@[toc]
一. 阿里外包必考题:
- HashMap的底层原理(搞定)
JDK1.7的 HashMap采用的是数组加单向链表的方式来实现
JDK1.8之后加入了红黑树,在链表长度大于8且储存总数大于64时,会转化为红黑树
HashMap内部主要有以下几个参数:- 默认大小:16,2的8次方,采用位运算赋值
- 最大容量:规定的触发rehash的数组大小,默认2的30次方
- 当前数据数:储存的node个数
- 加载因子:默认0.75,
- 阀值:默认12,加载因子*最大容量既触发rehash的node个数
HashMap主要是通过hash算法得到hashcode,再通过 & leng-1来分配储存的链表,这也是hashmap容量必须是2的n次方的原因,n次方减1的二进制末尾都是1111,那么任何数与它相与都会被截取末尾,等效于对lenth取模,但是性能比取模要高。
put方法原理:
- 对key进行hash的到hashcode,如果key=null会被存入table[0]中hashcode=0的位置
- 指定indexof方法,利用h& length-1确定分配到的链表,再调永add插入链表
- 判断key值和hashcode,如果有相等的会覆盖值
get方法原理:
- 指定hash和indexof方法,遍厉比较取值
resah原理:
HashMap的扩容采用遍厉头插法来实现。定一个新的队头节点为null,遍厉链表将节点依次提取出来,将提取出来的子节点作为父节点,子节点则是队头节点,然后将队头节点赋值为父节点。那么每次遍厉就相当于将子元素最为父节点,插入之前排序号的父节点。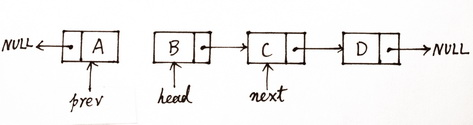
红黑树:
红黑树优点类似于二三树,二三数拥有2级和3级节点,3级节点在超过容量后会进行左旋和右旋升级成二级节点,红黑树也类似,只是用红色和黑色来表示节点,有以下特性
- 根节点是黑色的
- 每一个叶子节点都是黑色节点
- 非红既黑
- 红色节点子节点必须是黑色
- 完美黑色平衡,任意空链接到根结点的路径上的黑链接数量相同
红黑树只会在局部出现不平衡的现象,而且不会大于1层,比起二叉平衡树来说性能消耗更少。
和hashtable的区别:
线程不安全,可以储存null值,用位与取代取模,扩容大小不一样,最后table已经弃用了
- ConcurrentHashMap的底层原理(搞定)
ConcurrentHashMap是java提供的并发类容器,相对于同步类容器来说,它更注重程序的并发性能和安全。
JDK1.7之前,ConcurrentHashMap默认定义了16位的Segment数组并通过锁分离技术细化锁的粒度,减少线程并发,适用于读多写少的情况,写写互斥,写读互斥,读读共享。Segment类似于hashmap,其包含了一个HashEntry数组用来储存键值对。Segment继承了ReetrantLock重入锁并基于共享锁设计,支持重复度,而写锁的话基于互斥锁设计,做到读写互斥。默认的加载因子为0.75。
JDK1.8之后采用了类似hashmap的设计结构,给每个链表分配自旋锁来保证并发性能。 - ArrayList的底层原理(了解)
底层由hash数组实现,改查方便,增删需要移动数组 - LinkedList的底层原理(了解)
底层由双向链表实现,增删方便,改查需要遍厉链表 - 创建线程池的几种方式?线程池有什么好处,是怎么创建的?会给具体场景,让你怎么创建线程池,传入什么参数?(搞定)
- 什么是线程池?
为了避免重复创建和销毁线程,线程池维护着一系列的线程,实现了线程复用。 - 线程池的优点?
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性,可以定义有界和无界线程池,定时线程池等等 - 线程池如何创建?
- 可以利用concurrent包下的ThreadPoolExcutor创建自定义的线程池,可以传入的参数有 核心线程数,最大线程数,队列停留时间,时间单位,工作队列,拒绝策略。
- 如何根据具体场景创建对应线程?
