消息模型
所谓消息模型,可以理解成一种逻辑结构,它是技术架构再往上的一层抽象,往往隐含了最核心的设计思想。
下面我们尝试分析下 Kafka 的消息模型,看看它究竟是如何演化来的?
广播模型
首先,为了将一份消息数据分发给多个消费者,并且每个消费者都能收到全量的消息,很自然的想到了广播。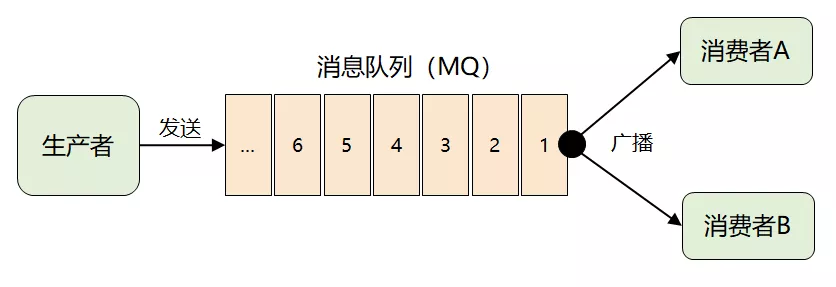
发布者按照TOPIC分类消息
紧接着问题将出现了:来一条消息,就广播给所有消费者,但并非每个消费者都想要全部的消息,比如消费者 A 只想要 消息 1、2、3,消费者 B 只想要 4、5、6,这时候怎么办呢?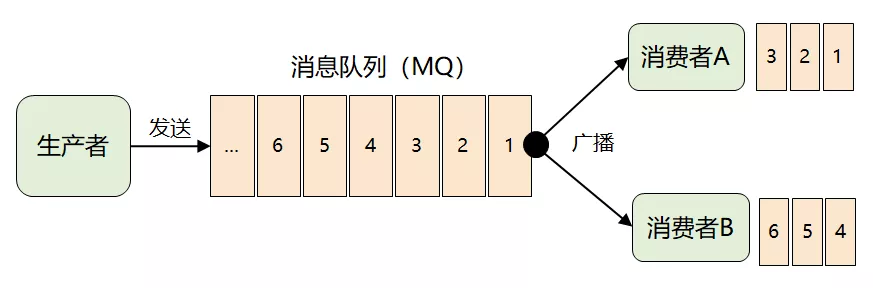
这个问题的关键点在于:MQ 不理解消息的语义,它根本无法做到对消息进行分类投递。
此时,MQ 想到了一个很聪明的办法:它将难题直接抛给了生产者,要求生产者在发送消息时,对消息进行逻辑上的分类,因此将演进出了我们熟知的 Topic 以及 发布-订阅模型。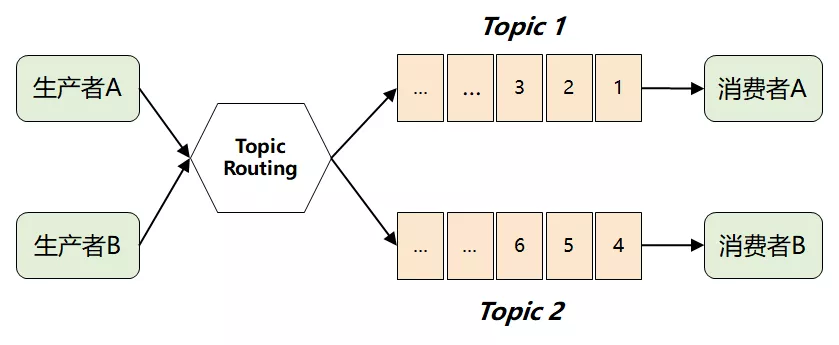
这样,消费者只需要订阅自己感兴趣的 Topic,然后从 Topic 中获取消息即可。
按照消费者分别存一份消息?
