某个值第一个匹配项的索引位置
list.insert(index, obj) #将对象插入列表的指定位置
list.pop([index=-1])#移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj)#移除列表中某个值的第一个匹配项
list.reverse()#反向列表中元素
list.sort(cmp=None, key=None, reverse=False)
ndarray特有切片和索引方式
用标签来筛选训练集,label_test和x_test是两个ndarray
x_test[label_test == i]也是一个ndarray
np.ndindex(shape)
给定要遍历的数组shape,生成索引,可以用于遍历数组
x = np.arange(32).reshape((8,4))
for index in np.ndindex(x.shape):
print(index, x[index])
np.take, np.take_along_axis
等效于numpy的“fancy index”,即直接方括号索引。
按指定的indices重排ndarray,比如argsort和argpartition返回的indices。
目前还不知道np.take和np.take_along_axis有什么区别
参考:https://numpy.org/doc/stable/reference/generated/numpy.take.html
A call such as np.take(arr, indices, axis=3) is equivalent to arr[:,:,:,indices,…].
>>> a = [4, 3, 5, 7, 6, 8]
>>> indices = [0, 1, 4]
>>> np.take(a, indices)
array([4, 3, 6])
In this example if a is an ndarray, “fancy” indexing can be used.
a = np.array(a)
>>> a[indices]
array([4, 3, 6])
If indices is not one dimensional, the output also has these dimensions.
np.take(a, [[0, 1], [2, 3]])
array([[4, 3],
[5, 7]])
如果ndarray是多维,需要指定axis,axis=None代表把数组flaten之后再操作,axis=-1(默认值)代表在最后一个维度上操作
np.take_along_axis(a, max_index, axis=None)
np.ix_
从多维数组中按指定的顺序切出部分维度的数据
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
''' output:
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
'''
main函数
集合
https://www.runoob.com/python3/python3-set.html
s = set([1,2,3])
s.add(x) #添加元素
s.update(x) #添加元素,可以是字典、列表、元组
s.remove(x) #如果x不在集合中会发生错误
s.discard(x) #即使x不在集合中也不会发生错误
s.clear()
isdisjoint() #判断两个集合是否包含相同的元素
union() #并集
intersection() #交集
交换a,b的值
a, b = b, a
字符串
像列表一样取一部分
s = "123456"
s[:-1] == "12345"
s = s[:-1] #删除最后一个字符

若有收获,就点个赞吧
0 人点赞
