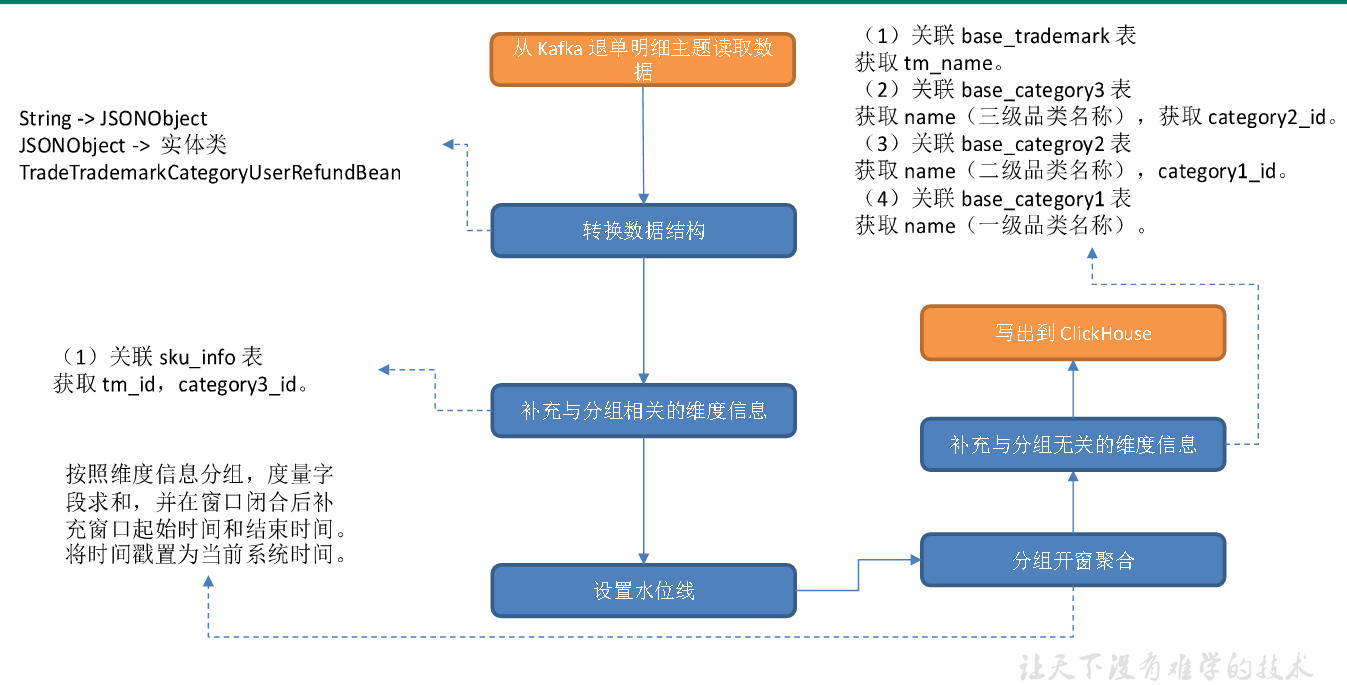
主要任务
从Kafka 读取退单明细数据,过滤null 数据并按照唯一键对数据去重,关联维度信息,按照维度分组,统计各维度各窗口的订单数和订单金额,将数据写入ClickHouse 交易域品牌-品类-用户粒度退单各窗口汇总表。
思路分析
1)从 Kafka 退单明细主题读取数据
2**)转换数据结构**
JSONObject 转换为实体类TradeTrademarkCategoryUserRefundBean。
3**)补充与分组相关的维度信息**
关联sku_info 表获取tm_id,category3_id。
4**)设置水位线**
5**)分组、开窗、聚合**
按照维度信息分组,度量字段求和,并在窗口闭合后补充窗口起始时间和结束时间。将时间戳置为当前系统时间。
6**)补充与分组无关的维度信息**
(1)关联base_trademark 表
获取tm_name。(2)关联base_category3 表获取name(三级品类名称),获取 category2_id。(3)关联base_categroy2 表获取name(二级品类名称),category1_id。
(4)关联base_category1 表
获取name(一级品类名称)。
7**)写出到ClickHouse。**
图解
ClickHouse 建表语句
启动ClickHouse
systemctl start clickhouse
systemctl start clickhouse-server
clickhouse-client -m
