@[toc]
一. Dubbo RPC 分布式服务框架
Dubbo其实就是阿里提供的一个面向服务的SOA服务框架, 适合于小数据量大并发,消费者远大于生产者的情况。不适合传输文件视频(由于单一长链接限制于网络带宽,传输量有限)
之所以使用单一长链接,主要防止服务端被众多请求压跨,而且可以减少握手验证,解决C10K(单机1W连接)问题。
1. Dubbo的技术点
连接个数:单连接全双工
连接方式:长连接
传输协议:TCP
传输方式:NIO异步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。
适用场景:常规远程服务方法调用
为什么要消费者比提供者个数多?
因dubbo协议采用单一长连接小数据包的发送方式,在同样的带宽下每个服务者都可以建立多个对消费者连接
为什么采用异步单一长连接?
dubbo的每个服务者可能对应大量的消费者,如果像hessian一样使用多次短连接的话服务者很容易就被压跨。通过单一连接,保证单一消费者不会压死提供者,长连接,减少连接握手验证等,并使用异步IO,复用线程池,防止C10K问题。
Dubbo支持负载均衡吗?
Dubbo提供了四种负载均衡机制
- Random LoadBalance 根据权重随机调用,权重代表概率(默认)
- RoundRobin LoadBalance 根据权重轮巡调用,权重代表顺序
- LeastActive LoadBalance 根据响应速度分配,越快优先级越高
- ConsistentHash LoadBalance根据hash值分配,每个请求对应特定服务器
1. Dubbo的优点
- 不需要了解底层协议,像本地方法一样调
- 相对http协议来说,省略了无用的http请求头,
- 支持多种传输协议,包括dubbo,hessian,http等
- 高可用,自动更新服务清单,注册中心挂掉,本地也有缓存清单
- 负载均衡机制
- 心跳检测,默认60秒3次失效,保证长连接
- 提供完善的控制台,方便管理
1. 使用Zookeeper作为注册中心
Zookeeper维护者所有服务者的列表,消费者请求下载服务者列表后可以远程调用
特点:
- ZooKeeper 是一种分布式协调服务,储存结构类似树形文档,每个文党都有唯一的访问路径
- ZooKeeper的Watch实现了观察者模式,观察每个节点,一旦节点删除会发送异步通知给client,根据这个特性可以实现服务的注册与发现。
- Zookeeper拥有普通节点和顺序节点,临时节点和永久节点,临时节点的客户端断开后会被删除
ZooKeeper实现分布式锁:
分布式锁有三个概念
- 加锁
- 解锁
- 锁超时
引申出三个问题
- 为保证原子性,加锁和解锁必须一次性执行
- 要防止误删锁(锁超时)
- 为了防止锁超时,设置守护线程
顺序临时节点实现公平分布式锁
如果节点一正在访问,那么后续节点将利用Watch观察前一个节点等待他删除
如果节点一断开连接,那么他会被删除,解锁下一个节点的访问,实现有序访问
不需要担心锁超时,因为观察者一直在观察
二. Redis
Redis 原名Jedis,是用 C 语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止 Redis 支持的键值数据类型如下:
- String(字符串),
- hash(哈希),
- list(列表),
- set(集合),
- zset(有序集合)。
1. Redis和memecahce的区别
- redis支持丰富的数据格式,而memechache只支持字符串
- redis 支持数据持久化
- redis支持主从集群搭建
- redis支持单个value达到1GB,而memechache只有1M
- redis并不能保证高并发下的缓存一致性,而memechache使用cas来保证
- redis性能比 memechache略强
2. Redis 的应用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)
- 分布式集群架构中的 session 分离
- 聊天室的在线好友列表
- 任务队列(秒杀、抢购、12306 等等)
- 应用排行榜
- 网站访问统计
- 数据过期处理(可以精确到毫秒)
3. 哈希一致性
由于单台机器的内存有限,通常使用多台设备来进行扩容,设备退出后会导致整个系统无法使用
哈希一致性定一个2^32次方大小的桶,将每个key进行hash后存入桶内,每台redis服务器在桶上相当于一个节点,从节点往后到下一个服务器节点前的数据由本台redis负责储存。这样,等服务器退出后仅仅丢失了数据而不会由于hash错误导致整体崩溃。
由于每台设备的内存不同,为了平衡储存,出现了虚拟节点的概念,内存多的可以通过虚拟节点增加在hash桶上的范围,物尽其用,解决数据偏移。
- 均衡性: 尽可能的让数据信息均匀的落入到不同的节点中.添加虚拟节点的个数不唯一
- 单调性: 如果节点增加,会发生数据迁移,重新计算节点,如果减少节点迁移后会丢失数据,由于采用分部式操作,每个项目得知的节点数不一,生成的圆和hashcode也不一样,
- 分散性: 可能导致一个Key所保存的位置可以不唯一,这种特性叫分散性.