但是这样做了之后,仍然存在一个问题:假如多个消费者都对同一个 Topic 感兴趣(如下图中的消费者 C),那又如何解决呢?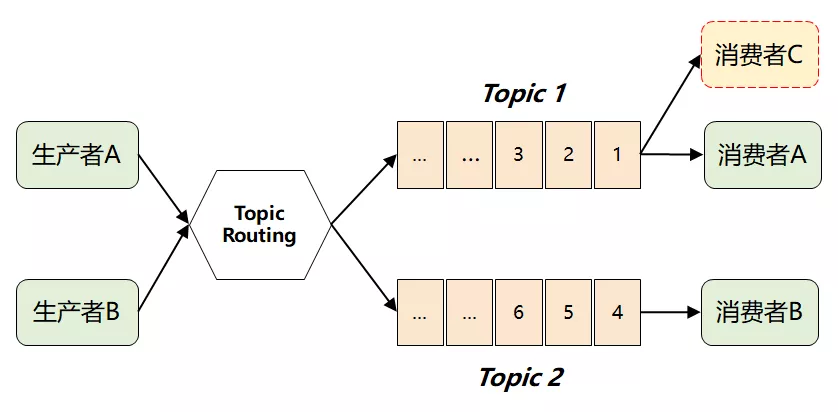
如果采用传统的队列模式(单播),那当一个消费者从队列中取走消息后,这条消息就会被删除,另外一个消费者将拿不到了。
这个时候,很自然又想到了下面的解决方案: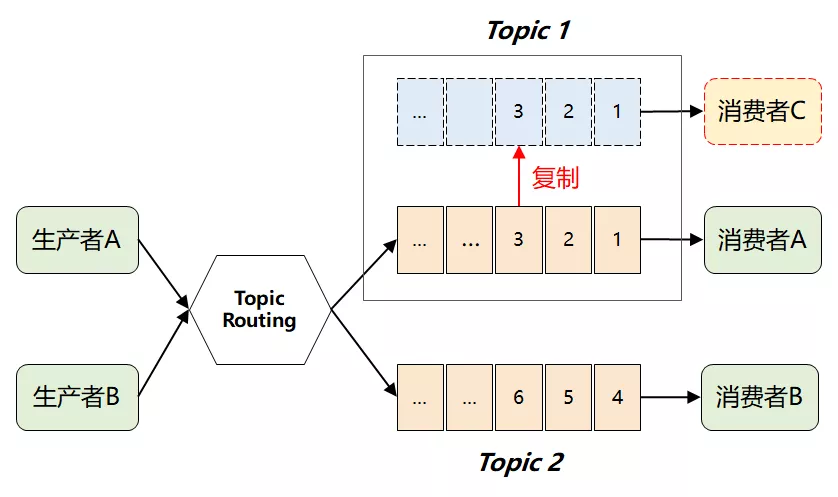
也就是:当 Topic 每增加一个新的消费者,就「复制」一个完全一样的数据队列。
这样问题是解决了,但是随着下游消费者数量变多,将引发 MQ 性能的快速退化。尤其对于 Kafka 来说,它在诞生之初就是处理大数据场景的,这种复制操作显然成本太高了。
每个消费者只要维护Offset就行
这时候,就有了 Kafka 最画龙点睛的一个解法:
它将所有的消息进行了持久化存储,由消费者自己各取所需,想去哪个消息,想什么时候取都行,只需要传递一个消息的 offset 即可。
这样一个根本性改变,彻底将复杂的消费问题又转嫁给消费者了,这样使得 Kafka 本身的复杂度大大降低,从而为它的高性能和高扩展打下了良好的基础。(这是 Kafka 不同于 ActiveMQ 和 RabbitMQ 最核心的地方)。
