一. 为什么要有本地缓存?
在系统中,有些数据,数据量小,但是访问十分频繁(例如国家标准行政区域数据),针对这种场景,需要将数据搞到应用的本地缓存中,以提升系统的访问效率,减少无谓的数据库访问(数据库访问占用数据库连接,同时网络消耗比较大),但是有一点需要注意,就是缓存的占用空间以及缓存的失效策略。
为什么是本地缓存,而不是分布式的集群缓存?
目前的数据,大多是业务无关的小数据缓存,没有必要搞分布式的集群缓存,目前涉及到订单和商品的数据,会直接走DB进行请求,再加上分布式缓存的构建,集群维护成本比较高,不太适合紧急的业务项目。
使用场景
- 你愿意消耗一部分内存来提升速度;
- 你已经预料某些值会被多次调用;
- 缓存数据不会超过内存总量;
局限性
- 本地缓存的对象储存在JVM内存中,当储存的元素为对象时,就算没有put,对象内的成员也可以被修改
- 在高并发下无法保证最终一致性,需要实现缓存同步
- 受限于本地内存,影响GC回收
二 实现方式
1. Apache下的LRUMap+ReentrantreadWriteLock
1.1 LRUMap简介
LRUMap是org.apache.commons.collections4.map包提供的使用LRU(最近最少使用)缓存维护策略的map。
继承树: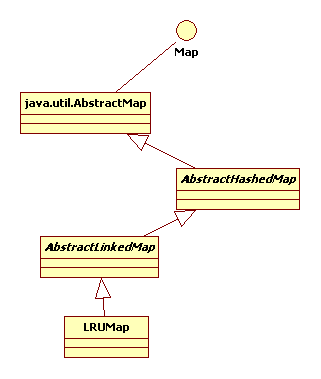
LRUMap继承自AbstractHashedMap,结构类似HashMap,维护着一个HashEntry的双向链表
工作流程:**
- put采用头插法来添加元素,每个元素插入链表后都位于链表头部。
- get方法会将元素将链表中取出置于链表头部,这样链表的头部储存的就是最近使用的元素。
- 当链表容量满时,直接删除队列最后一个元素,实现LRU算法
缺陷:
LRUMap仅仅实现了LRU算法以及map储存,不能保证并发情况下的安全,可以使用LinkedHashMap,synchronized或者ReentrantreadWriteLock重入读写锁来实现线程安全,本文仅仅介绍第三个,性能最好。
1.2 源码实现
。。。。
1.4 适用场景
- 通过接口解耦后,线下使用本地缓存,线上使用tair,redis等,避免干扰
- 并发
2. 谷歌Guava包下的CacheBuilder
Guva是google开源的一个公共java库,类似于Apache Commons,它提供了集合,反射,缓存,科学计算,xml,io等一些工具类库。cache只是其中的一个模块。使用Guva cache能够方便快速的构建本地缓存。
Guava Cache与ConcurrentMap很相似,但也不完全一样。最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。相对地,Guava Cache为了限制内存占用,通常都设定为自动回收元素。基于ConcurrentHashMap的优秀设计借鉴,在高并发场景支持线程安全,使用Reference引用命令,保证了GC的可回收到相应的数据,有效节省空间;同时write链和access链的设计,能更灵活、高效的实现多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等;
数据结构图
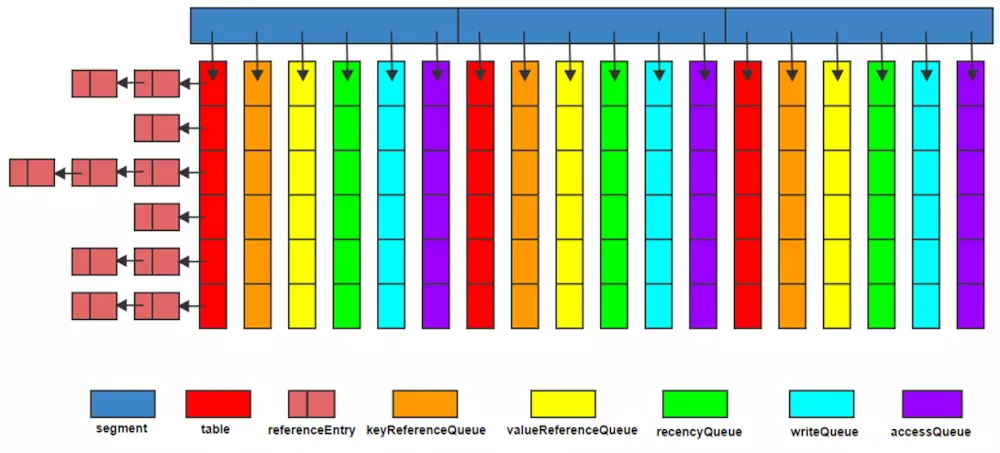
2.1 Pom文件
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>25.0-jre</version></dependency>
2.2 使用Guava构建第一个缓存
Guava的缓存有许多配置选项,所以为了简化缓的创建过程,使用了Builder设计模式;Builder使用的是链式编程的思想,也就是每次调用方法后返回的是对象本生,这样可以极大的简化配置过程。
// 通过CacheBuilder构建一个缓存实例Cache<String, String> cache = CacheBuilder.newBuilder().maximumSize(100) // 设置缓存的最大容量.expireAfterWrite(1, TimeUnit.MINUTES) // 设置缓存在写入一分钟后失效.concurrencyLevel(10) // 设置并发级别为10.recordStats() // 开启缓存统计.build();// 放入缓存cache.put("key", "value");// 获取缓存String value = cache.getIfPresent("key");
2.3 Cache与LoadingCache
使用CacheBuilder我们能构建出两种类型的cache,他们分别是Cache与LoadingCache。
Cache
Cache是通过CacheBuilder的build()方法构建,它是Gauva提供的最基本的缓存接口,并且它提供了一些常用的缓存