- 负载性: 可能导致同一个位置保存了多个key,由于redis的覆盖性,取值发生问题
4. Redis Sentinel哨兵 高可用集群
Redis可以通过 slaveof 来设置主从关系,一主两从,保持服务的健壮性。但是Redis的主从模式下,主节点一旦发生故障不能提供服务,需要人工干预,将从节点晋升为主节点,同时还需要修改客户端配置。 Sentinel(哨兵)架构解决了redis主从人工干预的问题,可以搭建Sentinel集群并使用投票协议(agreement protocols)来决定是否执行自动故 障迁移, 以及选择哪个从服务器作为新的主服务器,哨兵至少需要3个才能实现选举功能。
Sentinel主要负责下面三件事情:
- 监控(Monitoring): Sentinel 会不断地定期检查主从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时,可以利用API发送通知给管理员。
- 自动故障迁移(Automaticfailover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 主从互换,在主节点恢复后自动加入集群。
5. 持久化
RDB持久化的缺点
- 创建RDB文件需要将服务器所有的数据库的数据保存起来,这是一个非常耗费资源和时间的操作,所以服务器需要隔一段时间才创建一个新的RDB文件,也就是说,创建RDB文件的操作不能执行得过于频繁,否则就会严重得影响服务器性能。
- 相比而言,AOF持久化的巨大优势就是用户可以根据自己的需要对AOF持久化进行调整,让redis在遭遇意外停机时不丢失任何数据,或者只丢失一秒钟的数据。
6. 内存维护
- 超时
- 删除最不常用
- 超时中最不常用
- 最不常用排序超时删除
- 随机删除
7. 线上问题
7.1 缓存穿透
缓存穿透表示恶意用户模拟请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了数据库上,导致数据库异常。
解决方案:
布隆过滤器就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。具体应用就是将Redis中的key全部建立到布隆过滤器中, 每次请求先查询布隆过滤器; 如果存在,则放行, 毕竟布隆过滤器会有很少部分key会误算!
7.2 缓存雪崩
存在同一时间内大量键过期(失效),接着来的一大波请求瞬间都落在了数据库中导致连接异常。
解决方案:
- 缓存预热
- 分散缓存
- 服务限流
7.3 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决方案:
- 永不过期
7.4 缓存并发,多个线程
多个服务器高并发读取key的value值造成读后写的问题
解决方案:
- 加锁
- 给key拼接上时间
- 限流
三. Mybatis
Mybatis是一款优秀的数据持久层框架,主要负责数据的持久化以及ORM映射,底层
是对JDBC操作的一个封装和简化,不需要再一次次地注册驱动,获取连接
Mybatis优点:
(1)内置数据库连接池
(2)会自动进行结果集的ORM封装
(3)可以配置三级缓存
(4)Sql语句写在配置文件中,tk.mybatis甚至封装了大部分sql语句
Mybatis框架执行过程:
(1)配置mybatis的配置文件,mybatis-config.xml(名字不固定)
(2)通过配置文件,加载mybatis运行环境,创建SqlSessionFactory会话工厂,SqlSessionFactory在实际使用时按单例方式
(3)通过SqlSessionFactory创建sqlSession对象
(4)调用sqlSession的方法去操作数据执行sql语句。如果需要提交事务,需要执行SqlSession的commit()方法。
(5)释放资源,关闭sqlsession
1. ORM对象关系映射
Objec-Relational Mapping 对象关系映射是为了解决java面对对象模型和数据库关系模型互不匹配的技术,可以将数据库中数据和java数据和对象进行转换,本质上是一种数据形式的转换。
优点:
- 通过预先配置好的xml,可以很方便的按照java面对对象的方法操作数据库,而不用写一条条SQL语句
- 隐藏了数据访问细节,“封闭“的通用数据库交互
缺点:
- ORM作为面对对象和数据库之间的过度,依然需要数据库知识,增加了学习成本
- 自动化的映射带来了便利的同时也牺牲了一部分性能,这是不可调和的矛盾。现阶段框架的优化已经可以渐渐忽略这部分缺点
- 对于复杂查询的力不从心,虽然能够实现,但是相比sql语句来说花费的精力太大,性价比太低
2. 日志
Mybatis 的内置日志工厂提供日志功能,内置日志工厂将日志交给以下其中一种工具作代理:SLF4J,Log4j等等,通常这两个就足矣。
实现:
引入maven依赖后,填加log4j.properties,设置打印级别为debbug
3. 动态 SQL
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,以下是动态sql标签:
- if
类似于java的if - choose (when, otherwise)
类似于java的switch,可以解决if内语句如果不存在时出现错误的问题 - trim (where, set)
类似于数据库的where,而trim通过清除指定的两头字符保证遍历语句不会出错 - foreach
可以对java传过来的数组和集合进行遍厉 - sql
用来封装sql语句,多处复用
4. MyBatis中${}与#{}有什么不同?
相同点:
- 都属于mybatis表达式
- 都可以应用于mybatis映射文件
不同点:
#{}是预编译处理,${}是字符串替换。#{}运行时替换为?号,构建预编译的SQL,通常应用于where,having,limit等子句进行参数注入,并可以有效防止SQL注入。${}运行时执行的是字符串替换,通常应用于非条件查询子句中,例如order by。
5. MyBatis 一级缓存
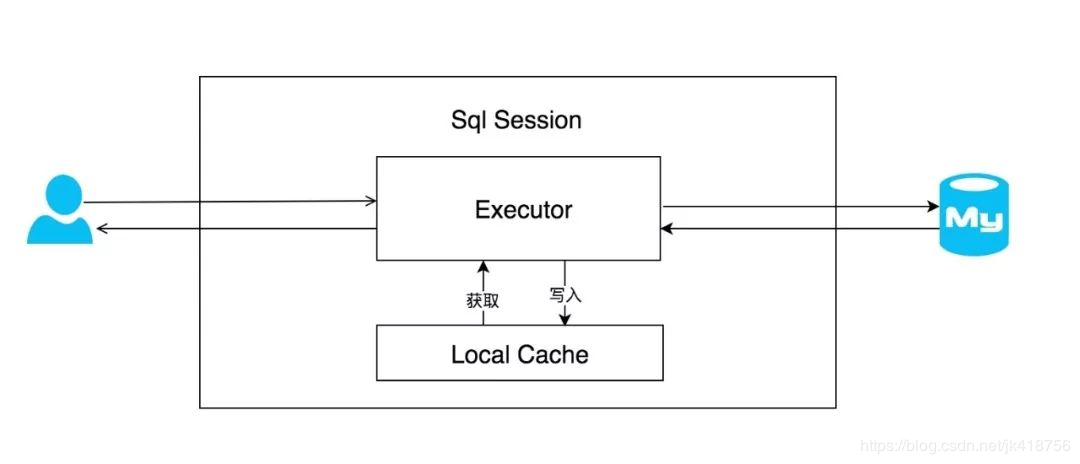
MyBatis一级缓存的生命周期和SqlSession一致。
MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
MyBatis的一级缓存最大范围是SqlSession内部,当有多个SqlSession或者分布式的环境下,执行数据库操作时可能会引起脏数据,建议设定缓存级别为Statement。
何时失效:
- 事务内部执行了insert,update,delete操作时一级缓存自动失效.