消息队列存储系统
最后,简化一下,就是这张图: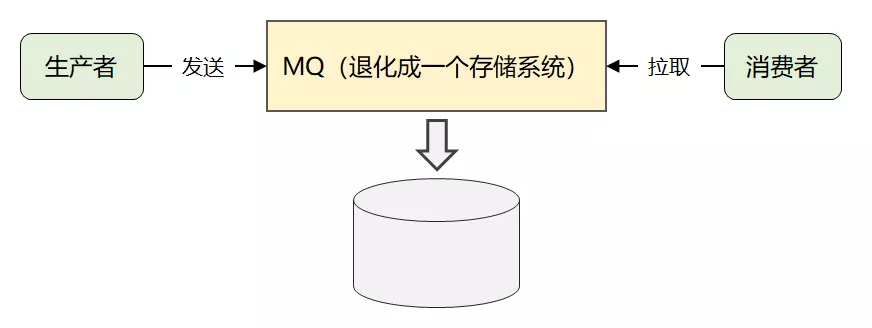
这就是 Kafka 最原始的消息模型。
这也间接的解释了:为什么官方会将 Kafka 同时定义成存储系统的原因。
架构设计
高容量&数据分区
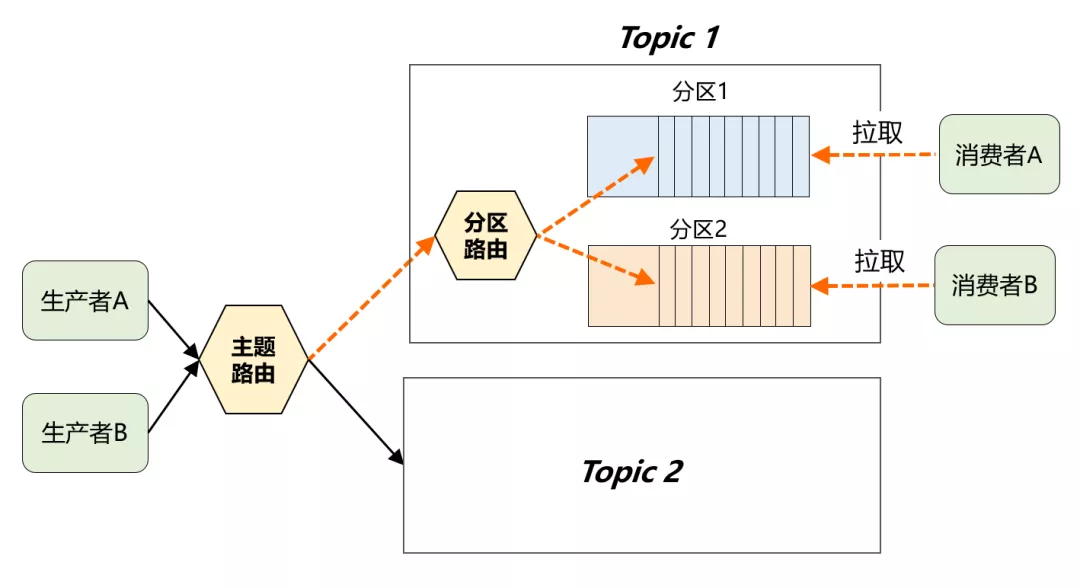
分区路由可以简单理解成一个 Hash 函数,生产者在发送消息时,完全可以自定义这个函数来决定分区规则。如果分区规则设定合理,所有消息将均匀地分配到不同的分区中。
通过这样两层关系,最终在 Topic 之下,就有了一个新的划分单位:Partition。先通过 Topic 对消息进行逻辑分类,然后通过 Partition 进一步做物理分片,最终多个 Partition 又会均匀地分布在集群中的每台机器上,从而很好地解决了存储的扩展性问题。
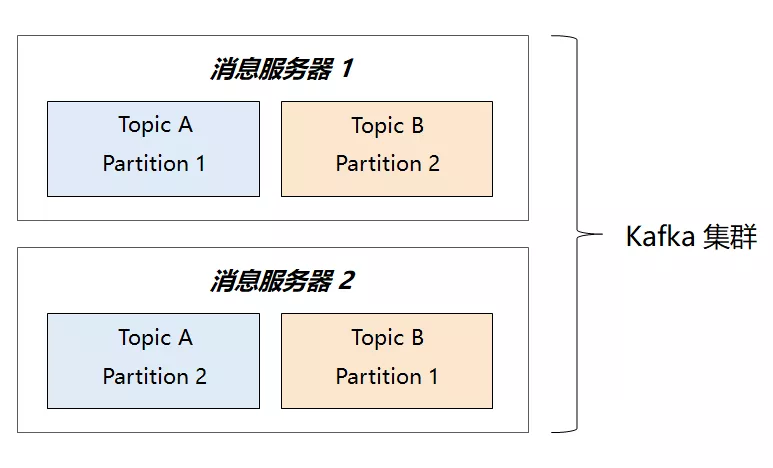
高并发&消费者
我们再看看消费端,它又是如何根 Partition 结合并做到并行处理的?
