所有的实验集合
集群搭建前准备.docx
实验一:Hadoop集群的安装.doc
实验二:zookeeper的安装.doc
实验三:Hadoop HA集群的安装.doc
实验四:Hbase单机版的安装 (1).doc
实验五:Hbase HA集群的安装.doc
第一章


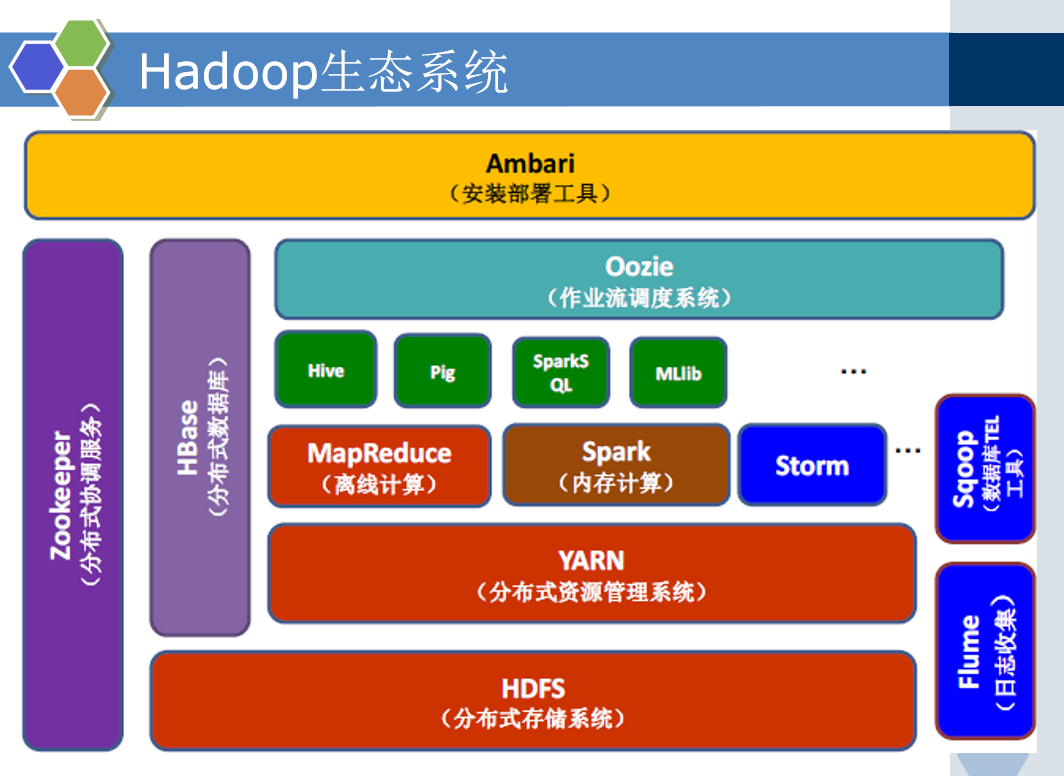
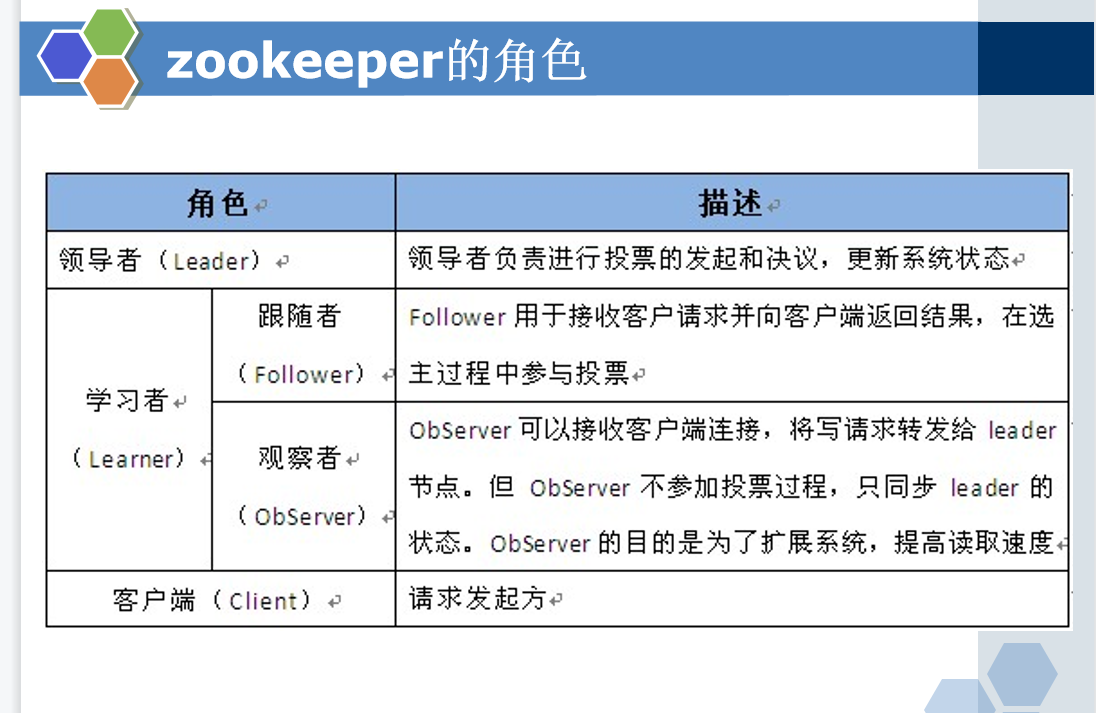
知道:zookeeper是分布式协调服务,hbase架构在hdfs之上