- 可以根据性能指定核心线程数和最大线程数
- 如果线程过期后无效,可以设置队列过期时间来失效线程,
- 可以指定三种工作队列,按吞吐量从大到小,分别是ArrayBlockingQueue,数组定长的阻塞队列,适用于对系统负载敏感;LinkedBlockingQueue,单线链表无界阻塞队列,适用于对吞吐量和并发要求比较高的场景;SynchronousQueue ,序列化无元素的阻塞队列,每一次put对应一次take,高速创建线程,需要慎用,限制最大线程数
- 可以指定四种拒绝策略,按拒绝的程度从大到小,分别是 直接抛出异常,拒绝插入,拒绝插入并交由调用线程执行,尝试接收并抛弃队列中最老线程
- Excutor贴心地为我们封装了4个线程池,分别是:
- NewFixedThreadPool 核心线程数目和最大线程数目相等,没有等待时间,使用Linkedblocking作为工作队列,对CPU负载敏感而对内存不敏感,可以储存N多任务
- NewSingleThreadExecutor 核心和最大线程数都为1,使用无界队列,适用于异步顺序执行
- NewCachedThreadPool 超时并发线程池,默认60秒超时,使用SynchronousQueue,适用并发量特别大的场景
- NewScheduledThreadPool 固定大小的定时线程池,但是我们有更好的quarz定时任务框架可以使用
- 什么是线程池?
- SpirngIOC 和SpringAOP的理解
2种代理,增强通知,责任链,AOP织入 - 消息中间件 漏发问题,重复发问题积压了大量消息怎么办?生产者发送消息的时候挂了怎么办?消息接受者接收消息的时候挂了怎么办(搞定)?
- 为了保证消息在生产者正确发出,可以开启事务模式和comfirm监听模式,后者性能高10倍。
- 为了保证消息RabbitMQ有消费确认机制,只有消息被正确消费才会从队列中删除
- 为了保证队列中和正在接受的消息不丢失,支持对两者进行持久化。
- 如果消息队列中积压了大量消息怎么办?
- 一是保证消费者运行正常,然后停掉所有消费者
- 创建一条新主题分发模式的队列,容量为原队列的10倍
- 创建一个分发消费者,消费积压的消息,并重新写入主题队列
- 创建10倍的消费者消费这个主题队列中的消息
- 等积压消息处理的差不多后再恢复原先的架构
- jvm内存模型,GC,垃圾回收算法,oom什么时候遇到如何处理,双亲委派模型
- 索引,索引最左原则(索引的排列是有序的)
- 事务,传播机制,隔离级别,什么时候回滚
- 为什么用redis,数据类型,持久化机制,如何保证缓存和数据库的双写一致性,RDB和AOF持久化
- RDB持久化策略
优点:RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集,适合用来建立快照和容灾。
缺点:持久化整个数据集,消耗时间长,可能丢失大量数据 - AOF持久化策略
优点:类似于持续写入的log文件,可以设置不同的 持久化fsync 策略,比如无 fsync ,或者每次执行写入命令时 fsync ,默认每秒一次,拥有仅次于RDB良好的性能
缺点:储存的数据过于碎片化,文件更大,写入更慢,不利于容灾
- RDB持久化策略
- 设计秒杀场景如何实现?(搞定)
设计一个有时间限制的redis值,有效时间1秒用来表示秒杀A,设计一个长时间的redis变量B,用来表示是否强排成功。将所有对redis的取出操作插入消息队列中,一但被取出,则redis内的值删除,同时更改变量B为已拍下,此时终止对服务的请求,结束秒杀。 - 分布式事务如何解决?(搞定)
随着数据量的增大出现的分库分表,以及微服务分布式数据库,使得事务的维护变得越来越困难,当下主要有以下几种解决方案:- 定义一个全局事务处理器对所有的关联事务进行管理,在事务提交时先进行一次就绪提交,如果所有事务就绪就统一执行,否则回滚,这种处理对高并发非常不友好
- 利用补偿事务的方式来解决,针对事务可能出现的各种情况编写相对应的补偿策略,但是人力耗费大,而且难以定义复杂情况的补偿
- 利用消息队列的消息列表,每次执行事务都会通知其他事务同步执行,只有在消息队列中的所有消息被正确消费后事务才成功,否则失败,保证了数据的最终一致性。这是目前最好的解决方法,rabbitMQ和rocketMQ都提供了相关支持
二. 高并发
- 有多少访问量和QPS?