从消费者来看,首先要满足两个基本诉求:
- 广播消费能力:同一个 Topic 可以被多个消费者订阅,一条消息能够被消费多次。
- 集群消费能力:当消费者本身也是集群时,每一条消息只能分发给集群中的一个消费者进行处理。
为了满足这两点要求,Kafka 引出了消费组的概念
- 每个消费者都有一个对应的消费组,组间进行广播消费,组内进行集群消费。
- 此外,Kafka 还限定了:每个 Partition 只能由消费组中的一个消费者进行消费。
最终的消费关系如下图所示:
假设主题 A 共有 4 个分区,消费组 2 只有两个消费者,最终这两个消费组将平分整个负载,各自消费两个分区的消息。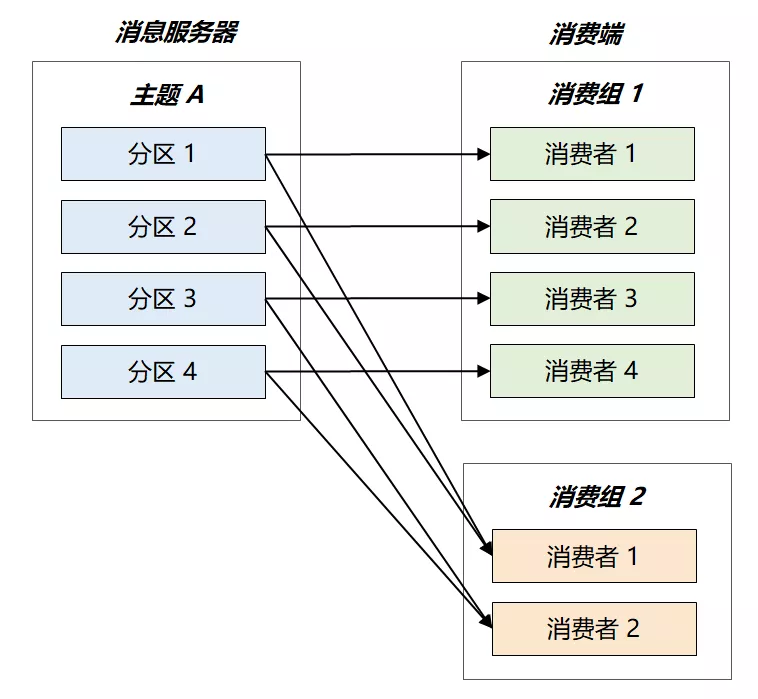
如果要加快消息的处理速度,该如何做呢?也很简单,向消费组 2 中增加新的消费者即可, Kafka 将以 Partition 为单位重新做负载均衡。当增加到 4 个消费者时,每个消费者仅需处理 1 个 Partition ,处理速度将提升两倍。
高可用&多副本机制
在 Kafka 集群中,每台机器都存储了一些 Partition ,一旦某台机器宕机,上面的数据不就丢失了吗?
此时,你一定会想到对消息进行持久化存储,但是持久化存储只能解决一部分问题,它只能确保机器重启后,历史数据不丢失。但在机器恢复之前,这部分数据将一直无法访问。这对于高并发系统来说,是无法忍受的。
所以 Kafka 必须具备故障转移能力才行,当某台集群宕机后仍然能保证服务可用。
如果大家去分析任何一个高可靠的分布式系统,比如 ElasticSearch、Redis Cluster,其实它们都有一套多副本冗余机制。
没错,Kafka 正是通过 Partition 的多副本机制解决了高可用问题。在 Kafka 集群中,每个 Partition 都有多个副本,同一分区的不同副本中保存的是相同的消息。
副本之间是“一主多从”的关系,其中 Leader 副本负责读写请求, follower 副本只负责和 leader 副本同步消息,当 leader 副本发生故障时,它才有机会被选举成新的 leader 副本并对外提供服务,否则一直是待命状态。
现在,我假设 Kafka 集群中有 4 台服务器,主题 A 和 主题 B 都有两个 Partition,且每个 Parttion 各有两个副本,那最终的多副本架构将如下所示: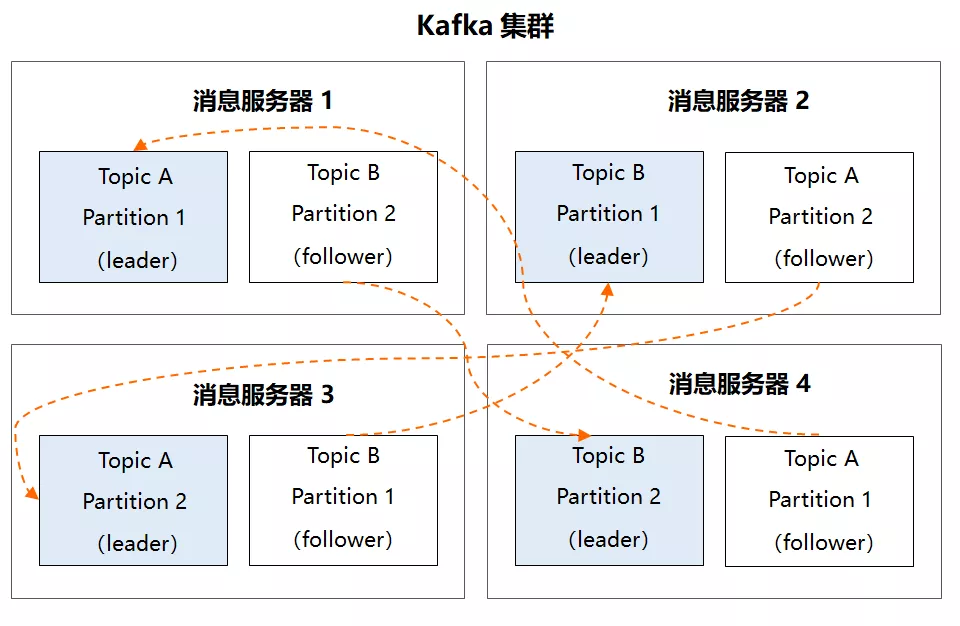