Cache<Object, Object> cache = CacheBuilder.newBuilder().build();// 放入/覆盖一个缓存cache.put("k1", "v1");// 获取一个缓存,如果该缓存不存在则返回一个null值Object value = cache.getIfPresent("k1");// 获取缓存,当缓存不存在时,则通Callable进行加载并返回。该操作是原子Object getValue = cache.get("k1", new Callable<Object>() {@Overridepublic Object call() throws Exception {return null;}});
LoadingCache**(推荐使用)
LoadingCache继承自Cache,在构建LoadingCache时,需要通过CacheBuilder的build(CacheLoader<? super K1, V1> loader)**方法,传入一个自定义的匿名内部类LoadingCache,它能够通过CacheLoader自发的加载缓存
public static final LoadingCache<String, ConcurrentHashMap<String, Object>> context = CacheBuilder.newBuilder().build(new CacheLoader<String, ConcurrentHashMap<String, Object>>() {@Overridepublic ConcurrentHashMap load(String key) throws Exception {// 缓存加载逻辑,返回类型可以任意指定return new ConcurrentHashMap();}});// 获取缓存,当缓存不存在时,会通过CacheLoader自动加载,该方法会抛出ExecutionException异常loadingCache.get("k1");// 推荐使用:以不安全的方式获取缓存,当缓存不存在时,会通过CacheLoader自动加载,该方法不会抛出异常loadingCache.getUnchecked("k1");
2.4 缓存的构建参数
2.4.1 并发级别
Guava提供了设置并发级别的api,使得缓存支持并发的写入和读取。同ConcurrentHashMap类似Guava cache的并发也是通过分离锁实现。在一般情况下,将并发级别设置为服务器cpu核心数是一个比较不错的选择。
CacheBuilder.newBuilder()// 设置并发级别为cpu核心数.concurrencyLevel(Runtime.getRuntime().availableProcessors()).build();
2.4.2 初始容量
我们在构建缓存时可以为缓存设置一个合理大小初始容量,由于Guava的缓存使用了分离锁的机制,扩容的代价非常昂贵。所以合理的初始容量能够减少缓存容器的扩容次数。
CacheBuilder.newBuilder()// 设置初始容量为100.initialCapacity(100).build();
2.4.3 缓存的回收
在构建本地缓存时,我们应该指定一个最大容量来防止出现内存溢出的情况。在guava中除了提供基于数量,基于内存容量,基于引用的回收外,还可以通过api主动回收。
基于数量**(常用)**
基于最大数量的回收策略非常简单,我们只需指定缓存的最大数量maximumSize即可:
CacheBuilder.newBuilder().maximumSize(100) // 缓存数量上限为100.build();
基于容量
使用基于最大容量的的回收策略时,我们需要设置2个必要参数:
- maximumWeigh;用于指定最大容量。
- Weigher;在加载缓存时用于计算缓存容量大小。
当缓存的最大数量/容量逼近或超过我们所设置的最大值时,Guava就会使用LRU算法对之前的缓存进行回收。
CacheBuilder.newBuilder().maximumWeight(1024 * 1024 * 1024) // 设置最大容量为 1M// 设置用来计算缓存容量的Weigher.weigher(new Weigher<String, String>() {@Overridepublic int weigh(String key, String value) {return key.getBytes().length + value.getBytes().length;}}).build();
基于引用**(不推荐)**
基于引用的回收策略,是java中独有的。在java中有对象自动回收机制,依据程序员创建对象的方式不同,将对象由强到弱分为强引用、软引用、弱引用、虚引用。对于这几种引用他们有以下区别:
- 强引用
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。
Object o=new Object(); // 强引用