- 生产环境崩溃过吗?
- 做过压力测试么?
- 如何解决高并发超卖?
消息中间件+redis
三. 薪资

三. 面试真题:
不要重复发明轮子,但有时候你会需要一个方轮子。
- 你们分部式的单点登录是怎么实现的呢?
- SSO单点登录主要解决什么问题?
主要用来解决分部式系统的跨域登录问题,保证一个账户在多个系统上实现单一用户的登录。
稍大一些的网站,通常都会有好几个服务器,每个服务器运行着不同功能的模块,使用不同的二级域名,而一个整体性强的网站,用户系统是统一的,即一套用户名、密码在整个网站的各个模块中都是可以登录使用的,于是就有了session共享的需求。 - 你把所有的中心状态都放到redis缓存中去来,然后所有的应用都去访问他,那么权限怎么办呢?
前台配置了user拦截器,拦截业务请求,获取cookie并检查是否有 - 如果我伪装令牌你怎么办?万一我猜中了怎么办?那么我伪造cookies你怎么办?
头字符串拼接当前毫秒数拼接用户名,然后用md5加密,然后用base64加密(java8自带)
String ps = “JTTICKET“+System.currentTimeMillis()+user.getUsername();
String ps2 = DigestUtils.md5Hex(ps);
result=Base64.encodeBase64String(ps2.getBytes()); - 为什么要用dubbo?Zookepper是什么?除了做注 册中心,还能干其他事情么??
- solr搜索引擎??
- 如何建立索引?
- Connection有哪些子类?
- ArrayList去重?
- 第一种
遍历后放入set集合 - 第二种:创建新的集合,将重复元素去掉
- 创建新集合
- 根据传入的旧集合获取迭代器
- 遍历老集合
- 通过新集合判断是是否包含旧集合中的元素,如果包含,就不添加,如果不包含就添加
- 第一种
public static ArrayList getSingle(ArrayList list){ArrayList newList = new Arraylist(); //创建新集合Iterator it = list.iterator(); //根据传入的集合(旧集合)获取迭代器while(it.hasNext()){ //遍历老集合Object obj = it.next(); //记录每一个元素if(!newList.contains(obj)){ //如果新集合中不包含旧集合中的元素newList.add(obj); //将元素添加}}return newList;}
- Sql语句如何测试性能?
- Mycat的分库分表,会有什么问题?group by?索引?
- 项目中碰到的问题
- Tomcat
内存溢出或内存超过物理内存
默认最小1/64,最大1/4
修改bin目录下catalina.bat文件@echo off下追加
set JAVA_OPTS=-XX:PermSize=64M -XX:MaxPermSize=128m -Xms512m -Xmx1024m - Redis
Reidis缓存穿透
布隆过滤器,或者设null
Redis雪崩
- Session共享方案(引申)
1.粘性session
粘性session是指Ngnix每次都将同一用户的所有请求转发至同一台服务器上,即将用户与服务器绑定。
采用iphash的负载均衡策略
缺点:无法实现完美的负载均衡,而且服务器一旦宕机session就没了
2.服务器session复制
Tomcat的session共享机制
即每次session发生变化时,创建或者修改,就广播给所有集群中的服务器,使所有的服务器上的session相同。
缺点:传播本身就需要占用时间和贷款,当服务集群太大时,比如有100台,那么互相复制就会造成n*n的性能损耗
3 自己研发一套session高性能共享系统,
但是需要时间人力成本,所以不建议,如果你是BAT,随意~
4.session共享
缓存session,使用redis, memcached。
登录和注册都是以restful形式,redis设置好过期时间,实现面登录的过程
5.session持久化
将session存储至数据库中,像操作数据一样才做session。
首先mysql本身的访问压力就已经很大,session查询次数又太多,所以不推荐 - 什么是redis,项目中使用了什么数据格式?为什么可以当做缓存用,还有啥功能?