小结
理解了上面这些内容,最后我们再反过来看下 Kafka 的整体架构: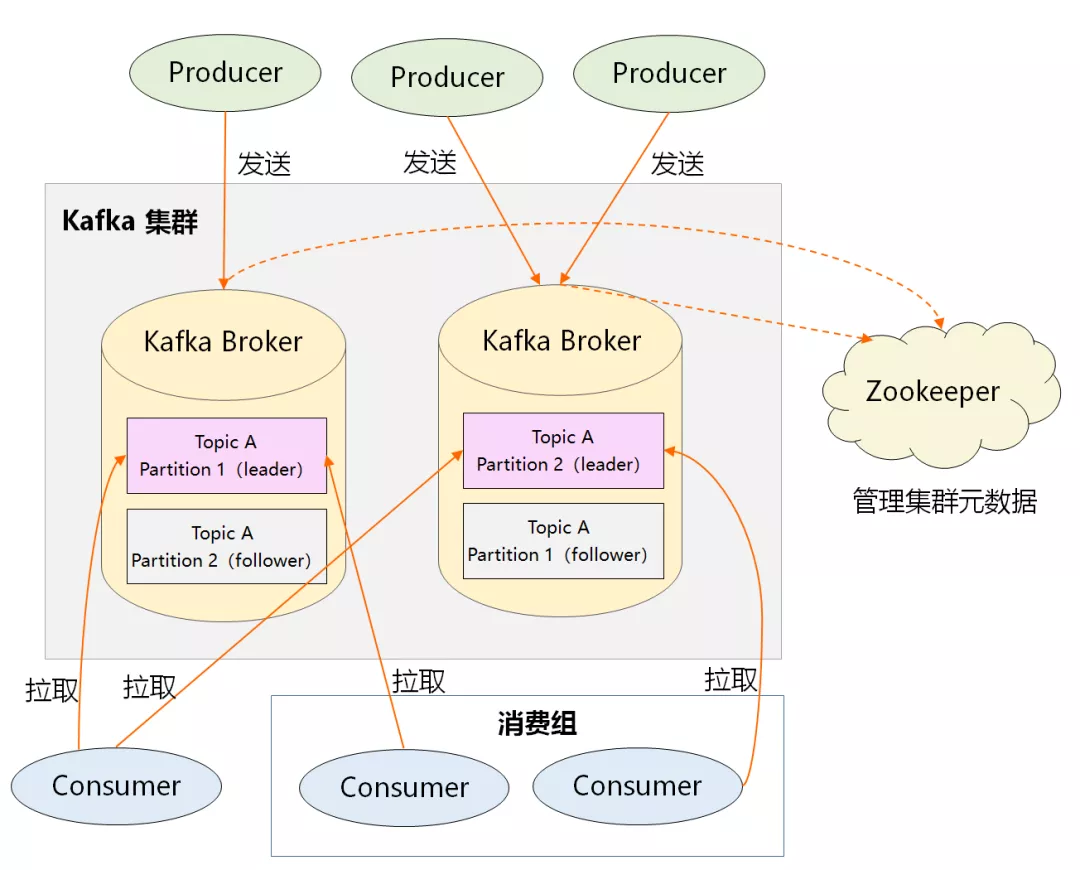
- Proudcer:生产者,负责创建消息,然后投递到 Kafka 集群中,投递时需要指定消息所属的 Topic,同时确定好发往哪个 Partition。
- Consumer:消费者,会根据它所订阅的 Topic 以及所属的消费组,决定从哪些 Partition 中拉取消息。
- Broker:消息服务器,可水平扩展,负责分区管理、消息的持久化、故障自动转移等。
- Zookeeper:负责集群的元数据管理等功能,比如集群中有哪些 broker 节点以及 Topic,每个 Topic 又有哪些 Partition 等。
很显然,在 Kafka 整体架构中,Partition 是发送消息、存储消息、消费消息的纽带。吃透了它,再去理解整体架构,脉络会更加清晰。
以 Partition 为切入点,从宏观角度解析了 Kafka 的整体架构,简单总结下以上内容:
1、Kafka 通过巧妙的模型设计,将自己退化成一个海量消息的存储系统。
2、为了解决存储的扩展性问题,Kafka 对数据进行了水平拆分,引出了 Partition(分区),这是 Kafka 部署的基本单元,同时也是 Kafka 并发处理的最小粒度。
3、对于一个高并发系统来说,还需要做到高可用,Kafka 通过 Partition 的多副本冗余机制进行故障转移,确保了高可靠。
存储选型
消息存储的需求
为什么说存储设计是 Kafka 的精华所在?之前做过分析,Kafka 通过简化消息模型,将自己退化成了一个海量消息的存储系统。
既然 Kafka 在其他功能特性上做了减法,必然会在存储上下功夫,做到 其它 MQ 无法企及的性能表现。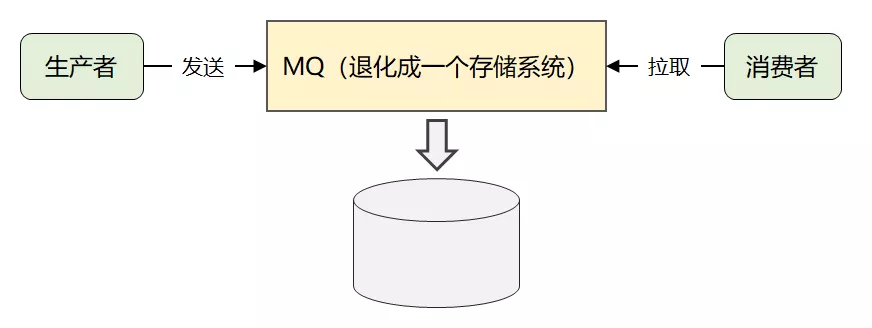
但是在 讲解 Kafka 的存储方案之前,我们有必要去尝试分析下: 为什么 Kafka 会采用 Logging(日志文件)的存储方式?它的选型依据到底是什么?
Kafka 的存储选型逻辑,我认为跟我们开发业务需求的思路类似,到底用 Mysql、Redis 还是其它存储方案?一定取决于具体的业务场景。
