1.pod的基本概念
最小部署单元<br /> 包含多个容器(一组容器的集合)<br /> 一个pod中容器共享网络命名空间<br /> pod是短暂的
2.pod存在意义
1)创建容器使用docker,一个docker对应一个容器,一个容器有进程,一个容器运行一个应用程序<br /> 2)pod是多进程设计,运行多个应用程序<br /> 一个pod可以有多个容器,一个容器里面运行一个应用程序<br /> 3)pod存在为了亲密性应用<br /> 两个应用之间进行交互<br /> 网络之间调用<br /> 两个应用需要频繁调用
3.pod实现机制
1)实现共享网络<br /> 通过pause容器,把其他业务容器加入到Pause容器里面,让所有业务容器在同一个名称空间中,可以实现网络共享<br /> 2)实现共享存储<br /> pod持久化数据:日志数据、业务数据<br /> 共享存储:引入数据卷Volume,使用数据卷进行持久化存储
spec: # 一个pod里面多个业务容器container- name: container1image: xxxcommand: xxxvolumeMounts: # 容器内挂载数据卷- name: datamountPath: /data- name: container2image: xxxcommand: xxxvolumeMounts:- name: datamountPath: /datavolumes: # 定义数据卷- name: dataemptyDir: {} # PV有多种方式,emptyDir,hostPath
4.pod镜像拉取
spec:containers:- name: nginximage: nginx:1.14imagePullPolicy: IfNotPresentIfNotPresent:默认值,镜像在宿主机上不存在时才拉取Always:每次创建pod都会重新拉取一次镜像Never: Pod永远不会主动拉取这个镜像
5.Pod资源限制
spce.containers[].resource.requests.cpu 最小资源<br /> spce.containers[].resource.requests.memory<br /> spce.containers[].resource.limits.cpu 最大资源<br /> spce.containers[].resource.limits.memory
6.Pod重启策略
spec.containers.restartPolicy<br /> Always:默认策略,当容器终止退出后,总是重启容器<br /> OnFailure:当容器异常退出(退出状态码非0)时,才重启容器<br /> Never:当容器终止退出,从不重启容器
7.Pod健康检查
livenessProbe:存活检查,如果检查失败,将杀死容器,根据Pod的restartPolicy策略来重启Pod<br /> readinessProbe:就绪检查,如果检查失败,k8s会把Pod从service中剔除,不接收外部流量<br /> startupProbe:效果跟livenessProbe一样的,不过配置参数多一些检查方式:<br /> exec:执行shell命令,返回状态码是0,则为成功<br /> httpGet:发送HTTP请求,返回200-400范围状态码为成功<br /> tcpSocket:发起TCP Socket建立成功
8.Pod的创建流程
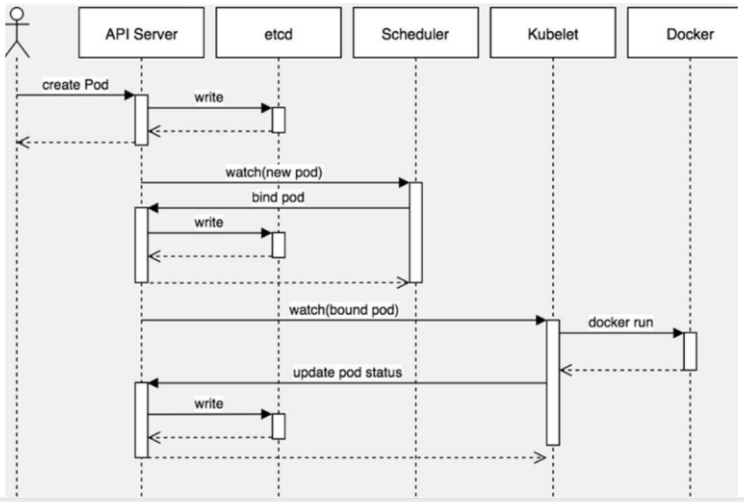 1. kubectl创建pod,kubectl会通知到apiserver,client create pod—api server
1. kubectl创建pod,kubectl会通知到apiserver,client create pod—api server
2. apiserver会将需要创建的新pod的信息记录到etcd中