当内存空间不足,垃圾回收器不会自动回收一个被引用的强引用对象,而是会直接抛出OutOfMemoryError错误,使程序异常终止。
- 软引用
相对于强引用,软引用是一种不稳定的引用方式,如果一个对象具有软引用,当内存充足时,GC不会主动回收软引用对象,而当内存不足时软引用对象就会被回收。
SoftReference<Object> softRef=new SoftReference<Object>(new Object()); // 软引用Object object = softRef.get(); // 获取软引用
使用软引用能防止内存泄露,增强程序的健壮性。但是一定要做好null检测。
- 弱引用
弱引用是一种比软引用更不稳定的引用方式,因为无论内存是否充足,弱引用对象都有可能被回收。
WeakReference<Object> weakRef = new WeakReference<Object>(new Object()); // 弱引用Object obj = weakRef.get(); // 获取弱引用
- 虚引用
而虚引用这种引用方式就是形同虚设,因为如果一个对象仅持有虚引用,那么它就和没有任何引用一样。在实践中也几乎没有使用。
在Guava cache中支持,软/弱引用的缓存回收方式。使用这种方式能够极大的提高内存的利用率,并且不会出现内存溢出的异常。
CacheBuilder.newBuilder().weakKeys() // 使用弱引用存储键。当键没有其它(强或软)引用时,该缓存可能会被回收。.weakValues() // 使用弱引用存储值。当值没有其它(强或软)引用时,该缓存可能会被回收。.softValues() // 使用软引用存储值。当内存不足并且该值其它强引用引用时,该缓存就会被回收.build();
通过软/弱引用的回收方式,相当于将缓存回收任务交给了GC,使得缓存的命中率变得十分的不稳定,在非必要的情况下,还是推荐基于数量和容量的回收。
显式回收
guava cache拥有自动回收机制,并不是缓存项过期起马上清理掉,而是在读或写的时候做少量的维护工作,这样做的原因在于:如果要自动地持续清理缓存,就必须有一个线程,这个线程会和用户操作竞争共享锁。此外,某些环境下线程创建可能受限制,这样CacheBuilder就不可用了。
guava cache把选择权交到你手里。如果你的缓存是高吞吐的,那就无需担心缓存的维护和清理等工作。如果你的缓存只会偶尔有写操作,而你又不想清理工作阻碍了读操作,那么可以创建自己的维护线程,以固定的时间间隔调用api回收。ScheduledExecutorService可以帮助你很好地实现这样的定时调度。(注意,cleanUp()只回过期缓存)
// 构建一个缓存Cache<String, String> cache = CacheBuilder.newBuilder().build();// 回收key为k1的缓存cache.invalidate("k1");// 批量回收key为k1、k2的缓存List<String> needInvalidateKeys = new ArrayList<>();needInvalidateKeys.add("k1");needInvalidateKeys.add("k2");cache.invalidateAll(needInvalidateKeys);// 回收所有缓存cache.invalidateAll();// 回收过期缓存cache.cleanUp();
2.4.4 缓存过期策略
缓存的过期策略分为固定时间和相对时间。
固定时间**一般是指写入后多长时间过期**,例如我们构建一个写入10分钟后过期的缓存:
CacheBuilder.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES) // 写入10分钟后过期.build();// java8后可以使用Duration设置CacheBuilder.newBuilder().expireAfterWrite(Duration.ofMinutes(10)).build();
相对时间**一般是相对于访问时间,也就是每次访问后,会重新刷新该缓存的过期时间**,这有点类似于servlet中的session过期时间,例如构建一个在10分钟内未访问则过期的缓存:
CacheBuilder.newBuilder().expireAfterAccess(10, TimeUnit.MINUTES) //在10分钟内未访问则过期.build();// java8后可以使用Duration设置CacheBuilder.newBuilder().expireAfterAccess(Duration.ofMinutes(10)).build();
2.4.5 缓存刷新策略
在Guava cache中支持定时刷新和显式刷新两种方式
定时刷新
只有LoadingCache能够进行定时刷新。在进行缓存定时刷新时,我们需要指定缓存的刷新间隔,和一个用来加载缓存的CacheLoader,当达到刷新时间间隔后,下一次获取缓存时,会调用CacheLoader的load方法刷新缓存。例如构建个刷新频率为10分钟的缓存:
CacheBuilder.newBuilder()// 设置缓存在写入10分钟后,通过CacheLoader的load方法进行刷新.refreshAfterWrite(10, TimeUnit.SECONDS)// jdk8以后可以使用 Duration// .refreshAfterWrite(Duration.ofMinutes(10)).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {// 缓存加载逻辑...}});
显式刷新
在缓存构建完毕后,我们可以通过Cache提供的一些借口方法,显式的对缓存进行刷新覆盖,例如:
// 构建一个缓存Cache<String, String> cache = CacheBuilder.newBuilder().build();// 使用put进行覆盖刷新cache.put("k1", "v1");// 使用Map的put方法进行覆盖刷新cache.asMap().put("k1", "v1");// 使用Map的putAll方法进行批量覆盖刷新Map<String,String> needRefreshs = new HashMap<>();needRefreshs.put("k1", "v1");cache.asMap().putAll(needRefreshs);// 使用ConcurrentMap的replace方法进行覆盖刷新cache.asMap().replace("k1", "v1");
对于LoadingCache,由于它能够自动的加载缓存,所以在进行刷新时,不需要显式的传入缓存的值:
LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder().build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {// 缓存加载逻辑return null;}});// loadingCache 在进行刷新时无需显式的传入 valueloadingCache.refresh("k1");
2.4.6 移除监听器
移除缓存的时候所触发的监听器,RemovalListener抛出的任何异常都会在记录到日志后被丢弃
LoadingCache<K , V> cache = CacheBuilder.newBuilder().removalListener(new RemovalListener<K, V>(){@Overridepublic void onRemoval(RemovalNotification<K, V> notification) {System.out.println(notification.getKey()+"被移除");}})
2.5 asMap视图
asMap视图提供了缓存的ConcurrentMap形式,但asMap视图与缓存的交互需要注意:
- cache.asMap()包含当前所有加载到缓存的项。因此相应地,cache.asMap().keySet()包含当前所有已加载键;
- asMap().get(key)实质上等同于cache.getIfPresent(key),而且不会引起缓存项的加载。这和Map的语义约定一致。
所有读写操作都会重置相关缓存项的访问时间,包括Cache.asMap().get(Object)方法和Cache.asMap().put(K, V)方法,但不包括Cache.asMap().containsKey(Object)方法,也不包括在Cache.asMap()的集合视图上的操作。比如,遍历Cache.asMap().entrySet()不会重置缓存项的读取时间。
2.6 统计
guava cache为我们实现统计功能,这在其它缓存工具里面还是很少有的。
CacheBuilder.recordStats()用来开启Guava Cache的统计功能。统计打开后, Cache.stats()方法会返回CacheStats对象以提供如下统计信息:
- hitRate():缓存命中率;
- averageLoadPenalty():加载新值的平均时间,单位为纳秒;
- evictionCount():缓存项被回收的总数,不包括显式清除。
此外,还有其他很多统计信息。这些统计信息对于调整缓存设置是至关重要的,在性能要求高的应用中我们建议密切关注这些数据, 这里我们就不一一介绍了。
3. Ehcache集群缓存框架(鸡肋)
ehcache直接在jvm虚拟机中缓存,速度快,效率高;但是缓存共享麻烦,集群分布式应用不方便。
redis是通过socket访问到缓存服务,效率比ecache低,比数据库要快很多,处理集群和分布式缓存方便,有成熟的方案。
上有redis和tair,下有guava cache ,个人感觉略显积累,只适用于特定场景。

若有收获,就点个赞吧
0 人点赞