我们试着从以下两个维度来分析下:
- 功能性需求:存的是什么数据?量级如何?需要存多久?CRUD 场景都有哪些?
- 非功能性需求:性能和稳定性的要求是什么样的?是否需要考虑扩展性?
再回到 Kafka 来看,它的功能性需求至少包括以下几点:
- 存的数据主要是消息流:消息可以是最简单的文本字符串,也可以是自定义的复杂格式。但是对于 Broker 来说,它只需要处理好消息的投递即可,无需关注消息内容本身。
- 数据量级非常大:因为 Kafka 作为 Linkedin 的孵化项目诞生,用作实时日志流处理(运营活动中的埋点、运维监控指标等),按 Linkedin 当初的业务规模来看,每天要处理的消息量预计在千亿级规模。
- CRUD 场景足够简单:因为消息队列最核心的功能就是数据管道,它仅提供转储能力,因此 CRUD 操作确实很简单。
首先,消息等同于通知事件,都是追加写入的,根据无需考虑 update。其次,对于 Consumer 端来说,Broker 提供按 offset(消费位移)或者 timestamp(时间戳)查询消息的能力就行。再次,长时间未消费的消息(比如 7 天前的),Broker 做好定期删除即可。
我们再来看非功能性需求:
- 性能要求:之前说过,Linkedin 最初尝试过用 ActiveMQ 来解决数据传输问题,但是性能无法满足要求,然后才决定自研 Kafka。ActiveMQ 的单机吞吐量大约是 万级 TPS,Kafka 显然要比 ActiveMQ 的性能高一个量级才行。
- 稳定性要求:消息的持久化(确保机器重启后历史数据不丢失)、单台 Broker 宕机后如何快速故障转移继续对外提供服务,这两个能力也是 Kafka 必须要考虑的。
- 扩展性需求:Kafka 面对的是海量数据的存储问题,必然要考虑存储的扩展性。
简单总结,Kafka 存储的需求如下:
- 功能性需求:足够简单,追加写、无需 update、能够根据消费位移和时间戳查询消息、能定期删除过期的消息。
- 非功能性需求:是难点所在,因为 Kafka 本身就是一个高并发系统,必然会遇到典型的高性能、高可用、高扩展这三方面的挑战。
存储选型
有了上面的需求梳理,我们继续往下分析。
为什么 Kafka 最终会选用 logging(日志文件)来存储消息呢?而不是我们最常见的关系型数据库或者 key-value 数据库呢?
