小鲸鱼(docker商标为鲸鱼)
2013年开启PaaS时代,平台层服务,这一部分是以Docker为主的PaaS平台发展历程。
dotCloud,docker前公司
Cloud Foundry这样的PaaS项目,最核心的组件就是一套应用的打包和分发机制。
cf push “我的应用”
但Cloud Foundry 打包很麻烦,就引出了很多解决这个打包问题的项目,docker就这样产生了。
Cloud Foundry 会调用操作系统的 Cgroups 和 Namespace 机制为每一个应用单独创建一个称作“沙盒”的隔离环境,然后在“沙盒”中启动这些应用进程。
事实上,Docker 项目确实与 Cloud Foundry 的容器在大部分功能和实现原理上都是一样的,可偏偏就是这剩下的一小部分不一样的功能,成了 Docker 项目接下来“呼风唤雨”的不二法宝。
这个功能,就是 Docker 镜像。
Docker镜像解决的,恰恰就是打包这个根本性的问题
docker build “我的镜像”
docker run “我的镜像”
docker run 创建的“沙盒”,也是使用 Cgroups 和 Namespace 机制创建出来的隔离环境。
Docker 项目给 PaaS 世界带来的“降维打击”,其实是提供了一种非常便利的打包机制。这种机制直接打包了应用运行所需要的整个操作系统,从而保证了本地环境和云端环境的高度一致,避免了用户通过“试错”来匹配两种不同运行环境之间差异的痛苦过程。
在 2014 年底的 DockerCon 上,Docker 公司雄心勃勃地对外发布了自家研发的“Docker 原生”容器集群管理项目 Swarm,不仅将这波“CaaS”热推向了一个前所未有的高潮,更是寄托了整个 Docker 公司重新定义 PaaS 的宏伟愿望。
总结1
2013~2014 年,以 Cloud Foundry 为代表的 PaaS 项目,逐渐完成了教育用户和开拓市场的艰巨任务,也正是在这个将概念逐渐落地的过程中,应用“打包”困难这个问题,成了整个后端技术圈子的一块心病。
Docker 项目的出现,则为这个根本性的问题提供了一个近乎完美的解决方案。这正是 Docker 项目刚刚开源不久,就能够带领一家原本默默无闻的 PaaS 创业公司脱颖而出,然后迅速占领了所有云计算领域头条的技术原因。
而在成为了基础设施领域近十年难得一见的技术明星之后,dotCloud 公司则在 2013 年底大胆改名为 Docker 公司。不过,这个在当时就颇具争议的改名举动,也成为了日后容器技术圈风云变幻的一个关键伏笔。
总结2
docker公司先推出docker镜像技术解决了Cloud Foundry项目的打包问题,也同时解决了PaaS的根本性问题
docker公司再推Swarm项目,就是让开发者把程序部署到我的项目上,吸引生态到自家的PaaS项目上
无开源不生态,无生态不商业
docker开源和改名字都是为了后续商业铺垫的
总结3
只有那些能够为用户提供平台层能力的工具,才会真正成为开发者们关心和愿意付费的产品。而 Docker 项目这样一个只能用来创建和启停容器的小工具,最终只能充当这些平台项目的“幕后英雄”。
2014年CoreOS公司推出自家的容器项目:rkt
Docker公司收购Fig项目,Fig项目是第一个提出了容器编排(Container Orchestration)概念的
容器时代,“编排”显然就是对 Docker 容器的一系列定义、配置和创建动作的管理。
Fig项目被收购后改名为compose,也就是docker-compose
Docker还收购了专门处理容器网络的SocketPlane项目,专门给Docker集群做图形化管理界面和对外提供云服务的Tutum项目 (rancher就是这种类型的项目)
Mesosphere公司推出了集群管理项目:Mesos
Mesos 作为 Berkeley 主导的大数据套件之一,是大数据火热时最受欢迎的资源管理项目,也是跟 Yarn 项目杀得难舍难分的实力派选手
Mesosphere 公司发布了一个名为 Marathon 的项目,而这个项目很快就成为了 Docker Swarm 的一个有力竞争对手。
Mesos+Marathon组合实际上进化成了一个高度成熟的PaaS项目,是当时Docker公司最强的对手
CoreOS的容器 rkt+集群管理平台Fleet,RedHat的Openshift都不行
在这些公司打得火热的时候,2014年6月,谷歌开源了Kubernetes项目,直接改变了容器市场的格局。
总结4
于是,2015 年 6 月 22 日,由 Docker 公司牵头,CoreOS、Google、RedHat 等公司共同宣布,Docker 公司将 Libcontainer 捐出,并改名为 RunC 项目,交由一个完全中立的基金会管理,然后以 RunC 为依据,大家共同制定一套容器和镜像的标准和规范。
