DWS层设计要点:
(1)DWS层的设计参考指标体系;
(2)DWS层表名的命名规范为dws数据域统计粒度业务过程统计周期(window)
注:window 表示窗口对应的时间范围。
开窗之后,连接操作更快,数据量少,数据库存储的数据量降低
主要任务
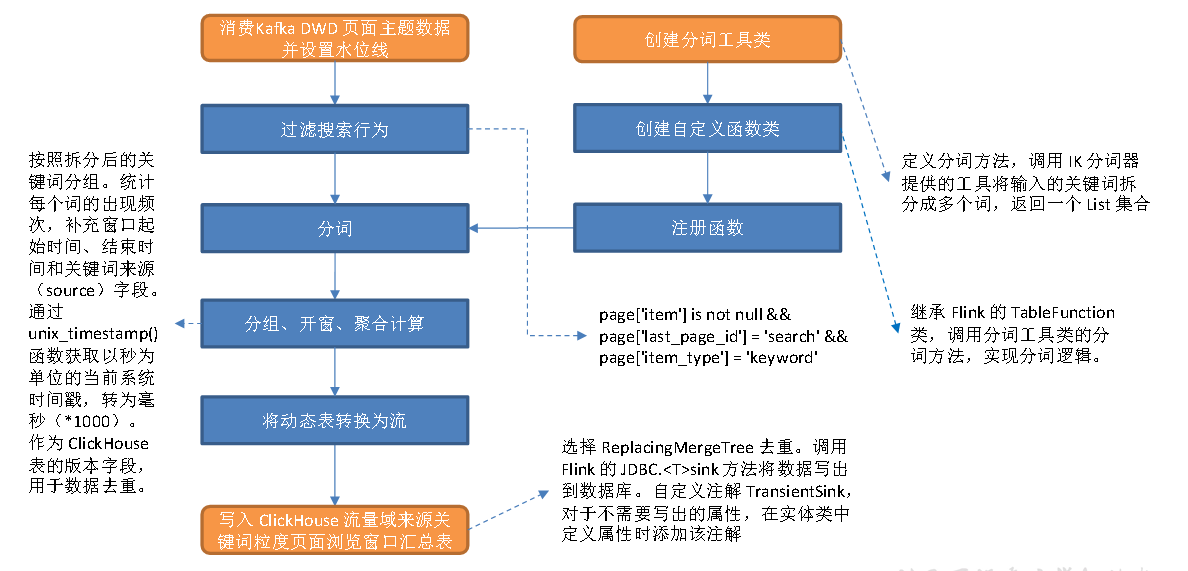
从Kafka 页面浏览明细主题读取数据,过滤搜索行为,使用自定义UDTF(一进多出)函数对搜索内容分词。统计各窗口各关键词出现频次,(查看用户搜索的频次哪个最高)写入 ClickHouse。
思路分析
本程序将使用FlinkSQL 实现。分词是个一进多出的过程,需要一个UDTF 函数来实现,FlinkSQL 没有提供相关的内置函数,所以要自定义UDTF 函数。
自定义函数的逻辑在代码中实现,要完成分词功能,需要导入相关依赖,此处将借助IK 分词器完成分词。
最终要将数据写入ClickHouse,需要补充相关依赖,封装 ClickHouse 工具类和方法。本节任务分为两部分:分词处理和数据写出。
不用ES的原因:
那分词大家想到了什么呢?提到分词大家应该直接想到了es,没毛病。确实就是分词呢,我们只在es去学过。 那我要问大家那是不是这个需求,咱们用es能存吗?我告诉你用es的不行,那你想一下es分词干嘛呀? 它分词以后建索引。对吧。是他把这个词分了,但是我们现在分词要干嘛呀?我们现在分词要作词频统计,就是这个词我也拿到,然后呢,完全统计它有多少个。对吧? 你拿es来存储有什么用?他给你分词了是它给你动词,然后呢,你能拿到这个分词吗?拿不到。 对吧?所以呢,我们不能用es存储。也就是说这个分词呢。咱们得自己写。假如苹果手机对吧,看这个关键词。我把它拆分成苹果和手机两个词。
1)分词处理
分词处理分为八个步骤,如下。
(1)创建分词工具类
定义分词方法,借助IK 分词器提供的工具将输入的关键词拆分成多个词,返回一个
List 集合。
(2)创建自定义函数类
继承Flink 的TableFunction 类,调用分词工具类的分词方法,实现分词逻辑。
(3)注册函数
(4)从 Kafka 页面浏览明细主题读取数据并设置水位线
(5)过滤搜索行为
满足以下三个条件的即为搜索行为数据:
① page 字段下item 字段不为null;
② page 字段下last_page_id 为search;
③ page 字段下item_type 为keyword。
(6)分词
(7)分组、开窗、聚合计算
按照拆分后的关键词分组。统计每个词的出现频次,补充窗口起始时间、结束时间和关键词来源(source)字段。调用unix_timestamp() 函数获取以秒为单位的当前系统时间戳,转为毫秒(*1000),作为ClickHouse 表的版本字段,用于数据去重。
(8)将动态表转换为流
2**)将数据写入 **ClickHouse
(1)建表
要将数据写入ClickHouse,先要建表。首先要明确使用的表引擎。为了保证数据不重复,可以使用ReplacingMergeTree(替换合并树) 或者ReplicatedMergeTree(副本合并树),二者均可去重,区别如下。
