ConcurrentHashMap的实现原理
在JDK8中,ConcurrentHashMap的底层数据结构与HashMap一样,也是采用“数组+链表+红黑树”的形式。同时,它又采用锁定头节点的方式降低了锁粒度,以较低的性能代价实现了线程安全。底层数据结构的逻辑可以参考HashMap的实现,下面我重点介绍它的线程安全的实现机制。
- 初始化数组或头节点时,ConcurrentHashMap并没有加锁,而是CAS的方式进行原子替换(原子操作,基于Unsafe类的原子操作API)。
- 插入数据时会进行加锁处理,但锁定的不是整个数组,而是槽中的头节点。所以,ConcurrentHashMap中锁的粒度是槽,而不是整个数组,并发的性能很好。
- 扩容时会进行加锁处理,锁定的仍然是头节点。并且,支持多个线程同时对数组扩容,提高并发能力。每个线程需先以CAS操作抢任务,争抢一段连续槽位的数据转移权。抢到任务后,该线程会锁定槽内的头节点,然后将链表或树中的数据迁移到新的数组里。
- 查找数据时并不会加锁,所以性能很好。另外,在扩容的过程中,依然可以支持查找操作。如果某个槽还未进行迁移,则直接可以从旧数组里找到数据。如果某个槽已经迁移完毕,但是整个扩容还没结束,则扩容线程会创建一个转发节点存入旧数组,届时查找线程根据转发节点的提示,从新数组中找到目标数据。
加分回答
ConcurrentHashMap实现线程安全的难点在于多线程并发扩容,即当一个线程在插入数据时,若发现数组正在扩容,那么它就会立即参与扩容操作,完成扩容后再插入数据到新数组。在扩容的时候,多个线程共同分担数据迁移任务,每个线程负责的迁移数量是 (数组长度 >>> 3) / CPU核心数。
也就是说,为线程分配的迁移任务,是充分考虑了硬件的处理能力的。多个线程依据硬件的处理能力,平均分摊一部分槽的迁移工作。另外,如果计算出来的迁移数量小于16,则强制将其改为16,这是考虑到目前服务器领域主流的CPU运行速度,每次处理的任务过少,对于CPU的算力也是一种浪费。
JDK7
Segment (基于ReentrantLock的扩展实现) 默认16 锁粒度为Segment
Unsafe获取对应Segment,进行线程安全的put操作
size()锁定所有的Segment计算总值,性能差。采用重试机制(RETRIES_BEFORE_LOCK,指定重
试次数 2),获取可靠值。如果没有监控到发生变化(通过对比Segment.modCount),就直接返回,否则获取锁进行操作。
JDK8
锁粒度为hash对应链表头Node(put采用尾部插入), 采用lazy-load形式(有效避免初始开销)
数据存储利用volatile保证可见性
使用 CAS 等操作,在特定场景进行无锁并发操作。
使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。
舍弃ReentrantLock,采用synchronized(JDK不断优化,性能差异小,减少内存消耗)
Unsafe优化: tabAt 就是直接利用 getObjectAcquire,避免间接调用的开销
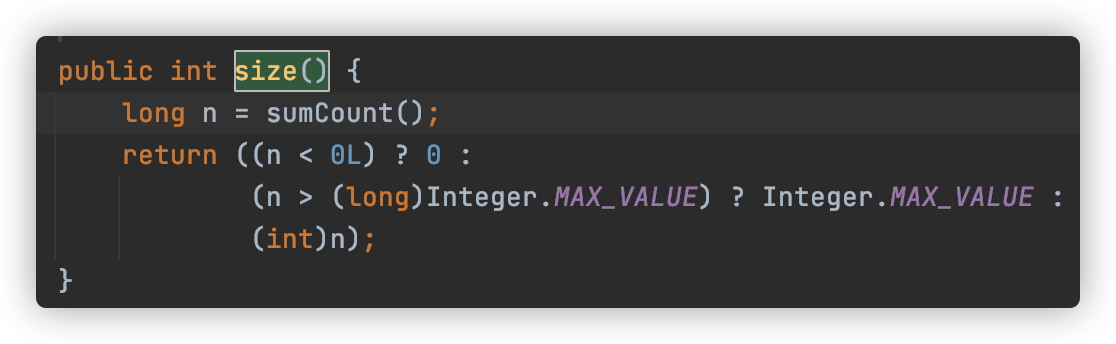
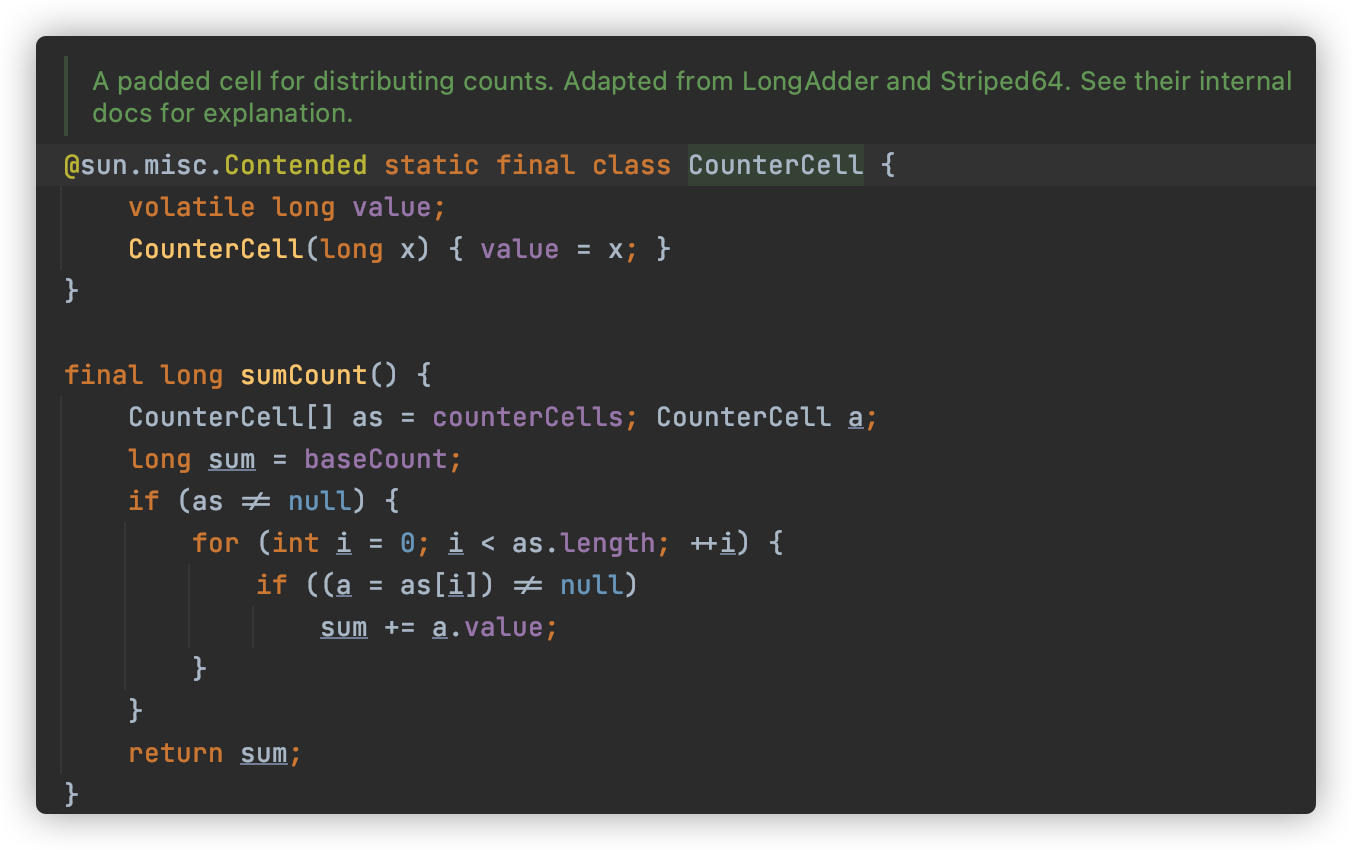
size()分而治之的进行计数,然后求和处理。CounterCell 的操作,是基于 java.util.concurrent.atomic.LongAdder 进行的,是一种 JVM 利用空间换取更高效率的方法,利用了Striped64内部的复杂逻辑。
源码解析
Node
//代表 table 的地址是 volatile,而不是数组 元素是 volatile。//这处是为了使得 table 在扩容时对其他线程也保持可见性。transient volatile Node<K,V>[] table;static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;Node(int hash, K key, V val, Node<K,V> next) {this.hash = hash;this.key = key;this.val = val;this.next = next;}}
get