这套标准和规范,就是 OCI( Open Container Initiative )。OCI 的提出,意在将容器运行时和镜像的实现从 Docker 项目中完全剥离出来。这样做,一方面可以改善 Docker 公司在容器技术上一家独大的现状,另一方面也为其他玩家不依赖于 Docker 项目构建各自的平台层能力提供了可能。
docker - containerd - runc - OCI格式的容器
libcontainer是containerd的前身
Kubernetes 的应对策略则是反其道而行之,开始在整个社区推进“民主化”架构,即:从 API 到容器运行时的每一层,Kubernetes 项目都为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到 Kubernetes 项目的每一个阶段。
Kubernetes 项目的这个变革的效果立竿见影,很快在整个容器社区中催生出了大量的、基于 Kubernetes API 和扩展接口的二次创新工作,比如:
- 目前热度极高的微服务治理项目 Istio;
- 被广泛采用的有状态应用部署框架 Operator;
- 还有像 Rook 这样的开源创业项目,它通过 Kubernetes 的可扩展接口,把 Ceph 这样的重量级产品封装成了简单易用的容器存储插件。
etcd的作者是李响,当时还在CoreOS,etcd也就是CoreOS的作品
2017 年 10 月,Docker 公司出人意料地宣布,将在自己的主打产品 Docker 企业版中内置 Kubernetes 项目,这标志着持续了近两年之久的“编排之争”至此落下帷幕。
2018 年 1 月 30 日,RedHat 宣布斥资 2.5 亿美元收购 CoreOS。
2018 年 3 月 28 日,这一切纷争的始作俑者,Docker 公司的 CTO Solomon Hykes 宣布辞职,曾经纷纷扰扰的容器技术圈子,到此尘埃落定。
容器基础
Namespace隔离
之前的内容:
- 容器技术的兴起源于 PaaS 技术的普及;
- Docker 公司发布的 Docker 项目具有里程碑式的意义;
- Docker 项目通过“容器镜像”,解决了应用打包这个根本性难题。
容器本身没有价值,有价值的是“容器编排”
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用来修改进程视图的主要方法。
-it TTY,就是文本输入输出环境
宿主机的进程id跟容器中的进程id不一样
在 Linux 系统中创建线程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。
注意:clone()是线程操作,但linux的线程是用进程实现的
而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
$ docker run -it busybox /bin/sh
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
能看到,容器中的/bin/sh进程的pid是1,但在宿主机上,运行/bin/sh程序的进程可以是100
除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
这,就是 Linux 容器最基本的实现原理了。
Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
所以说,容器,其实是一种特殊的进程而已。
容器就是Namespace(命名空间)各种参数配置的特殊进程
目前八种命名空间:
Cgroups限制
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
一句话:单单基于namespace实现容器隔离还是有问题的。
虚拟化和容器化技术对比:
使用虚拟化技术作为应用沙盒,就必须要由 Hypervisor 来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。
根据实验,一个运行着 CentOS 的 KVM 虚拟机启动后,在不做优化的情况下,虚拟机自己就需要占用 100~200 MB 内存。此外,用户应用运行在虚拟机里面,它对宿主机操作系统的调用就不可避免地要经过虚拟化软件的拦截和处理,这本身又是一层性能损耗,尤其对计算资源、网络和磁盘 I/O 的损耗非常大。
