介绍
grep:文本过滤的, egrep
sed:流编辑器,实现编辑的
awk:文本报告生成器,实现格式化文本输出
概念
AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言的最大功能取决于一个人所拥有的知识。awk命名:Alfred Aho Peter\ Weinberger和brian kernighan三个人的姓的缩写。
awk——->gawk GUN AWK,linux上常用的是gawk,awk是gawk的链接文件
查看版本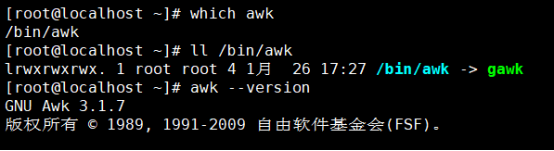
查看帮助:man gawk
AWK的文本处理流程: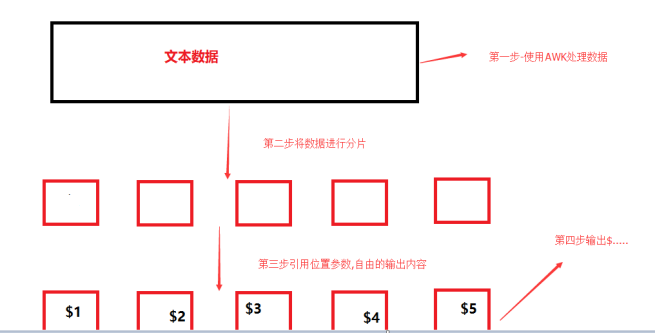
awk将文本逐行的读入,不直接对文本处理,先分片,(默认以空格分隔)
输出结果,在内部实现位置参数的引用, 自由处理某个段落.
awk基本应用
awk是列提取命令 (行操作:每次加载处理一行的信息,完事后继续下一行)
任何awk语句都是由模式(条件)组成,一个awk脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
模式:
正则表达式: /root/ 匹配含有root的行 /.root/
关系表达式:< <= > >= && || +
匹配表达式: ~ !~ ==
动作:
变量 命令 内置函数 流程控制语句
它的语法结构如下:
awk [options] ‘BEGIN{ print “start” } ‘pattern{ commands }’ END{ print “end” }’ file
其中:BEGIN END是AWK的关键字部,因此必须大写;这两个部分开始块和结束块是可选的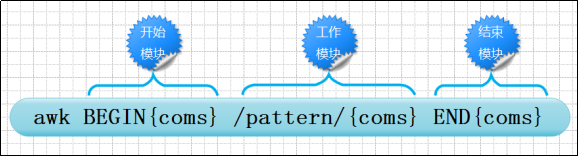
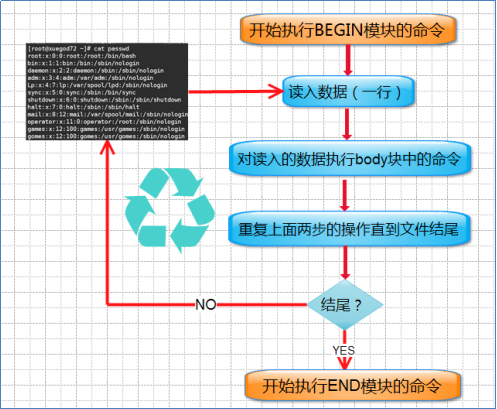
通过上面我们可以知道;AWK它工作通过三个步骤
1、读:从文件、管道或标准输入中读入一行然后把它存放到内存中
2、执行:对每一行数据,根据AWK命令按顺序执行。默认情况是处理每一行数据,也可以指定模式
3、重复:一直重复上述两个过程直到文件结束
GAWK支持两种不同类型的变量:内建变量,自定义变量
awk内置变量(预定义变量)
ü $n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段
ü $0 这个变量包含执行过程中当前行的文本内容
ü FILENAME 当前输入文件的名
ü FS 字段分隔符(默认是任何空格)
ü NF 表示字段数,在执行过程中对应于当前的字段数
ü FNR 各文件分别计数的行号
ü NR 表示记录数,在执行过程中对应于当前的行号
ü OFS 输出字段分隔符(默认值是一个空格)
ü ORS 输出记录分隔符(默认值是一个换行符)
ü RS 记录分隔符(默认是一个换行符)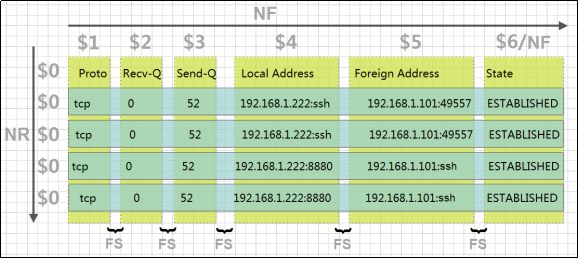
实例演示
常用的命令选项:
-F fs指定分隔符
-v 赋值一个用户自定义变量
-f 指定脚本文件,从脚本中读取awk命令
(1)分隔符的使用
用法:-F fs 其中fs是指定输入分隔符,fs可以是字符串或正则表达式
常见写法:-F: -F, -F[Aa]
分隔符默认是空格:-F “ “
指定一个分隔符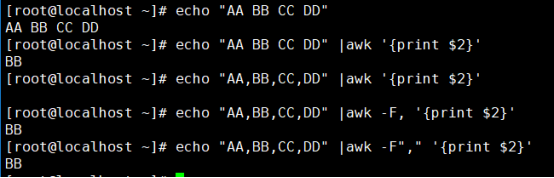

指定多个分隔符
正则表达式[ ] :分隔符事括号[ ]中的一个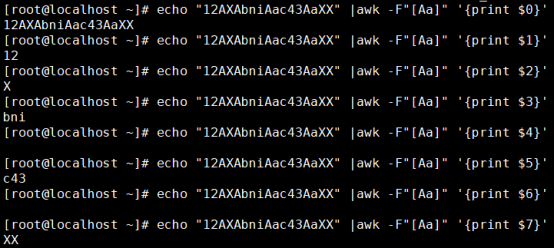
(2)关系运算符的使用
NF 表示字段数 $NF 表示最后一个字段
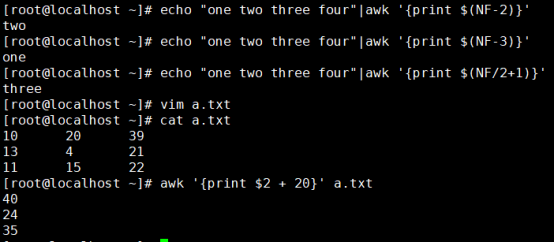
{print $2+20}这里关系运算可用空格可不用空格
例1:打印出passwd文件中用户ID小于10的用户名和它登录使用的SHELL
[root@localhost ~]# head -n 10 /etc/passwd > mima
[root@localhost ~]# awk -F: ‘$3<5{print $1,$NF}' mima
#“,”这个是分隔符,可以自定义,以自己定义的分隔符分割
[root@localhost ~]# awk -F: '$3<5{print $1" "$NF}' mima
[root@localhost ~]# awk -F: '$3<5{print $1"\t"$NF}' mima
[root@localhost ~]# awk -F: '$3<5{print $1" <====> "$NF}' mima