drop table if exists dws_trade_trademark_category_user_refund_window;create table if not exists dws_trade_trademark_category_user_refund_window(stt DateTime,edt DateTime,trademark_id String,trademark_name String,category1_id String,category1_name String,category2_id String,category2_name String,category3_id String,category3_name String,user_id String,refund_count UInt64,ts UInt64) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt, trademark_id, trademark_name, category1_id,category1_name, category2_id, category2_name, category3_id, category3_name, user_id);
代码
(1)实体类 TradeTrademarkCategoryUserRefundBean
(2)主程序
测试
开启hadoop,zookeeper,hbase,phoenix,kafka,maxwell,redis,clickhouse
启动redis 命令 :redis-cli -h hadoop102 —raw
依次启动如下两个类
DwdTradeOrderRefund,DwsTradeTrademarkCategoryUserRefundWindow(Phoenix(HBase-HDFS、ZK)、Redis) -> ClickHouse(ZK)修改配置文件(当日)

查看数据
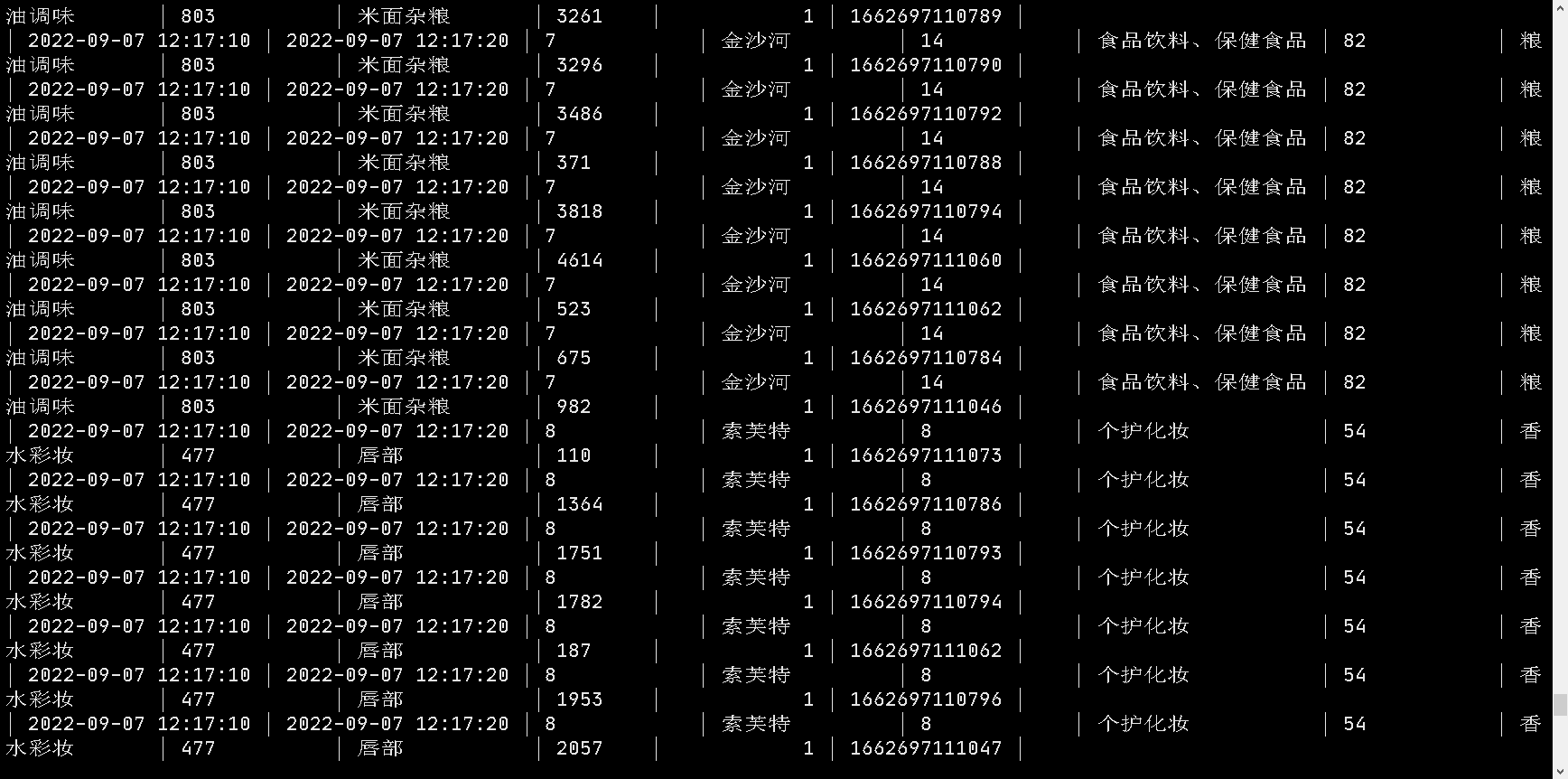
有如上图数据,则程序成功!

若有收获,就点个赞吧
0 人点赞