第1章 HBase简介.ppt
第二章

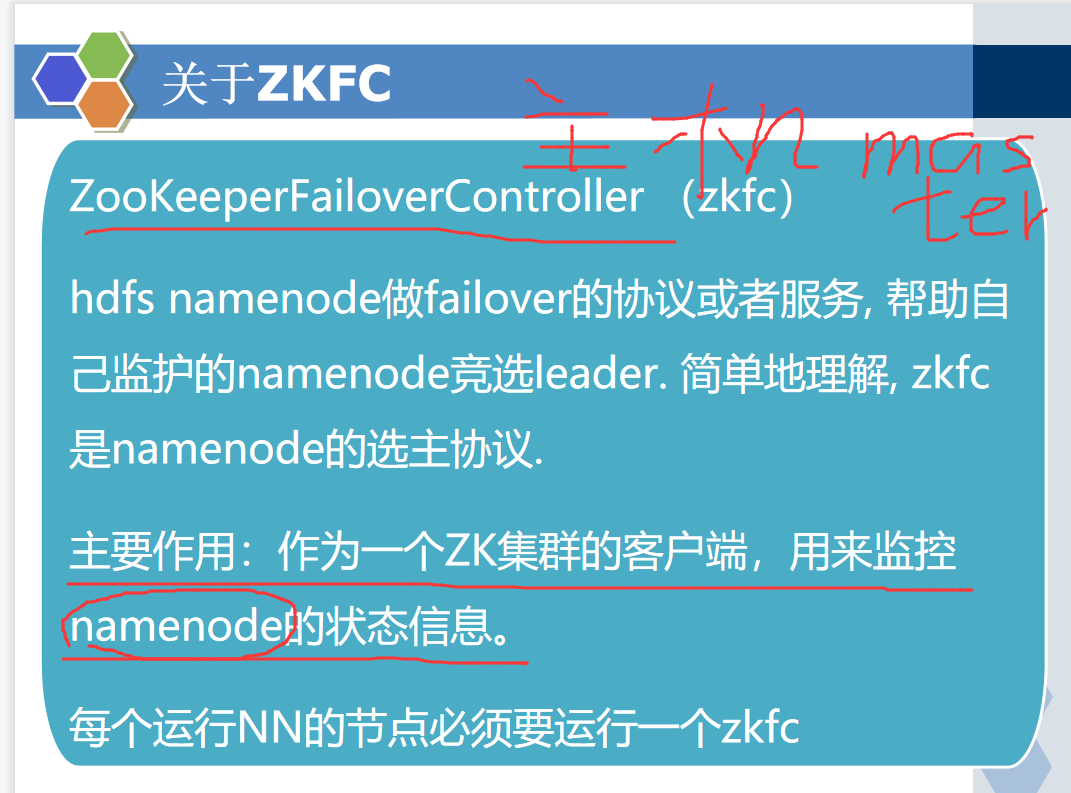
要知道 HDFS采用的是master/slave架构,HDFS有namenode和datanode,还有一个SecondaryNameNode