例2:打印出系统中能够正常登录的普通用户
[root@localhost ~]# awk -F: '$3>=500 && $NF==”/bin/bash”{print $1”\t”$NF}’ /etc/passwd
qzh /bin/bash
例3:添加开始和结束模块
[root@localhost ~]# cat test.awk
BEGIN{
print “UserId\t\tShell”
print “———————————————“
FS=”:”
}
$3>=500 && $NF==”/sbin/nologin”{
printf “%-20s %-20s\n”,$1,$NF
}
END{
print “———————————————“
}
[root@localhost ~]# awk -f test.awk /etc/passwd
UserId Shell
———————————————
polkitd /sbin/nologin
libstoragemgmt /sbin/nologin
colord /sbin/nologin
saslauth /sbin/nologin
chrony /sbin/nologin
geoclue /sbin/nologin
nfsnobody /sbin/nologin
setroubleshoot /sbin/nologin
gnome-initial-setup /sbin/nologin
———————————————
(3)统计当前内存的使用率
[root@localhost ~]# cat user_cache.sh
#!/bin/bash
echo “当前系统内存使用百分比为:”
USERPREE=free -m|grep -i mem|awk '{printf "%.2f\n",$3/$2*100}'
#%.2f\n 表示小数字后保留两位
echo -e “内存使用百分为: \e[31m$USERPREE%\e[0m”
[root@localhost ~]# sh user_cache.sh
当前系统内存使用百分比为:
内存使用百分为:16.12%
awk进阶应用
命令格式:
awk [-F | -f | -v ] ‘BEGIN {} / / {command1;command2} END {}’file
-F 指定分隔符
-f 调用脚本
-v 定义变量
‘{}’ 引用代码块
{…} 命令代码块,包含一条或多条命令
BEGIN 初始化代码块
/ str / 匹配代码块,可以是字符串或正则表达式
{print A;print B} 多条命令使用分号分隔
END 结尾代码块
在awk中,pattern有以下几种:
1) empty空模式,这个也是我们常用的
2) /regular expression/ 仅处理能够被这个模式匹配到的行
[root@localhost ~]#awk -F: ‘/^root/{print $0}’ mima
3) 行范围匹配 (起始行startline,结束行endline)
[root@localhost ~]# awk -F: ‘/daemon/,/halt/{print $0}’ mima
daemon:x:32:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:15:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:17:0:halt:/sbin:/sbin/halt
[root@localhost ~]# awk -F: ‘(NR>=3 && NR<=6){print NR,$0}’ mima
3 daemon:x:32:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:15:0:sync:/sbin:/bin/sync
============================================
内置变量的特殊用法:
ü $0 表示整个当前行
ü NF 字段数量
ü NR 每行的记录号,多文件记录递增
ü \t 制表符
ü \n 换行符
ü ~ 匹配,与==相比不是精确比较
ü !~ 不匹配,不精确比较
ü -F’[:#/]+’ 定义三个分隔符
例1:提取IP地址
说明:
[ :]+表示以空格和分号为分隔符,但是因为有可能有多个空格或冒号,所以用一个+表示重复前的。NR==2表示行号
$4:这里是以空格和“:”为分隔符,虽然说是在第二行,但这里的第一个字段应该是eth0,第二才是inet。
例2:NR与FNR的区别
对于NR来说,在读取不同的文件时,NR是一直加的(行号一直顺着加下去)
