项目需求分析
采集平台
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
离线/实时需求
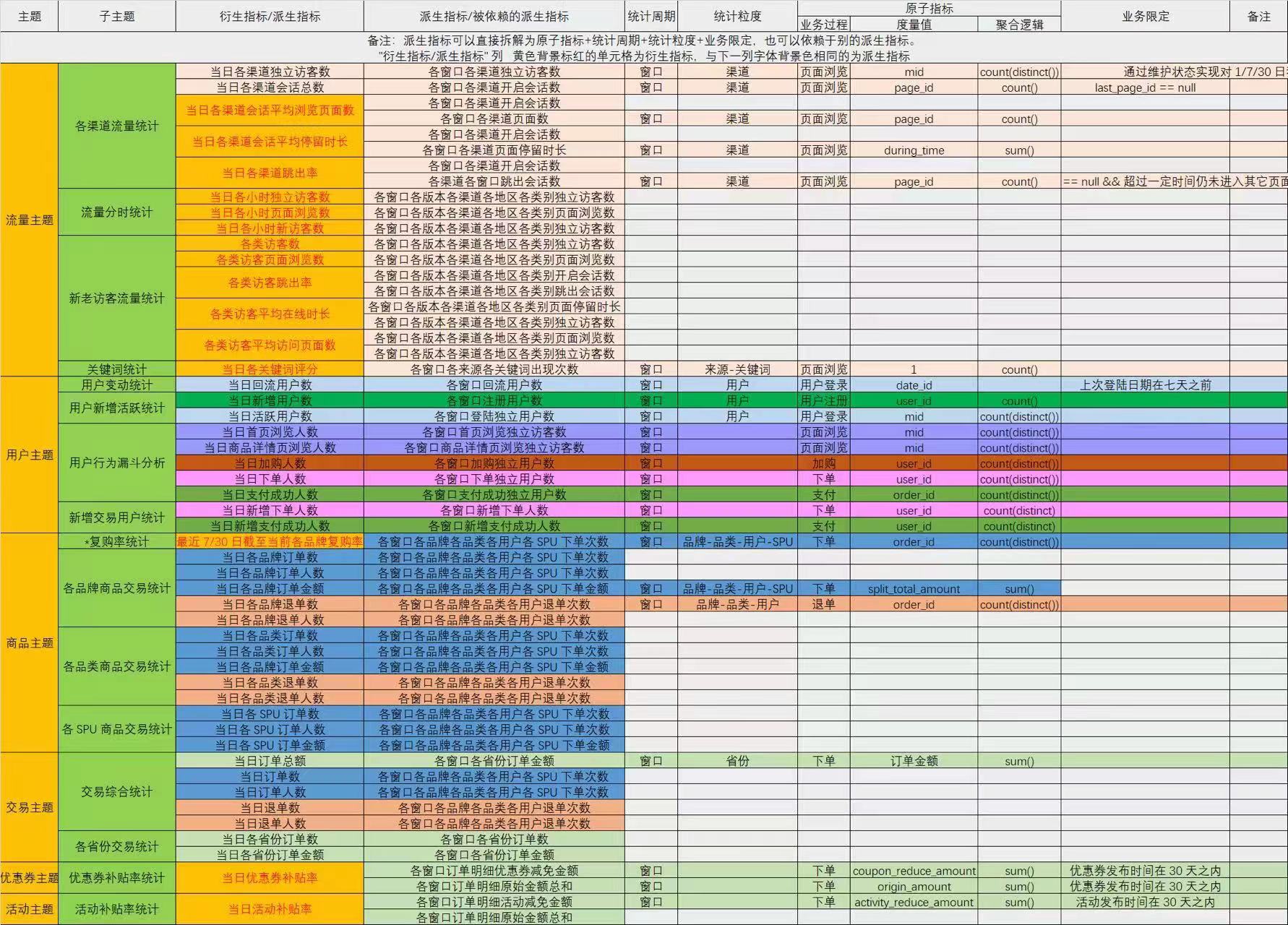
离线和实时需求的指标是一样的,只不过计算的层面由Hive on Spark 换成了Flink
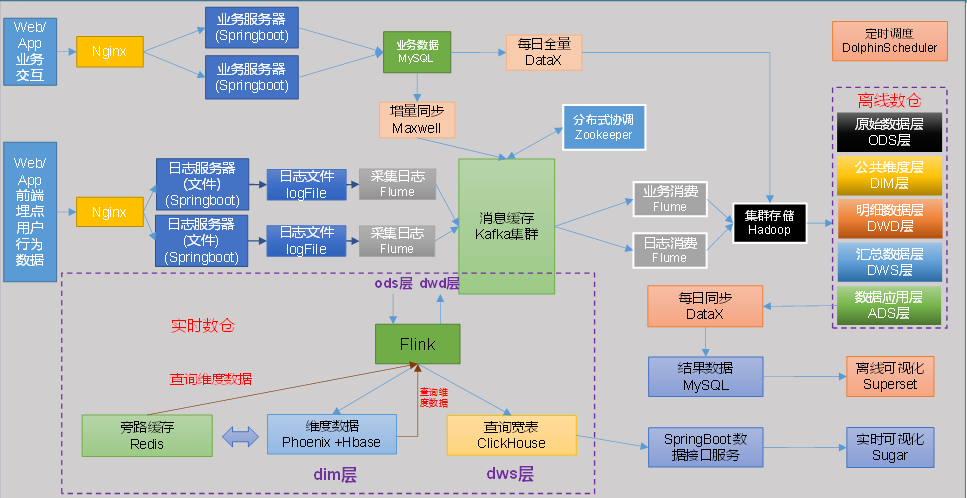
技术选型