而相比之下,容器化后的用户应用,却依然还是一个宿主机上的普通进程,这就意味着这些因为虚拟化而带来的性能损耗都是不存在的;而另一方面,使用 Namespace 作为隔离手段的容器并不需要单独的 Guest OS,这就使得容器额外的资源占用几乎可以忽略不计。
“敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。
不过,有利就有弊,基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
但在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
你是否知道如何修复容器中的 top 指令以及 /proc 文件系统中的信息呢?(提示:lxcfs)
rootfs容器文件系统
这就是 Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核。
这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说是一个“全局变量”,牵一发而动全身。
正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。
Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程,而是做了一个小小的创新:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union File System)的能力。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下
镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面。
而且,从这个结构可以看出来,这个容器的 rootfs 由如下图所示的三部分组成: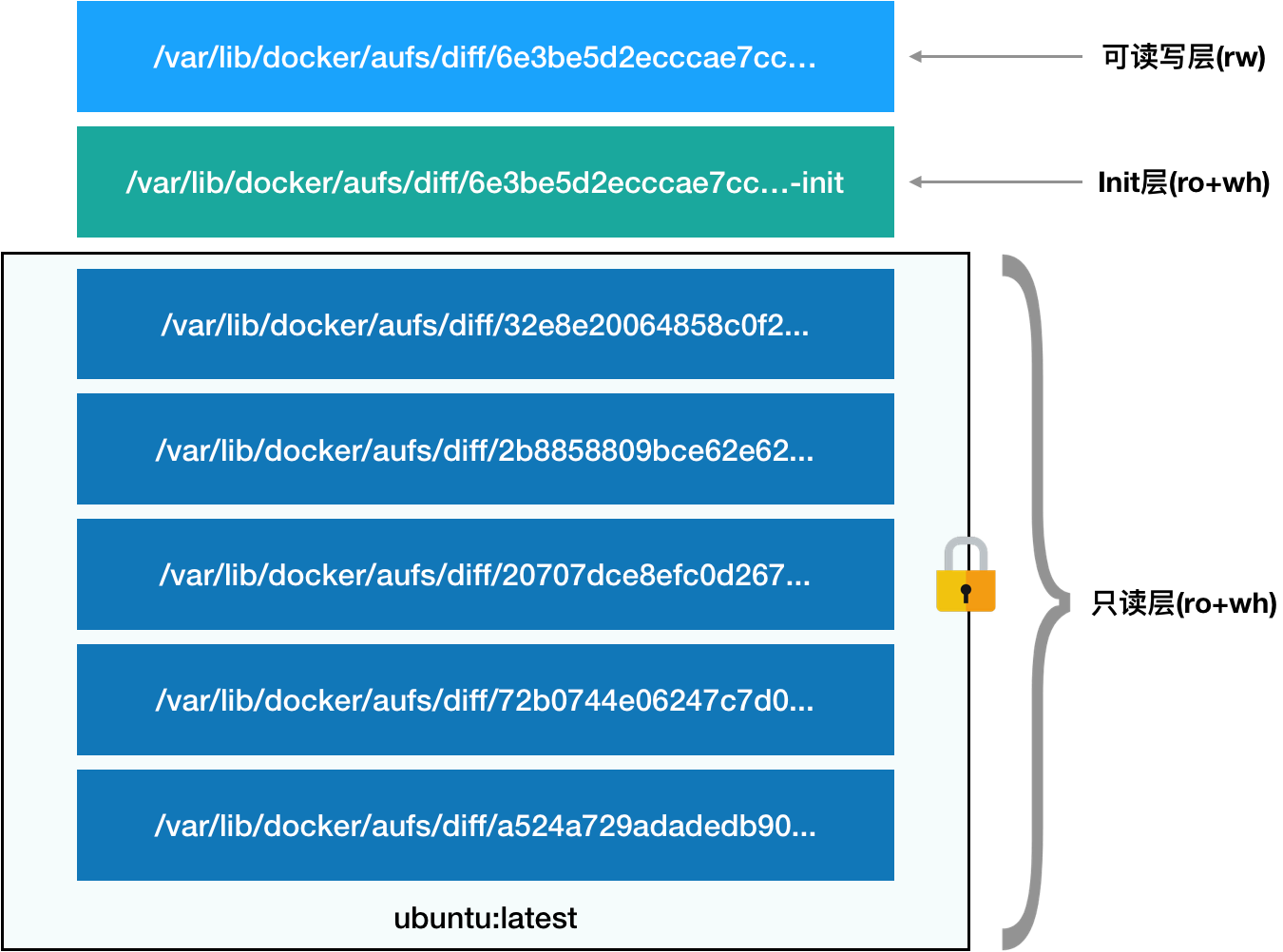 第一部分,只读层,就是镜像层
第一部分,只读层,就是镜像层
第二部分,可读写层,也称容器层,是这个容器的 rootfs 最上面的一层
第三部分,Init层,是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
总结:
在今天的分享中,我着重介绍了 Linux 容器文件系统的实现方式。而这种机制,正是我们经常提到的容器镜像,也叫作:rootfs。它只是一个操作系统的所有文件和目录,并不包含内核,最多也就几百兆。而相比之下,传统虚拟机的镜像大多是一个磁盘的“快照”,磁盘有多大,镜像就至少有多大。
通过结合使用 Mount Namespace 和 rootfs,容器就能够为进程构建出一个完善的文件系统隔离环境。当然,这个功能的实现还必须感谢 chroot 和 pivot_root 这两个系统调用切换进程根目录的能力。
而在 rootfs 的基础上,Docker 公司创新性地提出了使用多个增量 rootfs 联合挂载一个完整 rootfs 的方案,这就是容器镜像中“层”的概念。
通过“分层镜像”的设计,以 Docker 镜像为核心,来自不同公司、不同团队的技术人员被紧密地联系在了一起。而且,由于容器镜像的操作是增量式的,这样每次镜像拉取、推送的内容,比原本多个完整的操作系统的大小要小得多;而共享层的存在,可以使得所有这些容器镜像需要的总空间,也比每个镜像的总和要小。这样就使得基于容器镜像的团队协作,要比基于动则几个 GB 的虚拟机磁盘镜像的协作要敏捷得多。
更重要的是,一旦这个镜像被发布,那么你在全世界的任何一个地方下载这个镜像,得到的内容都完全一致,可以完全复现这个镜像制作者当初的完整环境。这,就是容器技术“强一致性”的重要体现。
而这种价值正是支撑 Docker 公司在 2014~2016 年间迅猛发展的核心动力。容器镜像的发明,不仅打通了“开发 - 测试 - 部署”流程的每一个环节,更重要的是:
容器镜像将会成为未来软件的主流发布方式。
- 既然容器的 rootfs(比如,Ubuntu 镜像),是以只读方式挂载的,那么又如何在容器里修改 Ubuntu 镜像的内容呢?(提示:Copy-on-Write)
上面的读写层通常也称为容器层,下面的只读层称为镜像层,所有的增删查改操作都只会作用在容器层,相同的文件上层会覆盖掉下层。知道这一点,就不难理解镜像文件的修改,比如修改一个文件的时候,首先会从上到下查找有没有这个文件,找到,就复制到容器层中,修改,修改的结果就会作用到下层的文件,这种方式也被称为copy-on-write。
- 除了 AuFS,你知道 Docker 项目还支持哪些 UnionFS 实现吗?你能说出不同宿主机环境下推荐使用哪种实现吗?