客户端的节点




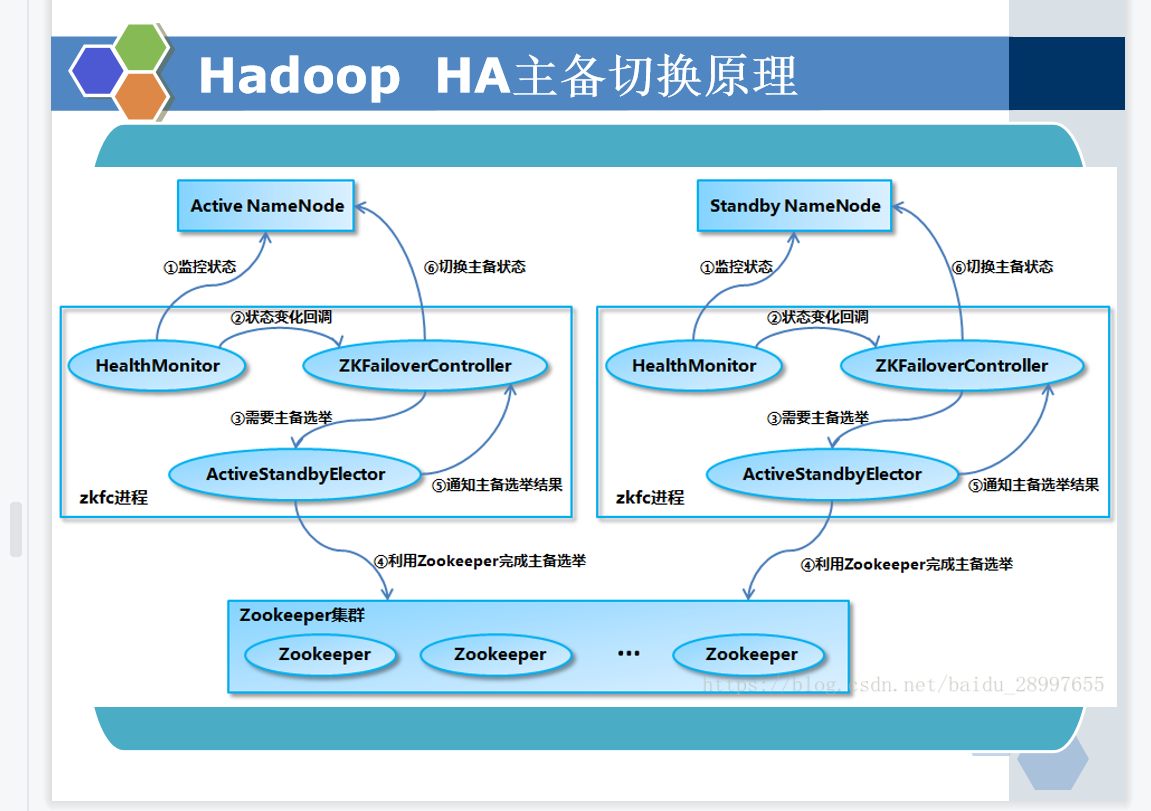



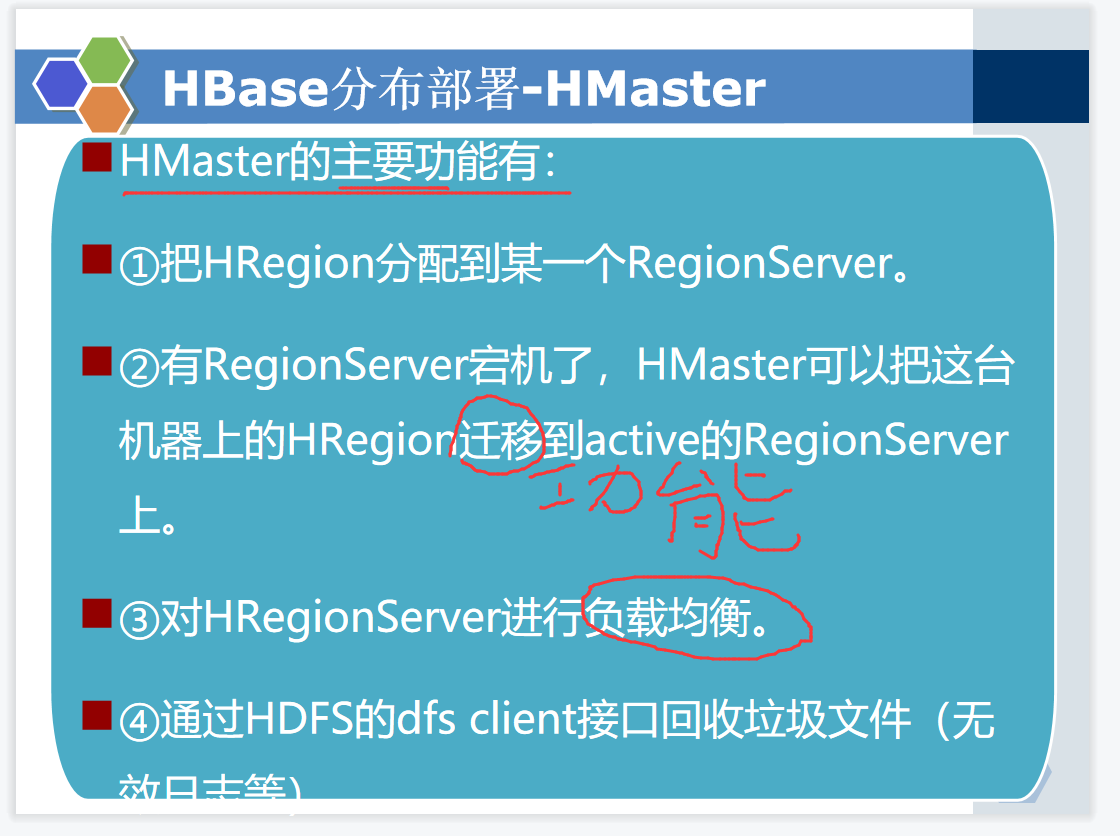



答案:
- as
- as
- ad
Hbase配置文件
第三章