存储领域的基础知识
先普及几点存储领域的基础知识,这是我们进一步分析的理论依据。
- 内存的存取速度快,但是容量小、价格昂贵,不适用于长期保存的数据。
- 磁盘的存取速度相对较慢,但是廉价、而且可以持久化存储。
- 一次磁盘 IO 的耗时主要取决于:
- 寻道时间和盘片旋转时间,
- 提高磁盘 IO 性能最有效的方法就是:
- 减少随机 IO,增加顺序 IO。
- 一次磁盘 IO 的耗时主要取决于:
- 磁盘的 IO 速度其实不一定比内存满,取决于我们是如何使用它。
关于磁盘和内存的 IO 速度,有很多这方面的对比测试,结果表明:
- 磁盘顺序写入速度可以达到几百兆/s,
- 随机写入速度只有几百KB/s,
- 相差上千倍。此外,磁盘顺序 IO 访问甚至可以超过内存随机 IO 的性能。

再看数据存储领域,有两个“极端”发展方法:
- 加快读:通过索引(B+树、二分查找树等方式),提高查询速度,但是写入数据时要维护索引,因此会降低写入效率。
- 加快写:纯日志型,数据以 append 追加的方式顺序写入,不加索引,使得写入速度非常高(理论上可以接近磁盘的写入速度),但是缺乏索引支持,因此查询性能低。
基于这两个极端,又衍生出来了 3 类 最具代表性的底层索引结构:
- 哈希索引:通过哈希函数将 key 映射成数据的存储地址,适用于等值查询等简单场景,对于比较查询、范围查询等复杂场景无能为力。
- B/B+ Tree 索引:最常见的索引类型,重点考虑的是读新能,它是很多传统关系型数据库,比如 MySQL、Oracle 的底层结构。
- LSM Tree 索引:数据以 Append 方式追加写入日志文件,优化了写但是又没有显著降低读性能,众多 NoSQL 存储系统比如 BigTable,HBase,Cassandra,RocksDB 的底层结构。
Kafka 的存储选型考虑
有了上面这些理论基础,我们继续回到 Kafka 的存储需求上进行思考。
Kafka 所处业务场景的特点是:
- 写入操作:并发非常高,百万级 TPS,但都是顺序写入,无需考虑更新
- 查询操作:需求简单,能够按照 offset 或者 timestamp 查询消息即可
如果单纯满足 Kafka 百万级 TPS 的写入操作需求,采用 Append 追加写日志文件的方式 显然是最理想的,前面讲过磁盘顺序写的性能完全是可以满足要求的。
剩下的就是如何解决高效查询的问题。如果采用 B Tree 类的索引结构来实现,每次数据写入时都需要维护索引(属于随机 IO 操作),而且还会引来“页分裂”等比较耗时的操作。而这些代价对于仅需要实现简单查询要求的 Kafka 来说,显得非常重。所以,B Tree 类的索引并不适用于 Kafka。
相反,哈希索引看起来非常适合。为了加快读操作,如果只需要在内存中维护一个 「从 offset 到日志文件偏移量」的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。(根据 timestamp 查消息也可以采用同样的思路)
但是哈希索引常驻内存,显然没法处理数据量很大的情况,Kafka 每秒可能会有高达几百万的消息写入,一定会将内存撑爆。
可我们发现消息的 offset 完全可以设计成有序的(实际上是一个单调递增 long 类型的字段),这样消息在日志文件中本身就是有序存放的了,我们便没必要为每个消息建 hash 索引了,完全可以将消息划分成若干个 block,只索引每一个 block 第一条消息的 offset 即可,先根据大小关系找到 block ,然后在 block 中顺序搜索,这便是 Kafka “稀疏索引”的来源。
最终我们发现: Append 追加写日志 + 稀疏的哈希索引,形成了 Kafka 最终的存储方案。而这不就是 LSM Tree 的设计思想吗?