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 计算 hash 值int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 读取首节点的 Node 元素if ((eh = e.hash) == h) {// 如果 Key 相等则直接返回首节点if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// eh(hash 值)为负值表示正在扩容,这个时候查的是 ForwardingNode 的 find 方法来定位到 nextTable 来// eh=-1,说明该节点是一个 ForwardingNode,正在迁移,此时调用 ForwardingNode 的 find 方法去 nextTable 里找。// eh=-2,说明该节点是一个 TreeBin,此时调用 TreeBin 的 find 方法遍历红黑树, 由于红黑树有可能正在旋转变色,// 所以 find 里会有读写锁。// eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {// 直接在链表遍历查询if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;}
put
final V putVal(K key, V value, boolean onlyIfAbsent) {// 1 key 和 value 不能为 null。if (key == null || value == null) throw new NullPointerException();// 2 通过 spread 函数获取 hash 值(与 HashMap 类似,也加入了扰动)int hash = spread(key.hashCode());//用来计算在这个桶总共有多少元素,用来控制扩容或者转换为红 黑树。int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 3 table 为空,则先初始化数组。if (tab == null || (n = tab.length) == 0)tab = initTable();// 4 如果 table 对应位置为空,则调用 CAS 插入相应的数据,注意这个地方没有加锁。else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 5 如果取出来的节点的 hash 值是 MOVED(-1)的话,则表示当前正在对这个数组// 进行扩容,复制到新的数组,则当前线程也去帮助复制。else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;// 6 如果这个位置有元素的话,则对该节点加 synchronized 锁。synchronized (f) {if (tabAt(tab, i) == f) {// 7 如果是链表的话(hash 大于 0),就对这个链表的所有元素进行 遍历。if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;// 8 若找到 Key 和 Key 的 hash 值都一样的节点,则用新 的 value 值替换旧值。if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}// 9 若没有找到相同 Key 节点的话,则在链表后面添加新 的节点。Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 10 当前桶的数据结构为红黑树时,调用 putTreeVal 方法将元素 添加到树中。else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 11 当在同一个节点的数目达到 TREEIFY_THRESHOLD(8)个的时候,则扩张 数组或将给节点的数据转为树。if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}// 12 执行 addCount()方法尝试更新元素个数 baseCount。addCount(1L, binCount);return null;}

若有收获,就点个赞吧
0 人点赞