3. scheduler监测到这个新pod还没有被调度,scheduler会选择一个合适的node将该node和新pod建立绑定关系 bind pod,再将绑定关系告知apiservice,apiserver会将该绑定关系存储到etcd中
4. kubectl与apiserver通信,kubectl监测到绑定的node上有新的pod信息,kubectl从apiserver那里得到新pod的信息,开始创建container runtime, docker run
5. kubectl创建成功容器后,把信息同步给apiserver,apiserver再将信息写入etcd中
9.Pod调度
1.Pod资源限制对Pod调用产生影响
resources.requests.cpu/memory
根据request找到足够资源的node节点进行调度
2.节点选择器标签影响Pod调度
根据不同的环境或不同业务调度到不同的node上,先把node打标签
kubectl label node node1 env_role=dev # 给node1节点打上”env_role=dev”标签
kubectl get nodes node1 —show-labels # 查看node1节点标签信息
然后yaml中设置节点选择器
spec:
nodeSelector:
env_role: dev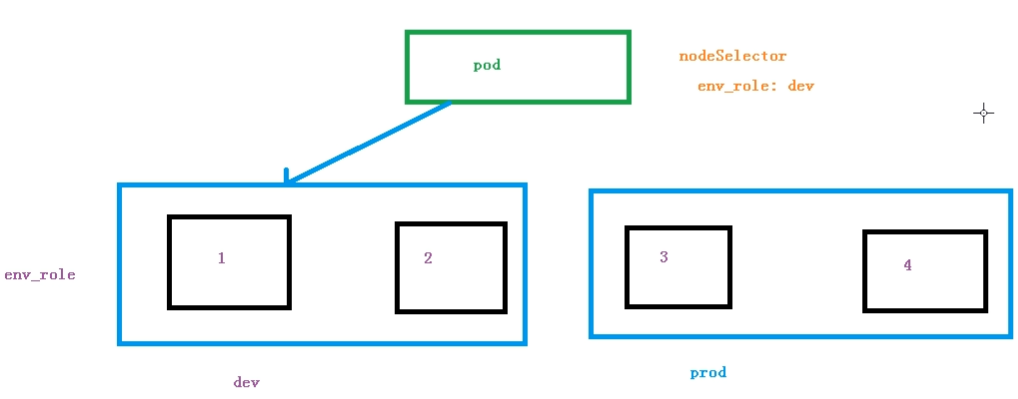 思考:生产环境要不要根据不同业务的pod部署到不同的node节点上,为什么?最近面试有面到这个
思考:生产环境要不要根据不同业务的pod部署到不同的node节点上,为什么?最近面试有面到这个
3.节点亲和性 nodeAffinity 和反亲和性
nodeAffinity和之前nodeSelector基本一样的,根据节点上标签约束来绝定Pod调度到哪些节点上
nodeAffinity分两类:硬亲和性、软亲和性
1)硬亲和性
约束条件必须满足
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
2)软亲和性
尝试满足,不保证一定满足
支持常用操作符:In NotIn Exists Gt Lt DoesNotExists
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
3)反亲和性操作跟亲和性设置相反
4.污点和污点容忍
1)基本介绍
nodeSelector和nodeAffinity:Pod调度到某些节点上,Pod属性,调度时候实现
Taint污点:节点不做普通分配调度,是节点属性
2)使用场景
专用节点;
配置特点硬件节点;
基于Taint驱逐
3)具体使用
污点值有三个:
NoSchedule: 一定不被调度
PreferNoSchdule: 尽量不被调度,有可能被调度,跟软亲和性差不多
NoExecute: 不会调度,并且还会驱逐Node已有Pod
kubectl describe node node1 | grep Taint # 查看node设置的污点
kubectl taint node [nodename] key=value:污点值 # 为node设置污点,设置污点node立即生效,不需要yaml中配置什么
kubectl taint node [nodename] key=value:污点值- # 删除node污点,即在后面加-
4)污点容忍
污点在node上设置后,node立即生效,不需要yaml中再配置
但还可以在yaml中配置tolerations,实现污点容忍,使得node有可能被调度到
spec:
tolerations:
- key: “key”
operator: “Equal”
value: “value”
effect: “NoSchedule”
containers:<br /> - name: web<br /> image: nginx
10.Pod Qos & Pod的驱逐策略