也许会有人反驳 Kafka 的方案跟 LSM Tree 不一样,并没有用到树型索引以及 Memtable 这一层。但我个人认为,从「设计思想」这个角度来看,完全可以将 Kafka 视为 LSM Tree 的极端应用。
此外,关于 Append Only Data Structures 和 LSM Tree ,推荐 Ben Stopford(Kafka 母公司的一位技术专家)于 2017 年 QCon 上做的一个视频分享,演讲非常精彩,值得一看。
https://www.infoq.com/presentations/lsm-append-data-structures/
落地设计
了解了 Kafka 存储选型的来龙去脉后,最后我们再看下它具体存储结构。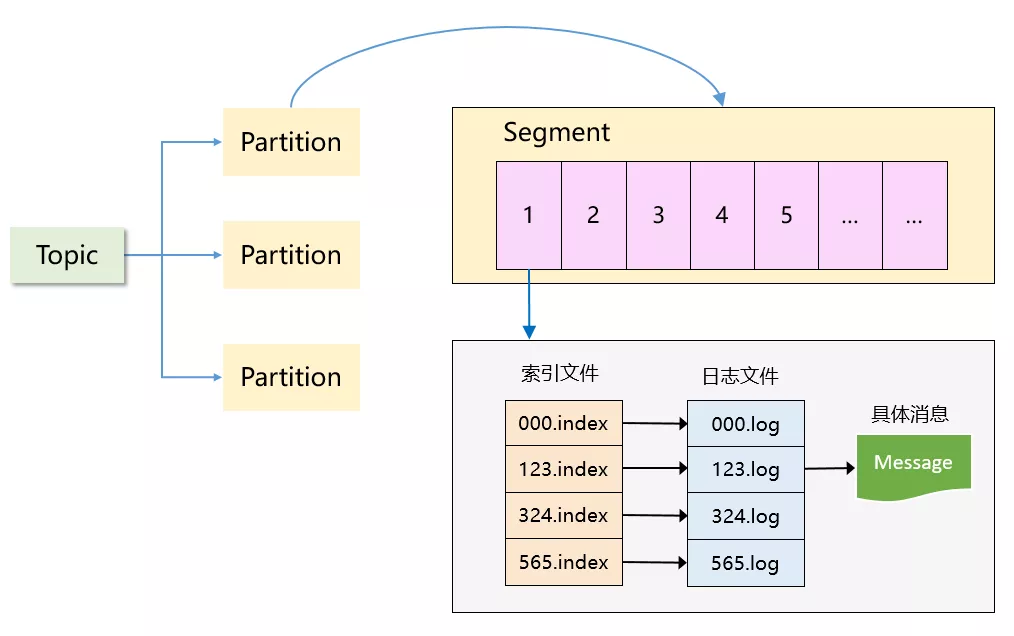
可以看到,Kafka 是一个 「分区 + 分段 + 索引」的三层结构:
- 每个 Topic 被分成多个 Partition,Partition 从物理上可以理解成一个文件夹。
- 之前解释过:Partition 主要是为了解决 Kafka 存储上的水平扩展问题,如果一个 Topic 的所有消息都只存在一个 Broker,这个 Broker 必然会成为瓶颈。因此,将 Topic 内的数据分成多个 Partition,然后分布到整个集群是很自然的设计方式。
- 每个 Partition 又被分成了多个 Segment,Segment 从物理上可以理解成一个 「数据文件 + 索引文件」,这两者是一一对应的。
一定会有疑问:有了 Partition 之后,为什么还需要 Segment?
如果不引入 Segment,一个 Partition 只对应一个文件,那这个文件会一直增大,势必造成单个 Partition 文件过大,查找和维护不方便。
此外,在做历史消息删除时,必然需要将文件前面的内容删除,不符合 Kafka 顺序写的思路。而在引入 Segment 后,则只需将旧的 Segment 文件删除即可,保证了每个 Segment 的顺序写。
小结
本节从需求分析、到选型对比、再到具体的存储方案,一步步拨开了 Kafka 选用 logging (日志文件)这一存储方案的奥秘。
也是希望大家能去主动思考 Kafka 在存储选型的难点,把它当做一个系统设计题去思考,而不仅仅记住了它用了日志存储。
另一个观点:越底层越通用,你每次多往下研究深一点,会发现这些知识在很多优秀的开源系统里都是相通的。

若有收获,就点个赞吧
0 人点赞
