基本图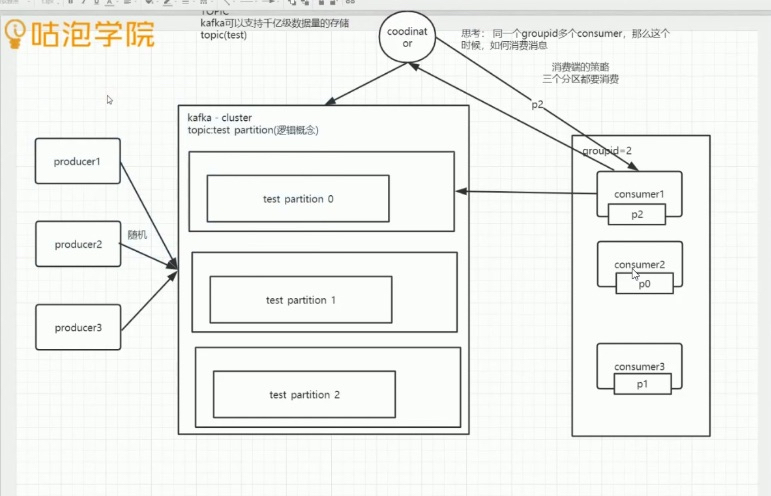
Kafka 吞吐量大
一个topic 多个 partition
思考题:
1、同一个groupId 多个consumer ,那个这个时候如何消费
2、当consumer个数发生变动时候,这个时候又是如何分配partition做消费
kafka 没有读写分离,因为如果做读写分离的话,需要保证follower的数据强一致性
kafka通过ISR(哪个follower 与leader数据保持的一致性最高) 来做leader选举
数据同步
follower 通过pull 长轮询(阻塞式,阻塞时间可以设置)的方式去同步leader的数据
LEO(log end offset)
HW (hihg water),代表follower中同步最慢的那台机器保存的消息位置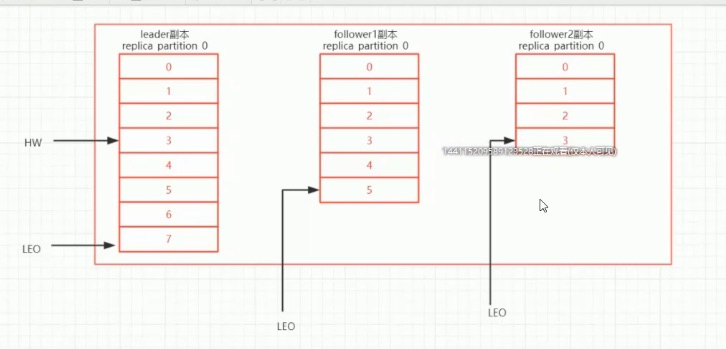
kafka
发送消息
ack应答 0 : 风险最大,数据丢失
1:只需要leader返回1就行
-1: 需要所有follower都返回应答
leader 选举
从ISR集合中获取优先副本(数据可靠性比较高的副本)
数据持久化
磁盘(kafka,rocketMq)
主要为 ,index .log .timeindex
数据分段存储,分段存储的数据量可以在config里面进行配置
一个分段中包含 0000.index, 0000.log, 00000*.timeindex 文件的命名: 上一个logsegement 的最后一个offset+1,增加检索效率(二分查找)
磁盘存储
顺序
页缓存(mysql/kafka/rocketMq),频繁的访问(热点数据),也就是我们常说的内存
刷盘策略(同步刷盘,异步刷盘)
零拷贝
传统: 内核空间-> 用户空间->内核空间
零拷贝: 内核空间->(linux:sendFile) 内核空间
.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
ISR:In-Sync Replicas 副本同步队列
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
.kafka follower如何与leader同步数据
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差
什么情况下一个 broker 会从 isr中踢出去
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 ,如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
kafka 为什么那么快
- Cache Filesystem Cache PageCache缓存
- 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
- Zero-copy 零拷技术减少拷贝次数
- Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
- Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符
kafka producer如何优化打入速度
- 增加线程
- 提高 batch.size
- 增加更多 producer 实例
- 增加 partition 数
- 设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
- 跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置
kafka producer 打数据,ack 为 0, 1, -1 的时候代表啥, 设置 -1 的时候,什么情况下,leader 会认为一条消息 commit了
- 1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
- 0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了
Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1、消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
- 0—-表示不进行消息接收是否成功的确认;
- 1—-表示当Leader接收成功时确认;
- -1—-表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2、消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
- Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
- High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“诡异”的消失了;
解决办法:
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
https://blog.csdn.net/qq_28900249/article/details/90346599

若有收获,就点个赞吧
0 人点赞