Redis是K-V结构的数据库,数据储存在内存中,支持多种数据类型String list set zset hash
内存的读取速度是非常快的,可以做到10w甚至100W的读写
而mysql这类的数据库的数据是保存在磁盘中的,如果要读取还要涉及到IO流的问题,所以速度有限
保存的是json格式的string字符串
还可以作为消息中间件,当做消息队列使用
因为redis可以储存list数据,通过linkedlist双向链表就可以实现消息队列 - 正则获取图片src路径
- 链表的倒序
现有一个单向链表Node,
内部有两个字段
已知原有的链表顺序为
head->node1->node2->node3->null
如何将链表逆序排列为
node3->node2->node1->head->null
- 第一:使用头插法,hashmap扩容就是使用的头插法,每次插入元素的next是之间的队列,也就是说每次插进来的元素都是头
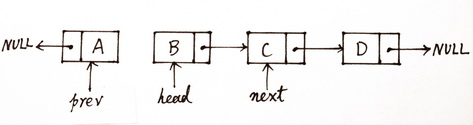
Node head = new Node("header");Node node1 = new Node("node1");Node node2 = new Node("node2");Node node3 = new Node("node3");head.setNext(node1);node1.setNext(node2);node2.setNext(node3);//head->node1->node2->node3Node newHead = null;while (null != head){ //遍历的关键,head表示旧队列Node next = head.getNext(); //提取下一级队列head.next = newHead; //将head作为队头,下一级置nullnewHead = head; //用newHead表示新的队列,指向head的地址head = next;//每次便利后将head旧队列指向next元素}
- 第二,可以使用递归的思想来实现,使用尾插法(层数高s性能低)
public function reverseNode(Node node){if (head == null || head.next == null) //阻止传入null,设置递归终止条件,头部为最后一个node节点,尾插法return head;Node temp = head.next; //保存子节点,也就是逆序后的父节点/********************逆序后*******************************/Node newList = reverse2(head.next); //新的列表,表头为原最后一个节点head.next = null; //父节点先置零 ,防止循环引用temp.next = head; //将父节点挂载在子节点的尾部return newList; //返回待排序好的列表,头部为子子节点}
- 根据场景写SQL

- exception异常会引起事务回滚吗?
不会,只有运行时异常会
四. 赛会通
1. 本地缓存列表如何实现
LRUMap 继承于AbstractLinkedMap ,是基于链表实现并使用LRU最近最少使用缓存淘汰列表的map。每次get都会使用头插法将元素调至表头,如果链表长度超过最大长度则删除链表最后一个元素。
由于LRUmap不支持并发操作,所以加上ReadWriteLock读写锁来保证并发性能。
至此,创建LocalLRUCache自定义缓存类,配置LRUMap ,最大缓存数量4096,ReadWriteLock,readLock,writeLock,定义get和put方法等可以用来保存数据
同时,为了兼容线上tair缓存,定一个了一个chacheManage接口。定义tair缓存实现类和local缓存实现类,同时可以对缓存命中率进行监控,打印日志,并且可以随时切换。
使用TimerTask,继承自Runnatural,定时打印缓存情况到日志中,方便监控。
2. tair缓存
一个Tair集群主要包括3个必选模块:config server、data server和client,以及一个可选模块:invalid server。
通常情况下,一个集群中包含2台configserver及多台dataServer。两台configserver互为主备并通过维护和dataserver之间的心跳获知集群中存活可用的dataserver,构建数据在集群中的分布信息(对照表)。dataserver负责数据的存储,并按照configserver的指示完成数据的复制和迁移工作。client在启动的时候,从configserver获取数据分布信息,根据数据分布信息和相应的dataserver交互完成用户的请求。invalidserver主要负责对等集群的删除和隐藏操作,保证对等集群的数据一致。