① 副本通过对比插入的“数据块”(同一批次写入的数据)实现去重,如果插入的两批数据相似度达到 ClickHouse 的判断标准后插入的数据会被舍弃。副本的初衷是防止数据丢失,而非去重,如果重复数据夹杂在不同的数据块中并不能实现去重效果。假设向ClickHouse 写入数据时 5 条一批,第一批次 ABCDE 第二批 FAGHI,只要没有达到 ClickHouse 对数据块重复的判断标准,重复的A 依然会被写入。
② ReplacingMergeTree 在建表时需要定义版本字段,它会对比排序字段(在 ClickHouse 中排序字段可以唯一标识一行数据)相同数据的版本字段,如果设置了该字段,且多条数据的该字段值不同,则保留版本字段值最大的数据,如果没有设置该字段或者多条数据该字段的值相同,则按插入顺序保留最后一条。数据的去重只会在数据合并期间进行。合并操作会在后台一个不确定的时间执行,无法预先做出计划。因此无法保证每时每刻数据不会重复。可以执行optimize table xxx final 手动对分区进行合并。
此处选择ReplacingMergeTree,主要考虑到虽然去重有延迟,但在必要时可以通过optimize 去重。但这个命令会引发大量读写操作,对ClickHouse 而言是非常重的,极其影响性能。生产环境不可能在每次查询前都做一次合并操作,不可过多依赖optimize 去重。
(2)写出方式
调用Flink提供的JDBCSink.
Ø sql:任意的 DML 语句。
Ø statementBuilder:构造者类JDBCStatementBuilder 对象,用于为数据库操作对象(PreparedStatement 对象)中的占位符传参。核心方法accept(PreparedStatement preparedStatement, T obj),参数解读如下。
Ø preparedStatement:数据库操作对象。
Ø obj:流中数据对象。要给占位符传参,就必须将SQL 中的占位符和流中数据对应起来。然而,不同SQL 语句的占位符数量可能不同,不可能设置一个统一的数值指定占位符个数,然后简单地通过固定次数的循环完成传参。那么,如何在程序中将占位符和流中数据对应起来?可以这样做,用传入方法的流中数据对象(obj)获取类的 Class 对象,然后通过反射的方式获取所有属性的Field 对象,再调用field 对象的setObject() 方法将流中数据传递给SQL 中的占位符,完成传参。
Ø T:泛型,指定流中数据类型。
Ø executionOptions:SQL DML 语句是按照批次执行的,该参数用于设置执行参数,API 如下。
Ø withBatchIntervalMs(long intervalMs) 设置批处理时间间隔,单位毫秒。默认值为0,表示不会基于时间对批处理进行控制。
Ø withBatchSize(int size) 设置批次大小(数据的条数),默认为5000 条。
Ø withMaxRetries(int maxRetries) 设置最大重试次数,默认为3 次。
Ø 批处理触发条件(满足其一即可):
Ø 距离上次数据插入经过了withBatchIntervalMs 设置的时间间隔
Ø 数据量达到批大小
Ø Flink 检查点启动时
Ø connectionOptions:设置数据库连接参数
Ø withUrl:数据库 URL
Ø withDriverName:数据库驱动名称