有四个维度:行键,列族,列限定符,时间戳
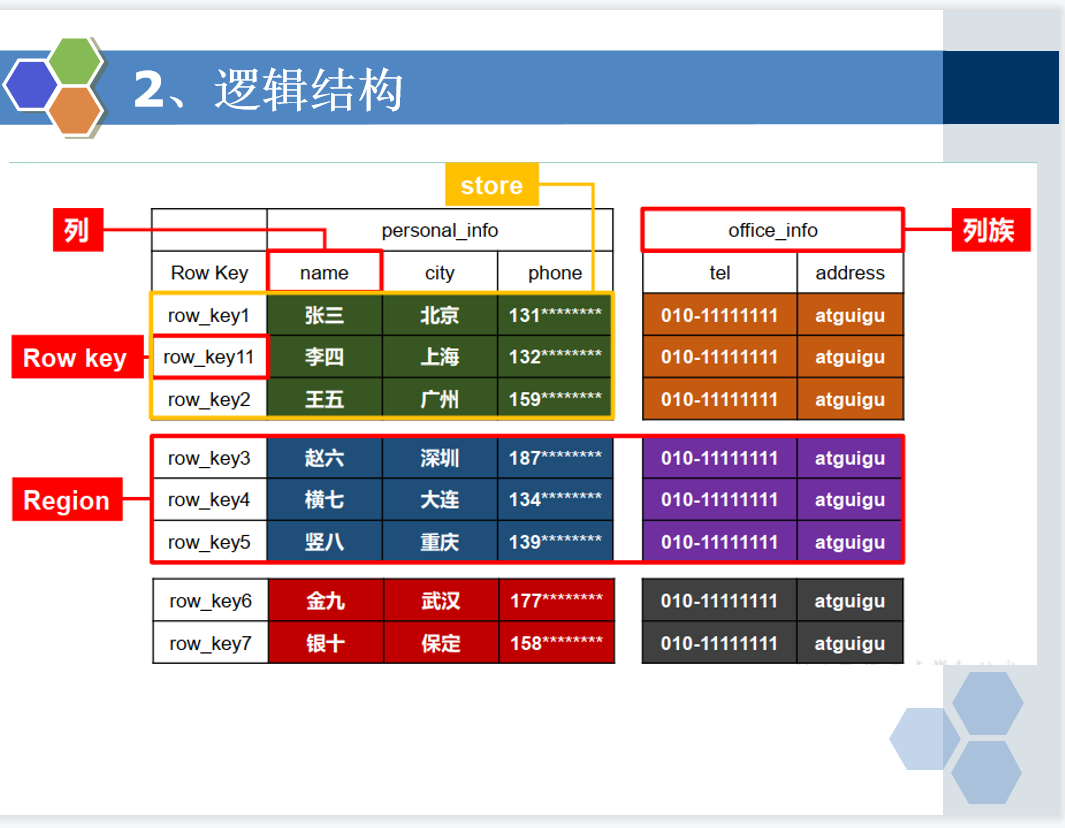

在hbase数据库里面存储他是没有数据类型的,所有 的都是字节类型的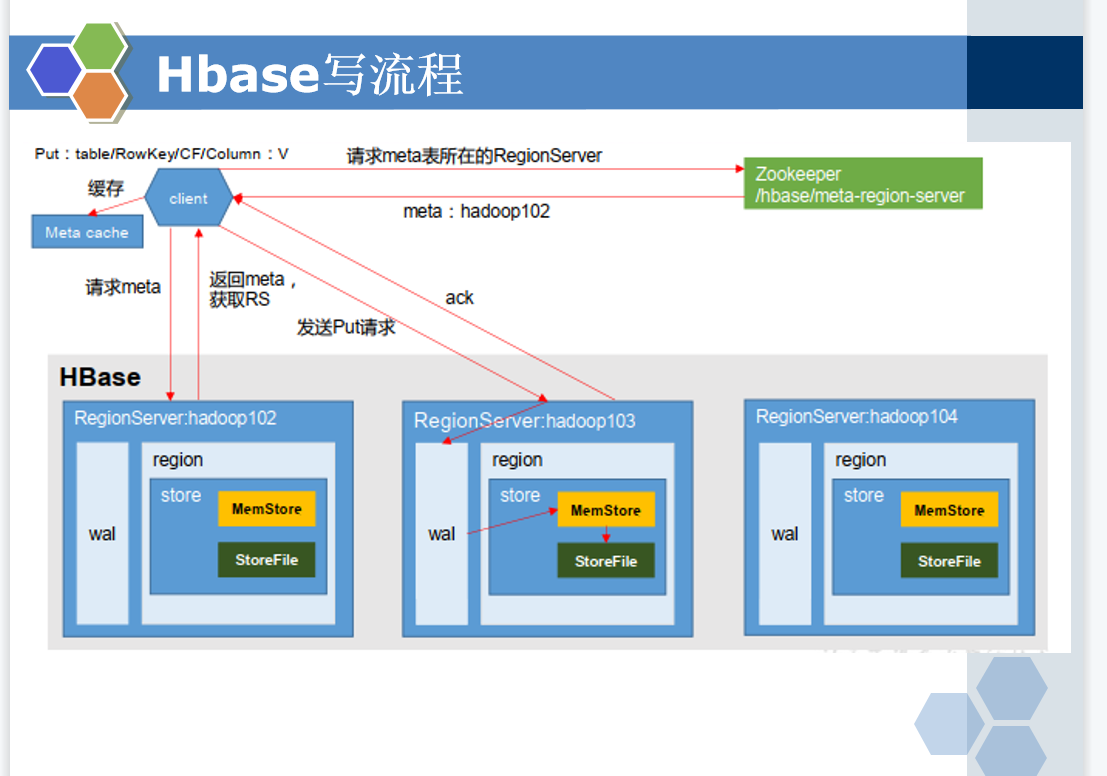