对于FNR来说,在读取不同的文件时,它读取下一个文件时,FNR会从1开始重新计算的(不同文件不同行号)
例3:去首行 (三种方式:三种文本处理工具)
例4:匹配
例5:条件表达式
select?if-true:if-false 问号前面是条件,如果条件为真执行if-true,为假执行if-false
awk -F: ‘{$3<10?USER=”aaa”:USER=”BBB”;print $1,USER}’ mima
先定义变量,再print,awk中调用变量直接写变量名就可以,不用前面加$号
用if(条件){命令1;命令2}elif(条件){命令}else{命令}中,在比较条件中用( )扩起来,在AWK中,如果条件为1为真0为假
awk -F: ‘{if($3<10){print “user=>”$1}else{print “pass=>”$1}}’ mima
print是打印输出命令,其后面“”中的内容原样输出
[root@localhost ~]# awk -F: ‘{if($3<=5 && $NF ~ “/bin/bash”){print $1,$NF}}’ mima
root /bin/bash
[root@localhost ~]# awk ‘BEGIN{test=100;total=0;while(i<=test){total+=i;i++};print total}’
5050
例6:变量
1)用-v指定 var=value 变量名区分大小写的
2)在程序中直接定义
例7:格式化输出
printf命令:格式化输出 printf “FORMAT”,item1,item2…….
format的使用
注意:
1、其与print命令的最大不同是,printf需要指定format
2、format用于指定后面的每个item的输出格式
3、printf语句不会自动打印换行符;\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码
%d:十进制整数
%e:科学计数法显示数值
%f : 显示浮点数
%g : 以科学计数法的格式或浮点数的格式显示数值;
%s : 显示字符串
%u : 无符号整数
%%: 显示%自身
比如:
[root@localhost ~]# awk -F: ‘{printf “%s”,$1}’ mima #不会自动换行rootbindaemonadmlp [root@localhost ~]#
[root@localhost ~]# awk -F: ‘{printf “%s\n”,$1}’ mima
[root@localhost ~]# awk -F: ‘{printf “USERNAME: %s\n”,$1}’ mima #可以在前面自定义字符串
[root@localhost ~]# awk -F: ‘{printf “USERNAME: %s %s\n”,$1,$NF}’ mima
[root@localhost ~]# awk -F: ‘{printf “USERNAME: %s=========%s\n”,$1,$NF}’ mima
修饰符:
%[+-n.n]s ====> %15s %-15s %-.6f
N: 显示宽度
-: 左对齐
+:显示数值符号
比如:
[root@localhost ~]# awk -F: ‘{printf “USENAME:%-10s %10s\n”,$1,$NF}’ mima
[root@localhost ~]# awk -F: ‘{printf “USENAME:%-10s %15s\n”,$1,$NF}’ mima
[root@localhost ~]# awk -F: ‘{printf “USENAME:%10s %15s\n”,$1,$NF}’ mima
综合:
[root@localhost ~]# awk ‘BEGIN{miao=0;zhang=0;print “name yuwen shuxue”;print “================”}{miao+=$2;zhang+=$3;printf “%-4s %-4d %-4d\n”,$1,$2,$3}END{print “===================”;printf “TOTAL:%5d %5d\n”,miao,zhang;printf “AVGER:%5.2f %5.2f\n”,miao/NR,zhang/NR}’ b.txt
name yuwen shuxue
================
a 10 15
b 5 10
c 3 6
===================
TOTAL: 18 31
AVGER: 6.00 10.33
实例
awk –F : ‘{print $2}’ datafile