查了一下,包括但不限于以下这几种:aufs, device mapper, btrfs, overlayfs, vfs, zfs。aufs是ubuntu 常用的,device mapper 是 centos,btrfs 是 SUSE,overlayfs ubuntu 和 centos 都会使用,现在最新的 docker 版本中默认两个系统都是使用的 overlayfs,vfs 和 zfs 常用在 solaris 系统。
python web
from flask import Flaskimport socketimport osapp = Flask(__name__)@app.route('/')def hello():html = "<h3>Hello {name}!</h3>" \"<b>Hostname:</b> {hostname}<br/>"return html.format(name=os.getenv("NAME", "world"), hostname=socket.gethostname())if __name__ == "__main__":app.run(host='0.0.0.0', port=80)
$ cat requirements.txtFlask
Dockerfile
# 使用官方提供的 Python 开发镜像作为基础镜像FROM python:2.7-slim# 将工作目录切换为 /appWORKDIR /app# 将当前目录下的所有内容复制到 /app 下ADD . /app# 使用 pip 命令安装这个应用所需要的依赖RUN pip install --trusted-host pypi.python.org -r requirements.txt# 允许外界访问容器的 80 端口EXPOSE 80# 设置环境变量ENV NAME World# 设置容器进程为:python app.py,即:这个 Python 应用的启动命令CMD ["python", "app.py"]
你可能还会看到一个叫作 ENTRYPOINT 的原语。实际上,它和 CMD 都是 Docker 容器进程启动所必需的参数,完整执行格式是:“ENTRYPOINT CMD”。
但是,默认情况下,Docker 会为你提供一个隐含的 ENTRYPOINT,即:/bin/sh -c。所以,在不指定 ENTRYPOINT 时,比如在我们这个例子里,实际上运行在容器里的完整进程是:/bin/sh -c “python app.py”,即 CMD 的内容就是 ENTRYPOINT 的参数。
备注:基于以上原因,我们后面会统一称 Docker 容器的启动进程为 ENTRYPOINT,而不是 CMD。
需要注意的是,Dockerfile 里的原语并不都是指对容器内部的操作。就比如 ADD,它指的是把当前目录(即 Dockerfile 所在的目录)里的文件,复制到指定容器内的目录当中。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
Volume 数据卷
$ docker run -v /test ...$ docker run -v /home:/test ...
在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。
Kubernetes本质
前面的内容概况:一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程(容器是一个特殊的进程)的隔离环境。
从这个结构中我们不难看出,一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
更进一步地说,作为一名开发者,我并不关心容器运行时的差异。因为,在整个“开发 - 测试 - 发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
容器 = 容器运行时 + 容器镜像
容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的“容器编排”技术,则当仁不让地坐上了容器技术领域的“头把交椅”。
这其中,最具代表性的容器编排工具,当属 Docker 公司的 Compose+Swarm 组合,以及 Google 与 RedHat 公司共同主导的 Kubernetes 项目。
kubernetes的设计与架构
控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Ectd 中。
计算节点上最核心的部分,则是一个叫作 kubelet 的组件。
kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。
Borg 项目,并不支持我们这里所讲的容器技术,而只是简单地使用了 Linux Cgroups 对进程进行限制。
这就意味着,像 Docker 这样的“容器镜像”在 Borg 中是不存在的,Borglet 组件也自然不需要像 kubelet 这样考虑如何同 Docker 进行交互、如何对容器镜像进行管理的问题,也不需要支持 CRI、CNI、CSI 等诸多容器技术接口。
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
Service 服务的主要作用,就是作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址。
部署—kubeadm

若有收获,就点个赞吧
0 人点赞