读流程的效率比写流程低一些,因为读要一层一层读,很多层
第3章 Hbase数据模型.ppt
第四章

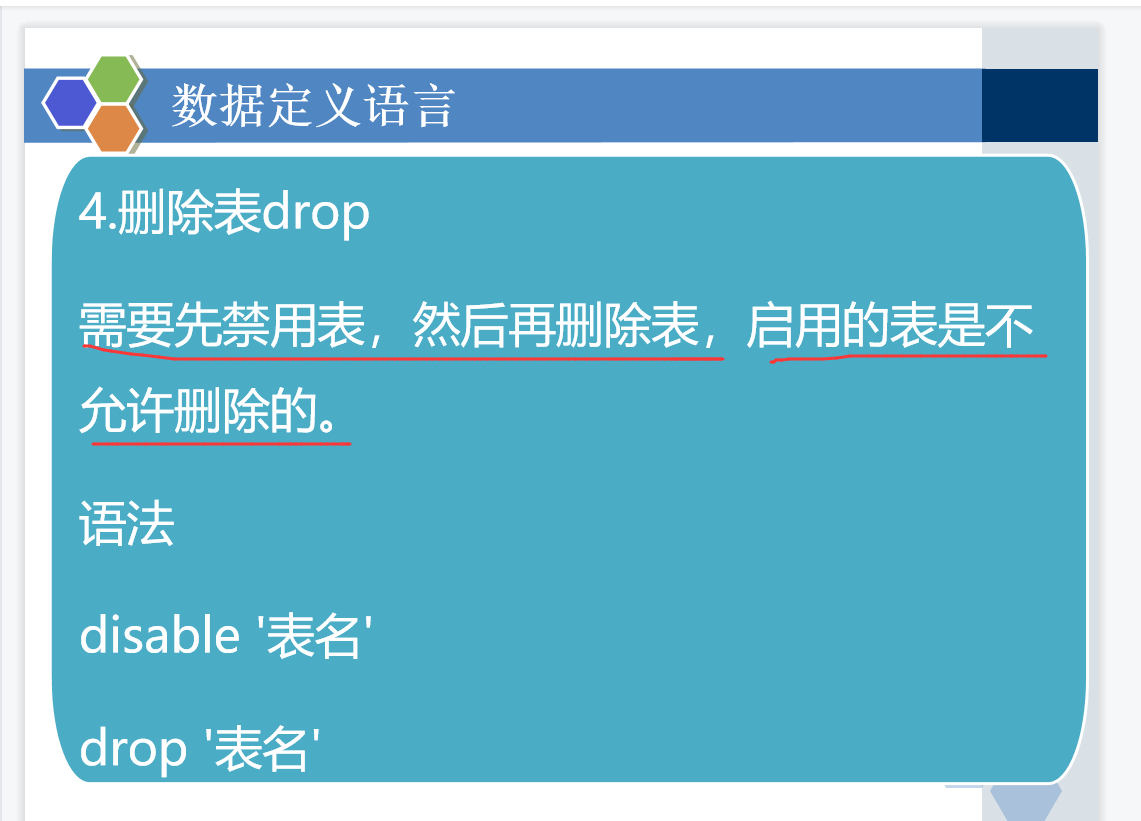
创建表的时候,不加列族 不行!,必须加!