- 不是同一个sqlsession
- 缓存级别为Statement
6. MyBatis 二级缓存
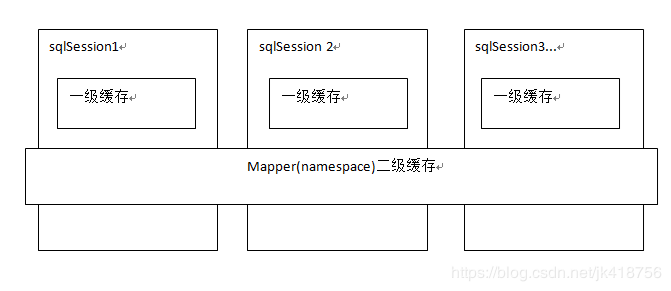
如果多个SqlSession之间需要共享缓存,则需要使用到二级缓存。二级缓存需要手动开启,开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询。二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
存在的问题:
MyBatis的二级缓存是基于Mapper的,如果有别的Mapper对数据进行了增删改,会导致脏数据
在分布式环境下直接使用Redis,Memcached等分布式缓存可能成本更低,安全性也更高。
7. MyBatis 框架应用中常用的设计模式?
- 建造模式 (SqlSessionFactoryBuilder)
- 工厂模式 (SqlSessionFactory)
- 代理模式 (JDK,CGLIB)
- 装饰模式 (new CacheExecutor(simpleExecutor))
- 策略模式 (Cache: LruCache,FifoCache,….)
- 模板方法 (BaseExecutor)
四. 消息中间件
1. MQ 是什么?有什么作用?
MQ 我们可以理解为消息队列,队列我们可以理解为管道。以管道的方式做消息传递。消息中间件设计的初衷是用来通讯的,但是现在主要将它应用在减少并发的异步通信上,缓解并发,起到削峰填谷的作用,使用消息队列的话同时实际上也实现了程序的解耦,同时也可以用来解决redis的缓存一致性,以及分布式事务的一致性管理。
2. 市面上有许多消息队列,如何选选型?**
现在主流的MQ有很多,比如ActiveMQ、RabbitMQ、RocketMQ、Kafka等,
kafka性能好,但是丢失消息过多不考虑
ActiveMQ技术太老性能跟不上,官方维护少
最后的选型在RabbitMQ和RocketMQ之间
RabbitMQ
如果服务规模比较小,可以考虑采用RabbitMQ
优点:
- 使用基于并发的erlang语言开发,mq 性能较好,高并发
- 多语言适配
- 社区活跃度高,方便问题的排查和解决
缺点:
- 语言不通二次开发难度大
- 吞吐量优先,在万级左右
RocketMQ
阿里巴巴使用的java消息队列,经过双十一的考验,同时也是SpringCloud Aliaba的推荐消息队列
RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
优点:
- 吞吐量10万+, 支持10亿级别的消息堆积,不会因为堆积导致性能下降
- 支持分布式架构和分布式事务
- 配置简单,有阿里使用手册
缺点:
- 社区活跃度不够
3. RabbitMQ消息队列
RabbitMQ中采用了生产者-消费者设计模式,用来实现程序之间的解耦,异步通信,同时减少并发。
RabbitMQ是基于通道连接的,或者说基于队列连接的,多个消费者可以连接一个队列或管道。
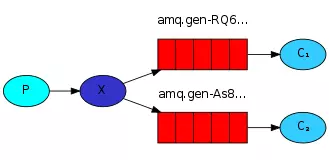
- Queue 队列
RabbitMQ中的消息都只能存储在Queue中,生产者(下图中的P)生产消息并最终投递到Queue中,消费者(下图中的C)可以从Queue中获取消息并消费。- acknowledgment 消息确认机制
消费者受到消息后如果未处理完毕就宕机会导致消息的丢失,所以RabbitMQ要求消费者在消费完消息后发送一个确认回执给队列,然后才会删除队列中的消息。仅当消费者没有发回确认,且RabbitMQ连接断开的情况下,队列才会将消息发送给其他消费者处理。
这里会产生另外一个问题,如果我们的开发人员忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑… - Prefetch count 预读数
Queue中的消息如果被平摊地发给多个消费者,由于消费者处理消息的速度不一样,可能导致空闲和忙碌的情况。对于处理慢的消费者,可以通过设置Prefetch count,规定每次发送N条消息,处理完毕后才会继续发送。
- acknowledgment 消息确认机制
- Exchange 交换器
生产者并不会直接将消息投递到Queue,而是会用过交换器来绑定Queue发送- routing key 路由key
生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则。 - Binding key 绑定key