项目流程图
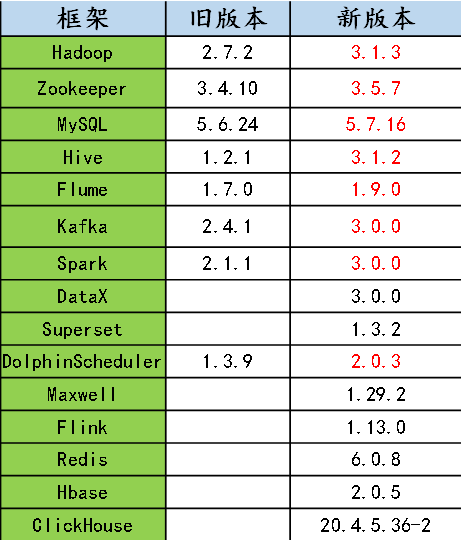
框架版本选型

具体的版本型号
服务器选型

集群规模
假设每台服务器8T磁盘,128G内存
1,每天日活用户100w ,每人一天平均100条: 100w * 100条 = 1亿条
2,每条日志1k左右,每天1亿条 :1亿/1024/1024 = 约为100G
3,半年内不扩充服务器来算:100G * 180天 = 约 18T
4,保存3副本 :18T*3 = 54T
5,预留20%-30%Buf = 54T/0.7 = 77T
6,总共约 8T * 10台 服务器
集群资源规划设计
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
1**)生产集群**
(1)消耗内存的分开
(2)数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
(3)客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(例如:Hive和mysql)
| Master | Master | core | core | core | common | common | common |
|---|---|---|---|---|---|---|---|
| nn | nn | dn | dn | dn | JournalNode | JournalNode | JournalNode |
| rm | rm | nm | nm | nm | |||
| zk | zk | zk | |||||
| hive | hive | hive | hive | hive | |||
| kafka | kafka | kafka | |||||
| spark | spark | spark | spark | spark | |||
| datax | datax | datax | datax | datax | |||
| Ds-master | Ds-master | Ds-worker | Ds-worker | Ds-worker | |||
| maxwell | |||||||
| supset | |||||||
| mysql | |||||||
| flume | flume | ||||||
| flink | flink | ||||||
| clickhouse | |||||||
| redis | |||||||
| hbase |
2)测试集群服务器规划
| 服务名称 | 子服务 | 服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume (消费Kafka日志) |
Flume | √ | ||
| Flume (消费Kafka业务) |
Flume | √ | ||
| Hive | √ | √ | √ | |
| MySQL | MySQL | √ | ||
| DataX | √ | √ | √ | |
| Spark | √ | √ | √ | |
| DolphinScheduler | ApiApplicationServer | √ | ||
| AlertServer | √ | |||
| MasterServer | √ | |||
| WorkerServer | √ | √ | √ | |
| LoggerServer | √ | √ | √ | |
| Superset | Superset | √ | ||
| Flink | √ | |||
| ClickHouse | √ | |||
| Redis | √ | |||
| Hbase | √ | |||
| 服务数总计 | 20 | 11 | 12 |

若有收获,就点个赞吧
0 人点赞
