OOM Kill
配置的内存跟运行-Xms内存问题
-Xms 运行最小内存-Xmg 运行最大内存手动打印heapdump.hprof 分析java性能问题jmap -dump:format=b,file=/usr/src/app/heapdump.hprof 1
入口流量管理
目前是全部流量是经过 ingress 七层负载进来
后续架构需要增加四层负载,提高灵活性
ingress 配置域名,七层负载
server ip:端口 四层负载
错误代码
生产经验
303 重定向403 白名单,服务出口白名单拦截了404 域名解析不对、域名解析了但服务没构建 没生效410 解析不存在,解析的资源不可以或不存在502 无法获取到服务,端口不对 或者 服务器不对503 有服务,但服务不正常
生产资源分配规范
具体生产环境要跟项目的开发人员沟通,下面只是参考
在流量高峰的时候,到监控系统中查看pod所使用的资源,根据jvm heapdump.hprof再进一步分析,评估所需要的合理资源
一、对于java服务1、对于访问量交小的服务jvm内存配置为2g 资源配置如下request.cpu: 500mrequest.memory: 2048Milimits.cpu: 4000mlimits.memory: 3072Mijvm最大内存: 2048Micpu自动扩缩容阈值:200%2、对于访问量交大的服务或者核心服务jvm内存配置为4g 资源配置如下request.cpu: 1000mrequest.memory: 5120Milimits.cpu: 4000mlimits.memory: 5120Mijvm最大内存: 4096Micpu自动扩缩容阈值:300%二、node项目(注意node项目不允许使用pm2启动)1、node前端项目:request.cpu: 50mrequest.memory: 128MIlimits.cpu: 500mlimits.memory: 1024Mi2、node后端项目:request.cpu: 1000mrequest.memory 2048Milimits.cpu: 1500mlimits.memory: 3072Mi三、python项目request.cpu: 500mrequest.memory 1024Milimits.cpu: 2000mlimits.memory: 2048Mi四、go项目request.cpu: 500mrequest.memory 1024Milimits.cpu: 2000mlimits.memory: 2048M
node出现NotReady
使用内核日志命令追踪原因:journalctl -f -u kubelet
出现PELG
PLEG,指的是 pod lifecycle event generator。PLEG 是 kubelet 用来检查 runtime 的健康检查机制。
这件事情本来可以由 kubelet 使用 polling 的方式来做。但是 polling 有其高成本的缺陷,所以 PLEG 应用而生。PLEG 尝试以一种“中断”的形式,来实现对容器 runtime 的健康检查,虽然实际上,它同时用了 polling 和”中断”这样折中的方案。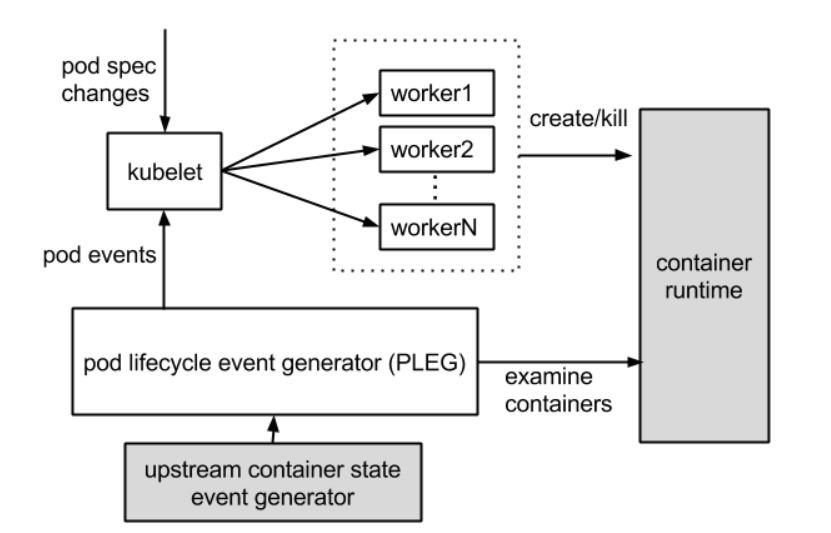
PLEG有两个关键的时间参数,一个是检查的执行间隔,另外一个是检查的超时时间。以默认情况为准,PLEG检查会间隔一秒,换句话说,每一次检查过程执行之后,PLEG会等待一秒钟,然后进行下一次检查;而每一次检查的超时时间是三分钟,如果一次PLEG检查操作不能在三分钟内完成,那么这个状况,会被上一节提到的NodeStatus机制,当做集群节点NotReady的凭据,同步给API Server.
出现驱逐
内存不足
Qos
forbidden
只有出现forbidden都是权限问题
pod is forbidden
容器内抓包定位网络问题
容器进程主动退出、只能运行一个参数
JVM参数在容器中突然失效
1.etcd 集群性能问题,随便容器集群的扩增,etcd性能也会越来越低,要跟着集群扩增进度,跟进etcd性能问题
2.harbor 最好使用云的,不要用自搭的,开发团队到一定规模,pod数量到一定规模,构建越来越频繁,会同时到镜像仓库中拉取镜像,这就需要很高的网络io,自搭的满足不了,所以还是用云的。
上家用的阿里云的harbor都有发版卡顿现象,自搭只会麻烦越来越多。
3.service到达一定规模,不同service互通也会越来越卡,已经是用的lvs了。。。????
随着集群的扩增,master也要跟着增,watch 会实时监听apiserver 跟etcd的通信,node扩增后,watch 量会越来越多,时间也会
域名调度
反亲和,pod固定在某一node
托管集群,master是以pod的形式的存在的
存储:块存储、网络存储、文件存储
k8s事件默认存储一个小时,需要持久化出来
两个pod,导致一直需要验证
使用deployment service ingress 部署sentine,可以登录,但是进去操作又需要重新登录,反复不断
因为起了两个pod,导致service负载均衡
解决:降为一个pod就可以了

若有收获,就点个赞吧
0 人点赞