#以:分隔打印第二列
awk –F : ‘/^Dan/{print $2}’ datafile
#以:分隔打印以Dan开头行的第二列内容
awk –F : ‘/^[CE]/{print $1}’ datafile
#打印以C或E开头行的第一列
awk –F : ‘{if(length($1) == 4) print $1}’ datafile
#打印以:分隔且长度为4字符的第一列内容
awk –F : ‘/[916]/{print $1}’ datafile
#匹配916的行以:分隔打印第一列
awk -F : ‘/^Vinh/{print “a”$5}’ 2.txt
#显示以Dan开头行并在第五列前加上a
awk –F : ‘{print $2”,”$1}’ datafile
#打印第二列第一列并以,分隔
awk -F : ‘($5 == 68900) {print $1}’ 2.txt
#以:分隔打印第五列是68900的行第一列
awk -F : ‘{if(length($1) == 11) print $1}’ 2.txt
#打印以:分隔且长度为4字符的第一列内容
awk -F : ‘$1~/Tommy Savage/ {print $5}’ 2.txt
awk -F : ‘($1 == “Tommy Savage”) {print $5}’ 2.txt
#打印以:分隔且第一列为Tommy Savage的第五列内容
ll |awk ‘BEGIN {size=0;} {size=size+$5;} END{print “[end]size is “,size}’
#统计目录个的文件所有的字节数
awk ‘BEGIN{size=0;} {size=size+$5;} END{print “[end]size is “,size/1024/1024,”M”}’
#以M为单位显示目录下的所有字节数
awk ‘BEGIN{a=10;a+=10;print a}’
20
#a+10等价于 a=a+10
echo|awk ‘BEGIN{a=”100testaaa”}a~/test/{print “ok”}’
#正则匹配a 是否有test字符,成立打印ok
awk ‘BEGIN{a=”b”;print a==”b”?”ok”:”err”}’
ok
awk ‘BEGIN{a=”b”;print a==”c”?”ok”:”err”}’
err
#三目运算符?:
awk ‘/root/{print $0}’ passwd
#匹配所有包含root的行
awk -F: ‘$5~/root/{print $0}’ passwd
# 以分号作为分隔符,匹配第5个字段是root的行
ifconfig eth0|awk ‘BEGIN{FS=”[[:space:]:]+”} NR==2{print $4}’
#打印IP地址
awk ‘{print toupper($0)}’ test.txt
#toupper是awk内置函数,将所小写字母转换成大写
[root@localhost ~]# free -m
total used free shared buffers cached
Mem: 980 667 313 0 26 522
-/+ buffers/cache: 118 862
Swap: 2047 0 2047
[root@localhost ~]# free -m | grep buffers | awk ‘{print $NF}’
cached
862
[root@localhost ~]# free -m | grep buffers\/ | awk ‘{print $NF}’
862
[root@localhost ~]# free -m | grep buffers/ | awk ‘{print $NF}’
862
[root@localhost ~]# free -m | awk ‘NR==3 {print $NF}’
862
提取硬盘分区内存使用情况
[root@localhost ~]# df -h |awk ‘$1~/sd/{print $1 “\t”$2 “\t” $5 “\n” }’
/dev/sda3 18G 16%
/dev/sda1 190M 19%
提取linux中eth0的ip地址
ifconfig eth0 | grep ‘inet addr’ | awk -F “:” ‘{print $2}’ | awk ‘{print $1 }’
使用格式:
# awk [options] ‘{print $1}’ file1, file2, …
[root@localhost ~]# awk ‘{print $1,$2,$3}’ a.txt
脚本关于内存

若有收获,就点个赞吧
0 人点赞