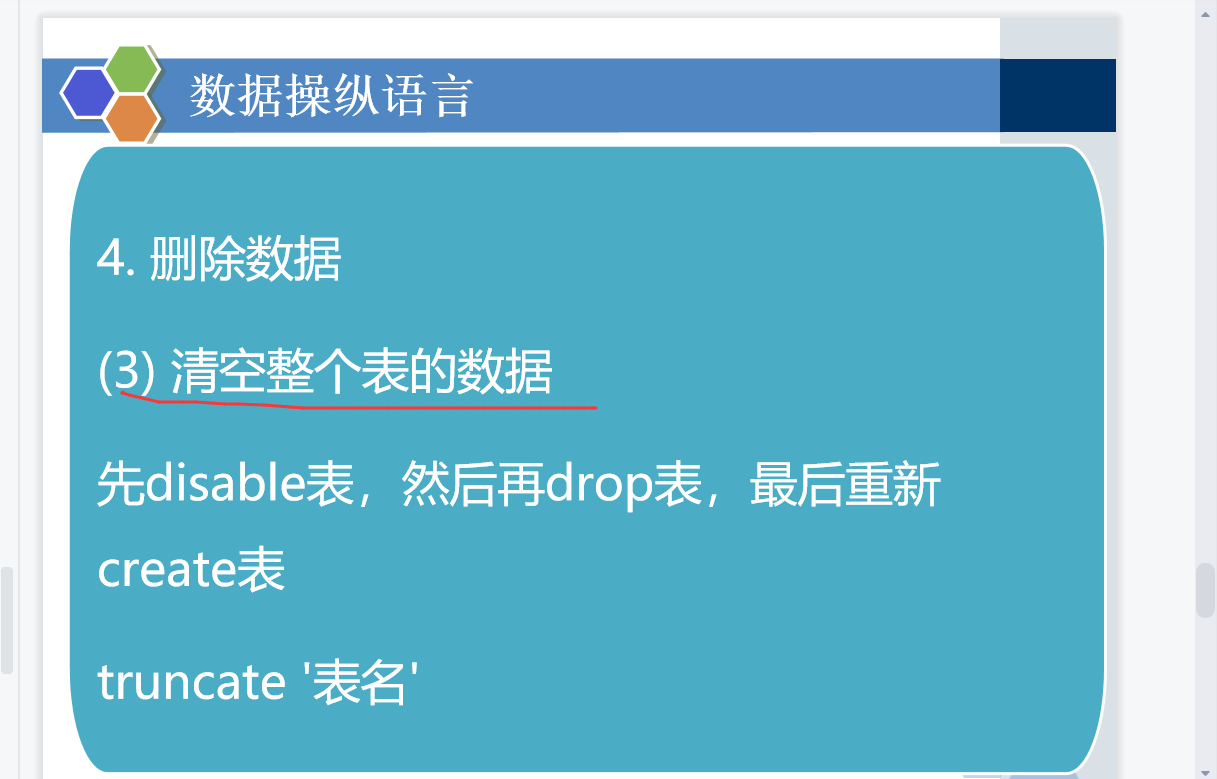
第五章
索引由行键来承担
行键可以作为一级索引


因为会出现热点区间

书上55页,一共五个表,user,t-following,关注被关注,相册,时间限制
问题:
- 需求 55页这几个
- 主键管理,画表+解释
第六章
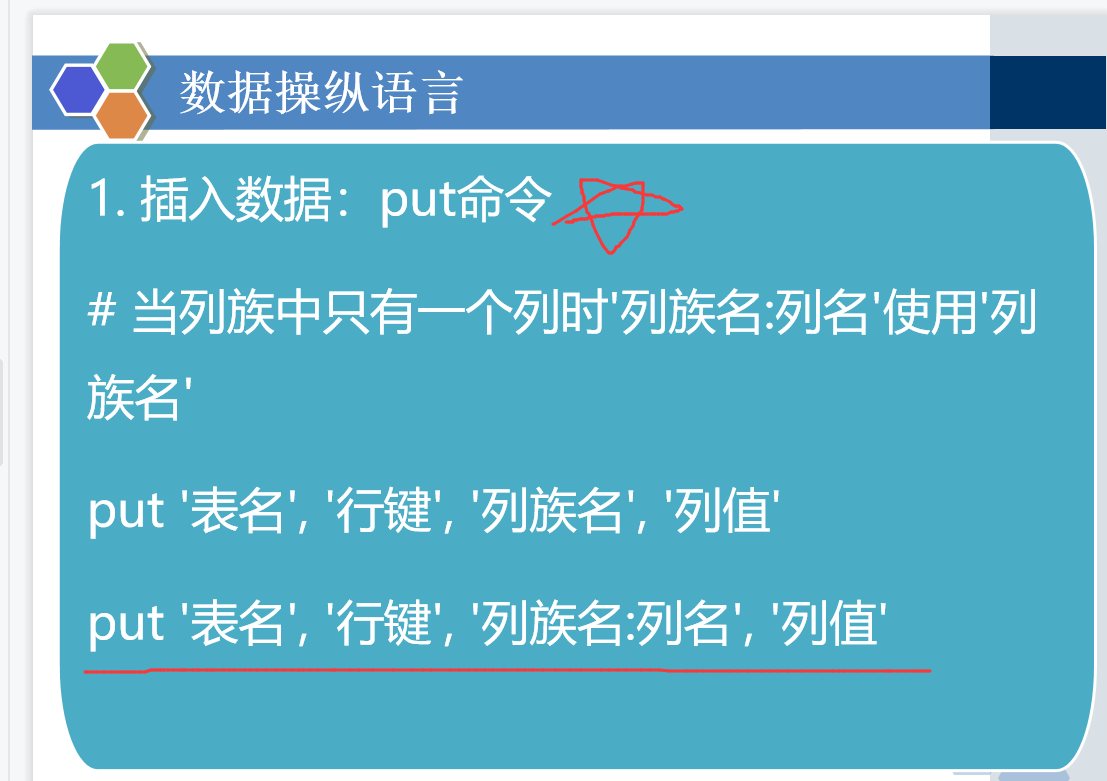