在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key;当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。Binding key依赖于Exchange Type,fanout下失效。 - Exchange Type 交换器工作模型
RabbitMQ常用的Exchange Type有fanout、direct、topic、headers这四种,下面分别进行介绍。- fanout 展开模式
它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
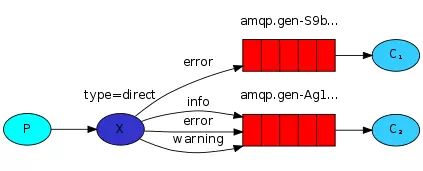
- direct 指向模式
它会把消息发送到对应路由key的Queue中。
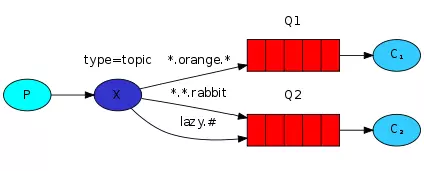
- topic 主题模式
它是direct模式的加强,将路由key按“.”分割为一个个主题,只有符合主题的队列才会发送,同时支持模糊匹配,其中“”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)**
- header 主题模式
将键值对保存在 header中,匹配键值对相同的队列
- fanout 展开模式
- routing key 路由key
- RabbitMQ 五种工作模式
RabbitMQ 通常来说有五种工作模式- 简单模式 :生产者-队列-消费者 单线模式
- 工作队列模式 :一个生产者对应多个消费者
- 发布/订阅模式 :假如了交换机,可以为交换机指定对应的消费者
- 路由模式 :可以通过路由key发送给交换机中指定的消费者
- 主题模式根据 :用“.” 将路由key划分为不同主机,发送给交换机中的指定消费者
五. Nginx
1. 什么是 Nginx
Nginx 是一款高性能的 HTTP 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器, 运行稳定且资源消耗低。
2. Nginx 的应用场景
- HTTP 服务器:Nginx 是一个 HTTP 服务可以独立提供 HTTP 服务。可以做网页静态服务器。
- 虚拟主机:可以实现在一台服务器虚拟出多个网站。例如个人网站使用的虚拟主机。
- 反向代理:负载均衡:可以通过反向代理搭建负载均衡的集群。
3. 什么是反向代理?
- 正向代理指的是客户端通过代理来请求资源
- 反向代理指的是服务端通过代理返回资源
4. Nginx的配置文件结构
Nginx的配置文件nginx.conf位于其安装目录的conf目录下。
nginx.conf由多个块组成,最外面的块是main,main包含Events和HTTP,HTTP包含upstream和多个Server,Server又包含多个location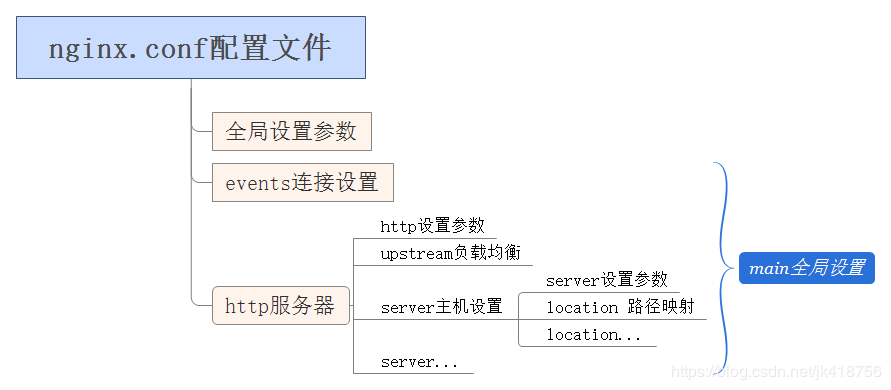
- main块:全局设置,设置的指令将影响其他所有设置;
- server块:主机设置,指令主要用于指定主机和端口;
- upstream块:负载均衡服务器设置,指令主要用于server的负载均衡配置
- location块:用于url路径映射
4.1 全局参数设置
//全局参数配置user nobody nobody; //运行用户和用户组worker_processes 1; // 开启进程数,默认1,不建议修改error_log logs/error.log notice; //日志级别pid logs/nginx.pid; //指定pid的储存文件位置worker_rlimit_nofile 65535; //最大打开文件数,不推荐作限制,影响并发events{...}
- user:指定Nginx Worker进程运行用户以及用户组,默认由nobody账号运行。
- worker_processes :指定了Nginx要开启的进程数,默认1不用改,否则建议指定和CPU的数量一致即可。
- error_log:用来定义全局错误日志文件。日志输出级别有debug、info、notice、warn、error、crit可供选择,其中,debug输出日志最为最详细,而crit输出日志最少。
- pid:用来指定进程pid的存储文件位置。
- worker_rlimit_nofile:最大打开文件数,不推荐限制
4.2 events全局连接设置
events{use epoll;worker_connections 65536;}
- use:用来指定Nginx的工作模式。Nginx支持的工作模式有select、poll、kqueue、epoll、rtsig和/dev/poll。其中select和poll都是标准的工作模式,kqueue和epoll是高效的工作模式,不同的是epoll用在Linux平台上,而kqueue用在BSD系统中。对于Linux系统,epoll工作模式是首选。
