DIM层
读取数据:Kafka---topic_db(包含所有的46张业务表)
过滤数据:过滤出所需要的维表数据
过滤条件:在代码中给定十几张维表的表名问题:如果增加维表,需要修改代码-重新编译-打包-上传、重启任务优化1:不修改代码、只重启任务配置信息中保存需要的维表信息,配置信息只在程序启动的时候加载一次优化2:不修改代码、不重启任务方向:让程序在启动以后还可以获取配置信息中增加的内容具体实施:1) 定时任务:每隔一段时间加载一次配置信息将定时任务写在Open方法2) 监控配置信息:一旦配置信息增加了数据,可以立马获取到(1) MySQLBinlog:FlinkCDC监控直接创建流a.将配置信息处理成广播流:缺点 -> 如果配置信息过大,冗余太多b.按照表名进行KeyBy处理:缺点 -> 有可能产生数据倾斜(2) 文件:Flume->Kafka->Flink消费创建流写出数据:将数据写出到PhoenixJdbcSink、自定义Sink
DIM层设计要点:
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储在HBase 表中
DIM 层表是用于维度关联的,要通过主键去获取相关维度信息,这种场景下 K-V 类型数据库的效率较高。常见的 K-V 类型数据库有 Redis、HBase,而 Redis 的数据常驻内存,会给内存造成较大压力,因而选用 HBase 存储维度数据。
(3)DIM层表名的命名规范为dim_表名
主要任务
接收Kafka数据,过滤空值数据
对Maxwell抓取的数据进行ETL,有用的部分保留,没用的过滤掉。
动态拆分维度表功能
由于Maxwell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个维度表拆开处理。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL等。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张维度表表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。这种可以有三个方案实现:
一种是用Zookeeper存储,通过Watch感知数据变化; 另一种是用mysql数据库存储,周期性的同步; 再一种是用mysql数据库存储,使用广播流。这里选择第三种方案,主要是MySQL对于配置数据初始化和维护管理,使用FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
所以就有了如下图:
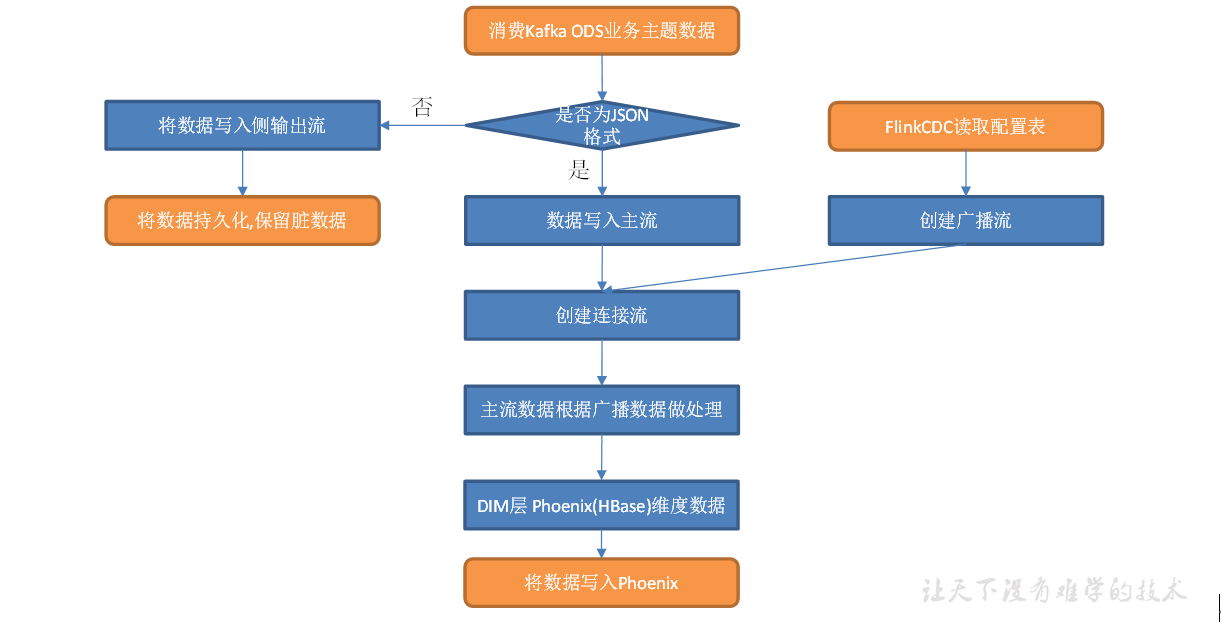
把流中的数据保存到对应的维度表
维度数据保存到HBase的表中。

若有收获,就点个赞吧
0 人点赞