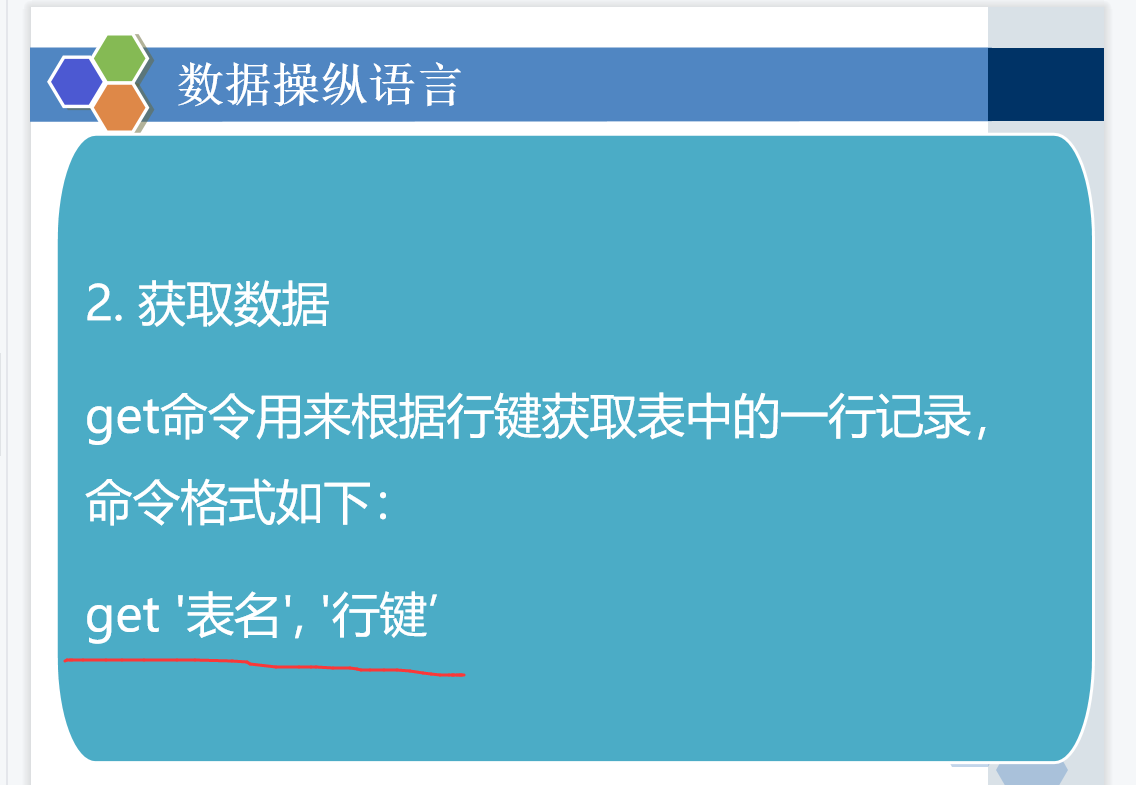
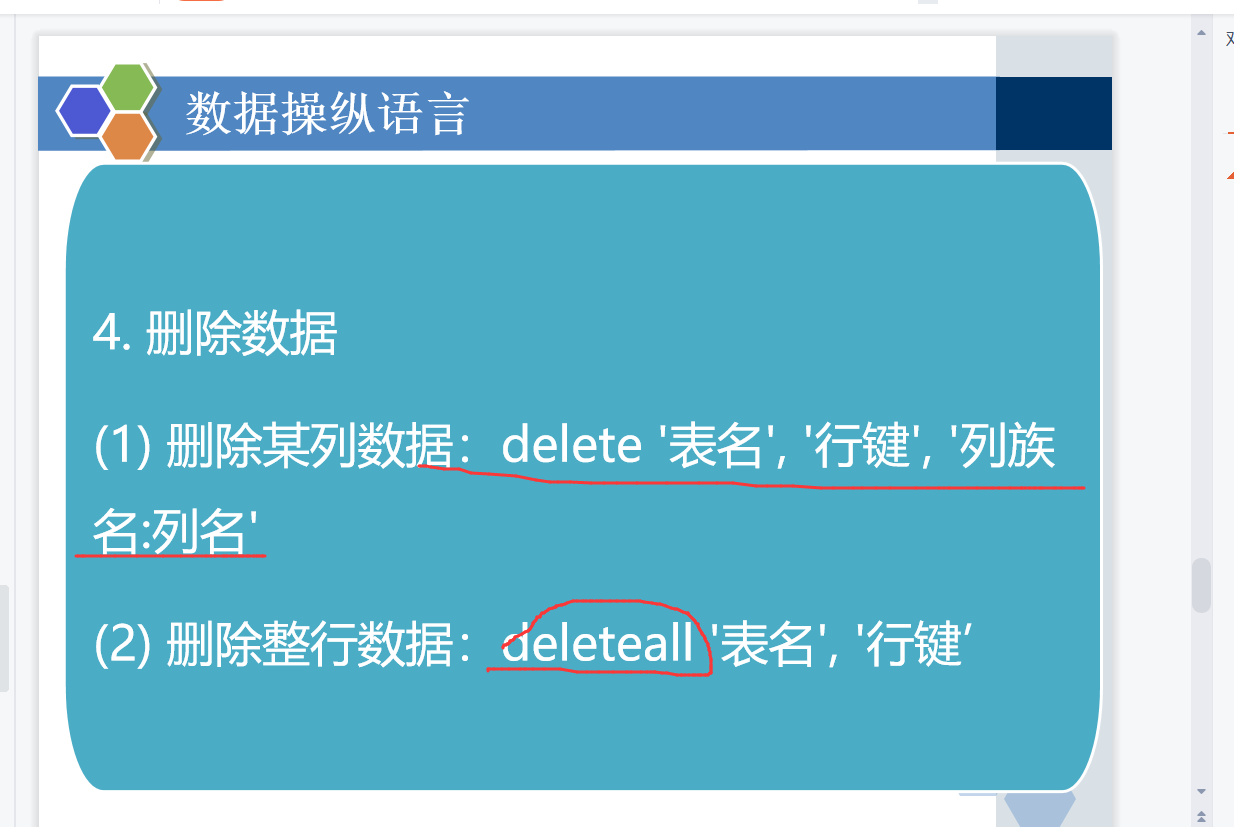
创建表,删除表,增删改查,
题目主要是老师给代码,自己写含义
问:Table table = connection.getTable(TableName.valueOf(“表名”))这句话是什么意思
从connection这个类里面利用getTable方法来获取table接口
实验课的时候实验报告,一定要好好看!!
第6章 客户端API.ppt
第七章
第八章
协处理器有那三种
- 观察者类型协处理器
- 端点类型协处理器
- 装载/卸载协处理器
第九章
Hbase性能调优有那两种

若有收获,就点个赞吧
0 人点赞