- worker_connections:用于定义Nginx每个进程的最大连接数,默认是1024。最大客户端连接数由worker_processes和worker_connections决定,即Max_client=worker_processesworker_connections。
在作为反向代理时,max_clients变为:max_clients = worker_processes worker_connections/4。
进程的最大连接数受Linux系统进程的最大打开文件数限制,在执行操作系统命令“ulimit -n 65536”后worker_connections的设置才能生效
4.3 http服务器
http {//http参数include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;...//负载均衡设置upstream webapp-tomcat {server 127.0.0.1:8080 weight=1 max_fails=2 fail_timeout=30s;server 127.0.0.1:8081 weight=1 max_fails=2 fail_timeout=30s;}//一个个server服务器server {...}...
4.3.1 http参数设置
include conf/mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] ''"$request" $status $bytes_sent ''"$http_referer" "$http_user_agent" ''"$gzip_ratio"';log_format download '$remote_addr - $remote_user [$time_local] ''"$request" $status $bytes_sent ''"$http_referer" "$http_user_agent" ''"$http_range" "$sent_http_content_range"';client_max_body_size 20m;client_header_buffer_size 32K;large_client_header_buffers 4 32k;Sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 60;client_header_timeout 10;client_body_timeout 10;send_timeout 10;
- include:实现对配置文件所包含的文件的设定,可以减少主配置文件的复杂度。
- default_type属于HTTP核心模块指令,这里设定默认类型为二进制流,也就是当文件类型未定义时使用这种方式,例如在没有配置PHP环境时,Nginx是不予解析的,此时,用浏览器访问PHP文件就会出现下载窗口。
4.3.2 upstream负载均衡
4.3.3 server服务器
listen用于指定虚拟主机的服务端口,
server_name用来指定IP地址或者域名,多个域名之间用空格分 开。
index用于设定访问的默认首页地址,root指令用于指定虚拟主机的网页根目录,这个目录可以是相对路径,也可以是绝对路径。
Charset用于 设置网页的默认编码格式。
access_log用来指定此虚拟主机的访问日志存放路径,
最后的main用于指定访问日志的输出格式。
4.3.3.1 location映射
六. docker
Docker 是一种近年来流行的虚拟化技术,利用docker容器化引擎,可以很方便地搭建微服务网络。
组成:
- 镜像 用于创建 Docker 容器的模板。
- 容器 容器是独立运行的一个或一组应用。
- 仓库 保存镜像的仓库
好处:
- 每个容器共享而不是独占系统资源
- 直接运行于宿主内核而不是模拟,启动速度快
- 可以快速构建一致的运行环境
- 一次创建,到处运行,支持上千个容器
docker可以配置数据卷,来代替容器中的目录
docker可以通过dockerFile文件创建指定镜像
docker compose是官方开源项目,用来定义和运行多个docker容器。
通过docker-compose.yml文件快速创建容器
version: "3.1"services:itoken-zipkin:restart: alwaysimage: 106.12.8.40:5000/itoken-zipkincontainer_name: itoken-zipkinports:- 9411:9411networks:- zipkin_network

若有收获,就点个赞吧
0 人点赞