Ø withUsername:连接数据库的用户名
Ø withPassword:连接数据库的密码
(3)TransientSink
在实体类中某些字段是为了辅助指标计算而设置的,并不会写入到数据库。那么,如何告诉程序哪些字段不需要写入数据库呢?Java 的反射提供了解决思路。类的属性对象Field 可以调用getAnnotation(Class annotationClass) 方法获取写在类中属性定义语句上方的注解中的信息,若注解存在则返回值不为null。定义一个可以写在属性上的注解,对于不需要写入数据库的属性,在实体类中属性定义语句上方添加该注解。为数据库操作对象传参时判断注解是否存在,是则跳过属性,即可实现对属性的排除。
图解
ClickHouse 建表语句
启动ClickHouse
systemctl start clickhouse
systemctl start clickhouse-server
clickhouse-client -m
create database gmall_rebuild;drop table if exists dws_traffic_source_keyword_page_view_window;create table if not exists dws_traffic_source_keyword_page_view_window(`stt` DateTime,`edt` DateTime,`source` String,`keyword` String,`keyword_count` UInt64,`ts` UInt64) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt, source, keyword);
代码编写
(1)IK 分词相关依赖
<dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency>
(2)IK 分词工具类KeywordUtil
(3)FlinkSQL 用户自定义函数 KeywordUDTF
(4)实体类KeywordBean
(5)补充ClickHouse 相关依赖
<dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.3.0</version><exclusions><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></exclusion></exclusions></dependency>
(6)在GmallConfig 常量类中补充常量
(7)ClickHouse 工具类
(8)TransientSink 注解
(9)主程序
测试
启动Zookeeper,Kafka,Flume (f1)
修改application.yml 日期 (改成当日)
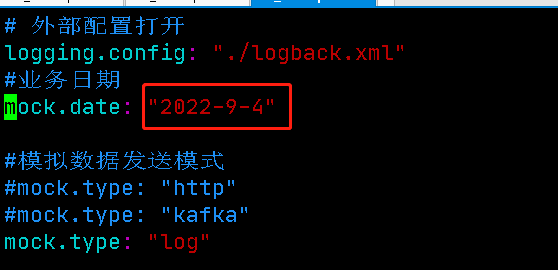
修改之后分发
启动 BaseLogApp 和 DwsTrafficSourceKeywordPageViewWindow 类
启动脚本
查看数据
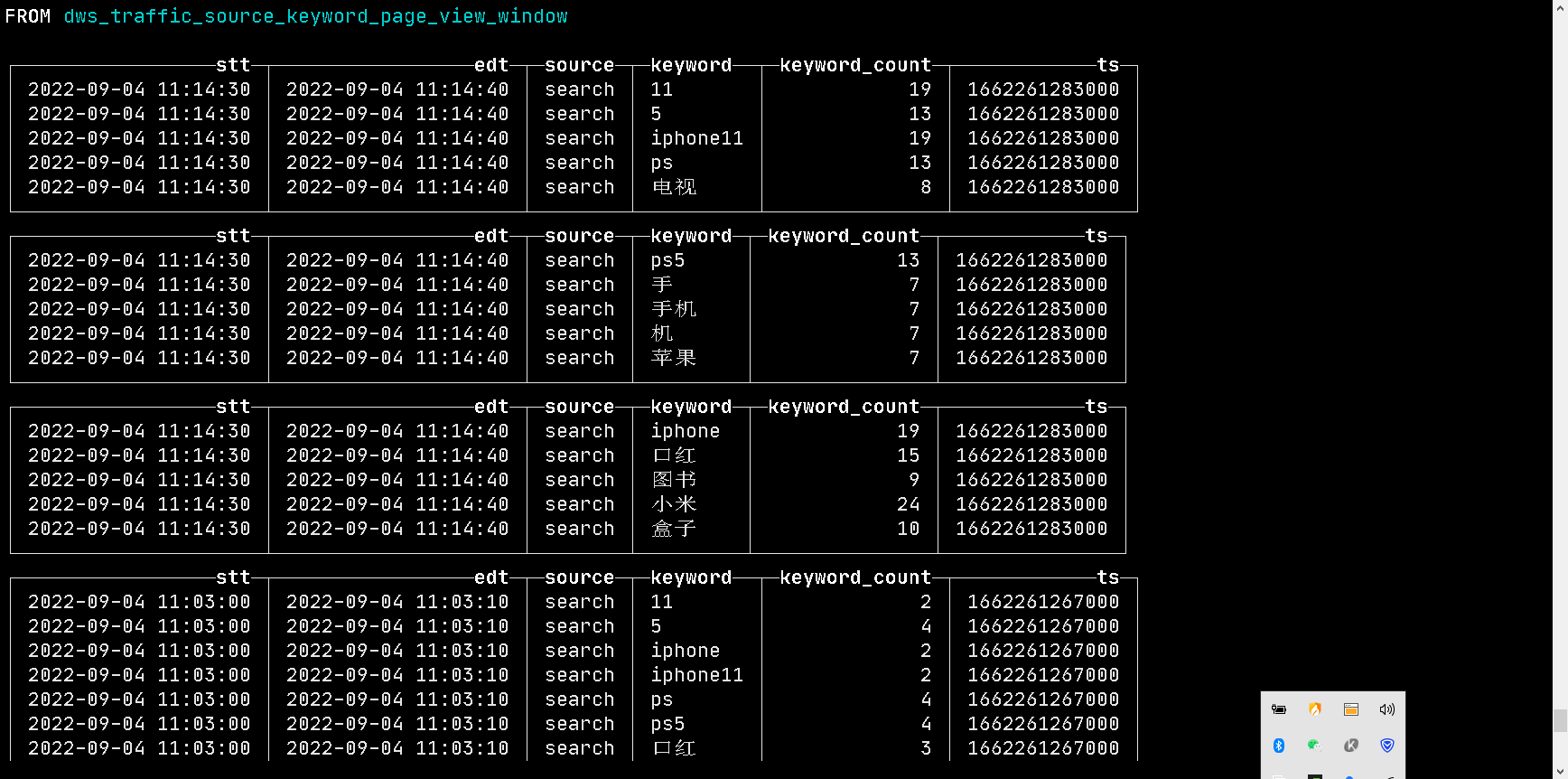
有如上图数据,则程序成功!

若有收获,就点个赞吧
0 人点赞