https://mp.weixin.qq.com/s/UGfBAPtAM0QQU1TmqTDxDg
Qos
Qos,即服务质量,有三种级别:
Guaranteed (保证的):cpu跟内存都设置了,并且相等
Burstable :cpu跟内存只设置了一个
BestEffort:cpu、内存都没有设置
驱逐顺序为:BestEffort、Burstable、Guaranteed
级别为Guaranteed:
Pod 中的每个容器必须指定内存限制和内存请求,且两者必须相等
Pod 中的每个容器必须指定 CPU 限制和 CPU 请求,且两者必须相等
例如:
resources:limits:cpu: 100mmemory: 10Mirequests:cpu: 100mmemory: 10Mi
级别为Burstable:
Pod 不符合 Guaranteed QoS 类标准
Pod 中至少一个有容器具备内存或 CPU 请求
例如:
resources:limits:cpu: 100mmemory: 10Mirequests:cpu: 100mmemory: 0
对于 QoS 类为 BestEffort 的 Pod,Pod 中的容器不得设置任何内存、CPU 限制或请求。
例如:
resources:limits:cpu: 0memory: 0requests:cpu: 0memory: 0
注:资源只是 Pod 是否能运行的一个检查项,QoS 类为 BestEffort 的 Pod 并不是始终可调度的。
kubectl软驱逐
除了从内核角度发生的驱逐之外,kubelet 也可以强制执行 Pod 驱逐,这是基于 kubelet 级别的阈值配置的。
Kubelet 可以主动监视并防止计算资源匮乏。当资源不足时,kubelet 可以通过主动使一个或多个 Pod 发生故障来回收其占用的资源。
当内存消耗超过内部配置的阈值时,Kubernetes 会强制重新启动 Pod。
[root@bastion ~]# cat mc.yalapiVersion: machineconfiguration.openshift.io/v1kind: KubeletConfigmetadata:name: test-resourcespec:machineConfigPoolSelector:matchLabels:custom-kubelet: resource-maxkubeletConfig:maxPods: 500kubeReserved: #为节点组件保留的资源。默认为 nonecpu: 1000mmemory: 2GisystemReserved: #为其余系统组件保留的资源。默认为 nonecpu: 500mmemory: 1GienforceNodeAllocatable:- podsevictionHard: #驱赶条件memory.available: "500Mi"nodefs.available: "10%"
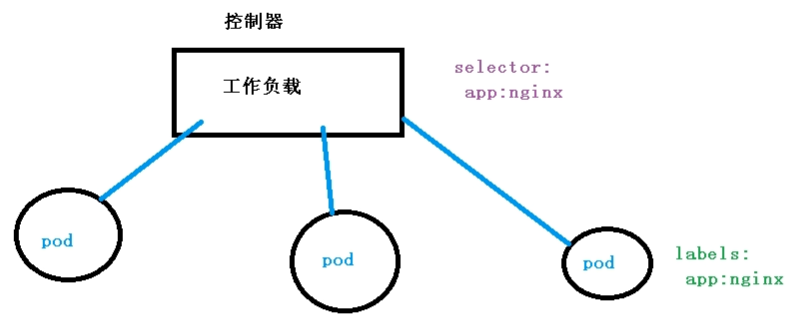
Pod和Controller关系
pod是通过Controller实现应用的运维,比如伸缩,滚动升级等
pod和controller是通过label标签和selector标签选择器建立关联的
selector:
app: nginx
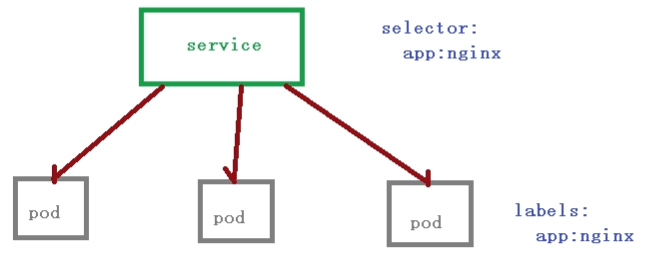
Pod和Service关系
service定义一组pod的访问规则
service存在的意义:
1)防止Pod失联 (服务发现)
pod之间的相互调用不能使用ip访问,因为pod的ip是不固定的,可以使用servicename访问
CoreDNS 把servicename和service-ip关联起来
2)定义一组Pod访问策略(负载均衡)
pod和controller是通过label标签和selector标签选择器建立关联的
selector:
app: nginx
labels:
app: nginx

若有收获,就点个赞吧
0 人点赞