两台configserver互为主备,可以实现秒级替换,作为应用层接口管理dataServer储存,删除,迁移数据。
Client在启动的时候,从config server获取数据分布信息,根据数据分布信息和相应的data server交互完成用户的请求。 Invalid server主要负责对等集群的删除和隐藏操作,保证对等集群的数据一致。
如果出现两台服务器同时宕机的最恶劣情况,只要应用服务器没有新的变化,tair依然服务正常。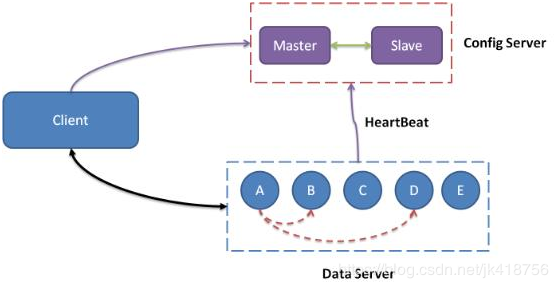
2.1 Tair的负载均衡
Tair的分布采用的是一致性哈希算法。对于所有的key,分配到Q个桶中,桶是负载均衡和数据迁移的基本单位。 Config server根据一定的策略把每个桶指派到不同的data server上。 因为数据按照key做hash算法,所以可以认为每个桶中的数据基本是平衡的,保证了桶分布的均衡性,就保证了数据分布的均衡性。
2.2 ConfigServer的功能
负责管理所有的data server, 维护data server,根据存活节点的信息来构建数据在集群中的分布表,调度dataserver之间的数据迁移、复制。
2.3 DataServer的功能
对外提供各种数据服务, 并以心跳的形式将自身状况汇报给config server。
增加或者减少data server的时候会发生什么?
config server负责重新计算一张新的桶在data server上的分布,并推送给dataserver完成数据的迁移
发生迁移的时候data server如何对外提供服务?
假设data server A 要把桶 3,4,5 迁移给data server B,现在3还没迁移,4正在迁移中,5已经迁移完成。
- 对3的操作不做改变还是请求A
- 对4的操作先请求A并记录log,等迁移后同步log到B
- 对5的操作会被转发给B
2.4 Tair的使用场景
- 单个数据大小不大不复杂,一般在KB级别,不超过1M
- 数据量很大,并且有较大的增长可能性,理论上可以无限扩容
- 支持给value填加序列号,防止ABA问题
招行面试
1. 你是如何保证代码尽少出错的?
- 理清楚需求,搞清楚业务和需求的细节再来开发,例如伪代码或者思维导图
- IDEA编辑器可以避免编译时错误
- 对虚拟机和java内存的了解可以避免出现一些运行时错误,
内存溢出(创建大量的线程,newFixedThreadPool)
数组下标越界(遍厉时删除,对数组的索引值为负数或大于等于数组大小时抛出)
空指针异常(调永null的方法)
运算溢出(Integer.Max+1) - 使用手头现有的较为优秀的工具类可以加快效率减少错误
比如HttpClientUtil,CookieUtil - 使用一些前人总结的设计模式,(使用阿里巴巴代码规范),加强可扩展性和健壮性
测试驱动开发,编写单元测试测试代码
我们公司的测试代码使用的时junit,仅仅测试dao层和service层
定一了一个基类,用来配置junit以及创建一些日志打印代码,同时依赖注入serivce或者dao,创建测色方法,填加@Test和@Rollback注解@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = {"classpath:applicationContext-webapp.xml"})public class BaseServiceTest extends AbstractTransactionalJUnit4SpringContextTests {//获取菜单对应的设置信息@Test@Rollback(false)public void testGetSasMenuBbsSetting(){}
每次git提交只能提交能够正常运行的代码,并且加好注释方便查找
- 代码审查,由经验较为丰富的程序员或者组长对提交的代码进行审查,防止出错
- 重构,在代码有bug或不能满足需求的情况下,进行重构
- 修改时重构
- 添加新模块时重构
- 审核代码时重构
- 事不过三三则重构
- 打印日志,线上测试机检测,查看是否有bug,如果有则进行复现,查明原因
private static final Logger logger =LoggerFactory.getLogger(HttpAsyncClientUtil.class);
2. 如何确保junit测试的结果正确
JAVA 1.4 引入了断言assert的概念,默认是不启动断言检查
assert true ; 断言通过assert false : "打印错误信息"; 断言失败,抛出AssertionError
断言会导致程序中断

若有收获,就点个赞吧
0 人点赞
